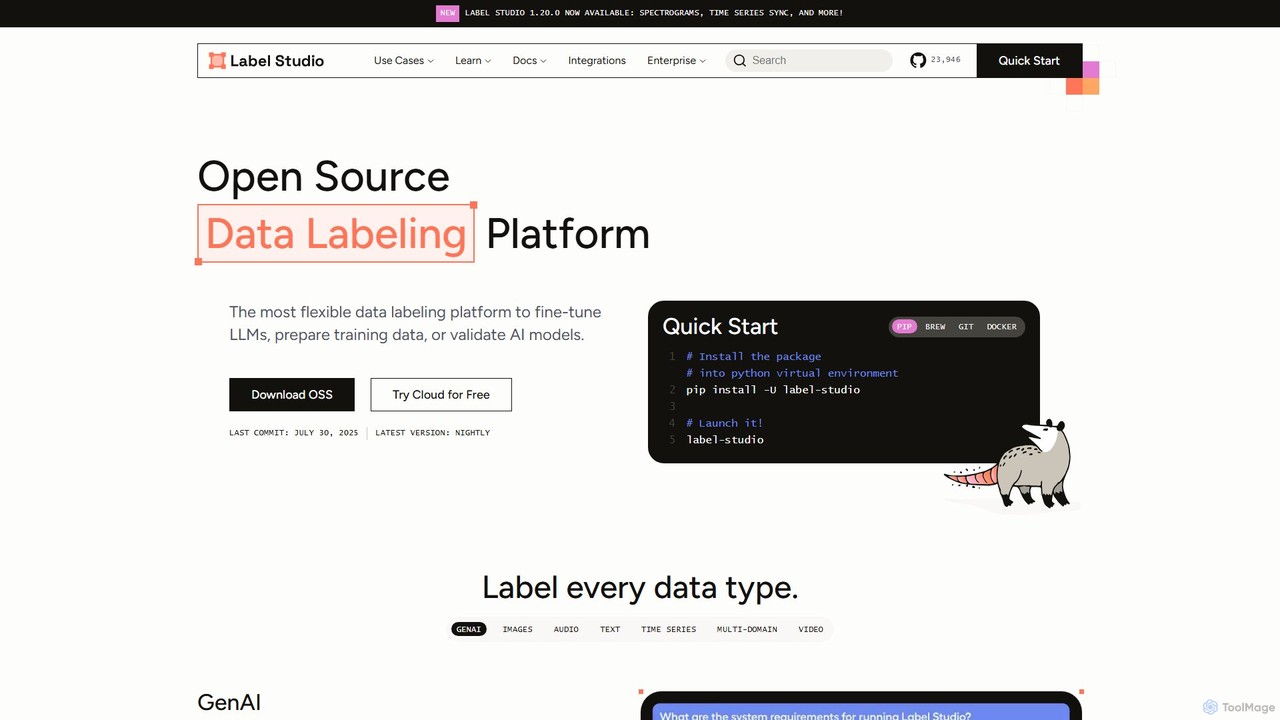
Label Studio
Label Studio ist eine vielseitige Open-Source-Plattform zur Datenkennzeichnung, die für eine breite Palette von Datentypen entwickelt wurde. Sie …
Label Studio ist eine vielseitige Open-Source-Plattform zur Datenkennzeichnung, die für eine breite Palette von Datentypen entwickelt wurde. Sie ermöglicht es Benutzern, Bilder, Texte, Audio, Video und Zeitreihendaten zu annotieren, um LLMs zu verfeinern, Trainingsdaten für maschinelles Lernen vorzubereiten und KI-Modelle mit menschlichem Feedback im Kreislauf zu validieren.
Über Trainingsdaten
Trainingsdaten-Tools sind spezialisierte KI-gestützte Plattformen, die darauf ausgelegt sind, hochwertige Datensätze zu sammeln, zu annotieren und vorzubereiten, die für die Entwicklung und Verfeinerung von Machine-Learning-Modellen unerlässlich sind. Diese Tools optimieren die entscheidende Anfangsphase der KI-Modellentwicklung, indem sie sicherstellen, dass Daten präzise beschriftet und formatiert werden. Sie ermöglichen es KI-Praktikern, robuste Modelle zu erstellen, die in verschiedenen Anwendungen, von der Computer Vision bis zur Verarbeitung natürlicher Sprache, zuverlässig funktionieren.
Kernfunktionen
- Datenerfassung & -beschaffung: Erleichtert das Sammeln vielfältiger und relevanter Rohdaten aus verschiedenen Quellen.
- Datenannotation & -beschriftung: Bietet Schnittstellen und KI-gestützte Funktionen zum präzisen Taggen, Kategorisieren und Segmentieren von Daten.
- Datenerweiterung (Data Augmentation): Generiert synthetische Daten oder modifiziert bestehende Daten, um die Größe und Vielfalt des Datensatzes zu erhöhen.
- Qualitätssicherung & -validierung: Implementiert Mechanismen zur Überprüfung der Annotationsgenauigkeit und Datenkonsistenz.
- Datenversionierung & -management: Verfolgt Änderungen an Datensätzen und gewährleistet Reproduzierbarkeit und kollaborative Workflows.
Anwendungsfälle
Diese Tools sind für KI-Forscher, Datenwissenschaftler und Machine-Learning-Ingenieure unverzichtbar. Sie werden verwendet, um Datensätze für das Training von Computer-Vision-Modellen zur Objekterkennung, zur Annotation von Text für das Verständnis natürlicher Sprache oder zur Beschriftung von Sensordaten für autonome Fahrsysteme vorzubereiten. Ziel ist es, Rohinformationen in strukturierte, nutzbare Formate für die Modelleingabe umzuwandeln.
Auswahlkriterien
Bei der Auswahl einer Trainingsdatenplattform sollten Sie die Arten der zu verarbeitenden Daten (Bilder, Text, Audio, Video), die Komplexität der Annotationsaufgaben und die Skalierbarkeitsanforderungen für große Datensätze berücksichtigen. Bewerten Sie die Integrationsfähigkeiten mit bestehenden ML-Pipelines, den Grad der für die Annotation angebotenen Automatisierung und die Robustheit der Qualitätskontrollfunktionen. Preismodelle und die Unterstützung kollaborativer Workflows sind ebenfalls wichtige Faktoren.
TrainingsdatenAnwendungsfälle
Bilder für Computer-Vision-Modelle annotieren
Ein Machine-Learning-Ingenieur muss ein Objekterkennungsmodell für autonome Fahrzeuge trainieren. Er verwendet eine Trainingsdatenplattform, um Tausende von Bildern präzise mit Bounding Boxes um Fußgänger, Fahrzeuge und Verkehrsschilder zu versehen. Diese detaillierte Annotation stellt sicher, dass das Modell Objekte in realen Fahrszenarien genau identifiziert und lokalisiert, was für Sicherheit und Leistung entscheidend ist.
Textdaten für die Verarbeitung natürlicher Sprache vorbereiten
Ein Datenwissenschaftler entwickelt ein NLP-Modell zur Stimmungsanalyse von Kundenbewertungen. Er nutzt Trainingsdaten-Tools, um Textdaten zu annotieren und Sätze oder Phrasen als positiv, negativ oder neutral zu kategorisieren. Dieser Prozess beinhaltet die Identifizierung wichtiger Entitäten und Beziehungen innerhalb des Textes, wodurch das Modell den emotionalen Ton des Kundenfeedbacks genau verstehen und klassifizieren kann.
Generierung synthetischer Daten für seltene Szenarien
In Branchen wie dem Gesundheitswesen oder dem Finanzwesen sind reale Daten für seltene, aber kritische Ereignisse (z. B. spezifische Krankheitsausbrüche, Betrugsmuster) knapp. Dateningenieure verwenden Trainingsdaten-Tools mit Augmentierungsfunktionen, um synthetische Daten zu generieren, die diese seltenen Szenarien nachahmen. Dies erweitert den Datensatz und ermöglicht es KI-Modellen, in einem umfassenderen Spektrum von Situationen trainiert zu werden, wodurch ihre Fähigkeit zur Erkennung und Reaktion auf Anomalien verbessert wird.
Audio für Spracherkennung transkribieren und annotieren
Ein Unternehmen, das einen Sprachassistenten entwickelt, benötigt hochwertige Audiodaten für das Training. Es setzt Trainingsdaten-Tools ein, um gesprochene Sprache in Text zu transkribieren und spezifische Elemente wie Sprecherwechsel, Hintergrundgeräusche oder emotionalen Ton zu annotieren. Dieser sorgfältige Prozess stellt sicher, dass das Spracherkennungsmodell vielfältige Audioeingaben präzise in Text umwandeln kann, wodurch das Verständnis und die Reaktionsfähigkeit des Assistenten verbessert werden.
Validierung und Bereinigung von Datensätzen für Modellrobustheit
Vor der Bereitstellung eines KI-Modells verwendet ein Datenqualitätsspezialist Trainingsdaten-Tools, um die vorbereiteten Datensätze zu validieren und zu bereinigen. Dies beinhaltet das Identifizieren und Korrigieren von Inkonsistenzen, das Entfernen doppelter Einträge und das Behandeln fehlender Werte. Die Sicherstellung sauberer und genauer Daten verhindert, dass das Modell fehlerhafte Muster lernt, was zu einer robusteren, faireren und zuverlässigeren KI-Systemleistung in Produktionsumgebungen führt.
Geodaten für die Umweltüberwachung vorbereiten
Umweltwissenschaftler verwenden Trainingsdaten-Tools, um Geodaten wie Satellitenbilder oder Drohnenaufnahmen für KI-Modelle zu verarbeiten und zu beschriften, die Entwaldung, Stadterweiterung oder die Auswirkungen des Klimawandels überwachen. Dies beinhaltet die Segmentierung von Landbedeckungstypen, die Identifizierung spezifischer Merkmale und die Verfolgung von Veränderungen im Laufe der Zeit. Hochwertige beschriftete Geodaten sind entscheidend für die Entwicklung präziser Vorhersagemodelle für den Umweltschutz und das Ressourcenmanagement.