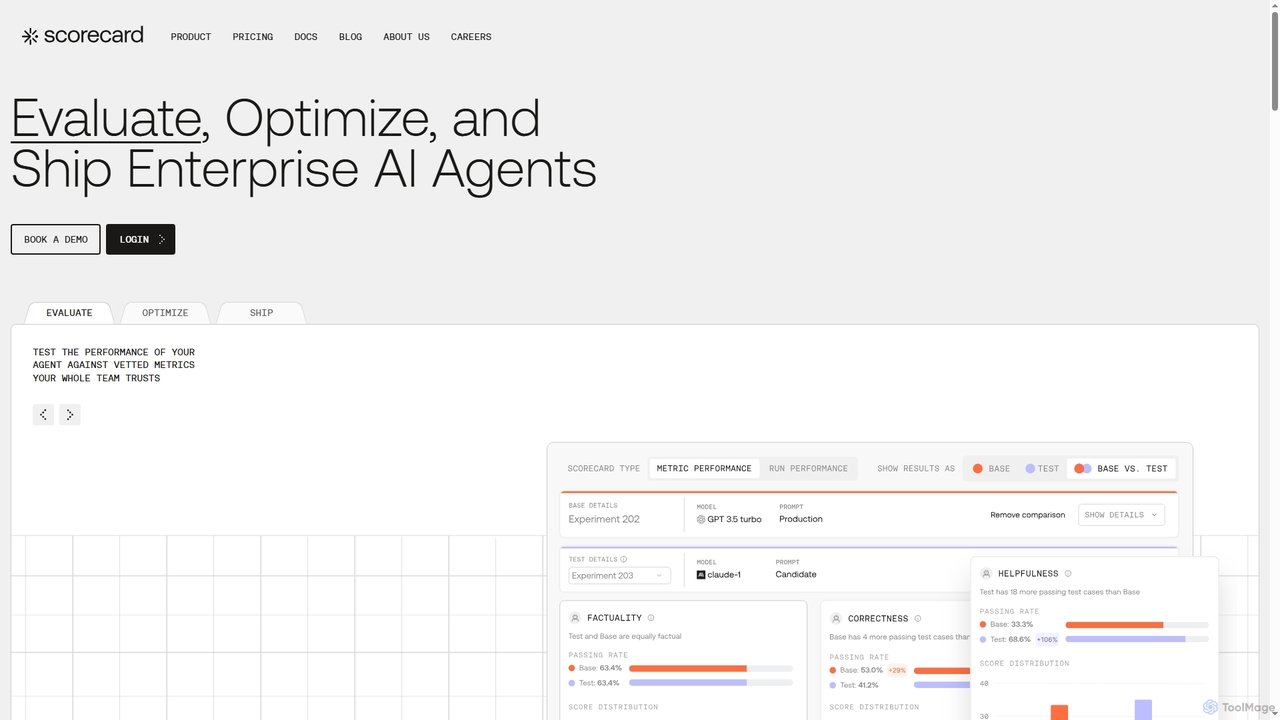
Scorecard
Scorecard ist eine End-to-End-Plattform zur Bewertung, Optimierung und Bereitstellung von Unternehmens-KI-Agenten. Sie hilft Teams, subjektive Tests durch strukturierte …
Scorecard ist eine End-to-End-Plattform zur Bewertung, Optimierung und Bereitstellung von Unternehmens-KI-Agenten. Sie hilft Teams, subjektive Tests durch strukturierte Bewertungen zu ersetzen, und bietet Werkzeuge für kontinuierliche Überwachung, Prompt-Management und Leistungsmetriken, um vertrauenswürdige und zuverlässige KI-Anwendungen mit Zuversicht zu erstellen.
Über Bewertung
Evaluierungstools sind KI-gestützte Lösungen, die entwickelt wurden, um die Leistung, Fairness und Robustheit von KI-Modellen systematisch zu bewerten. Diese Tools nutzen verschiedene Metriken, Testdatensätze und Analyseframeworks, um tiefe Einblicke in das Modellverhalten zu geben. Ihr Hauptzweck ist es, sicherzustellen, dass Modelle vor und nach der Bereitstellung zuverlässig, genau und ethisch einwandfrei sind, und spielen eine kritische Rolle im gesamten Lebenszyklus des KI-Modellmanagements.
Kernfunktionen
- Berechnung von Leistungsmetriken: Quantifiziert die Genauigkeit, Präzision, den Recall, den F1-Score und andere relevante Metriken des Modells.
- Bias-Erkennung und -Minderung: Identifiziert und misst algorithmische Verzerrungen über verschiedene demografische Gruppen oder Datensegmente hinweg.
- Robustheitstests: Bewertet die Stabilität und Widerstandsfähigkeit des Modells gegenüber adversariellen Angriffen oder unerwarteten Datenverschiebungen.
- Erklärbarkeits (XAI)-Integration: Bietet Einblicke, warum ein Modell eine bestimmte Vorhersage getroffen hat, und erhöht die Transparenz.
- Modellversionsvergleich: Vergleicht die Leistung verschiedener Modelliterationen oder -versionen, um Verbesserungen zu verfolgen.
Anwendungsfälle
KI-Modell-Evaluierungstools sind in verschiedenen Phasen des KI-Lebenszyklus unerlässlich. Datenwissenschaftler nutzen sie für eine rigorose Validierung vor der Bereitstellung, um sicherzustellen, dass neue Modelle Leistungsbenchmarks erfüllen. MLOps-Teams verlassen sich auf sie für die kontinuierliche Überwachung bereitgestellter Modelle, um Leistungsdrift oder Datenqualitätsprobleme zu erkennen. Darüber hinaus nutzen Forscher und Entwickler diese Tools, um verschiedene Modellarchitekturen zu vergleichen und ihre KI-Lösungen zu optimieren.
Auswahlkriterien
Die Auswahl eines KI-Modell-Evaluierungstools erfordert die Berücksichtigung mehrerer Faktoren. Priorisieren Sie Tools, die eine umfassende Palette von Bewertungsmetriken unterstützen, die für Ihren Modelltyp und Ihre Geschäftsziele relevant sind. Achten Sie auf starke Integrationsfähigkeiten mit Ihren bestehenden MLOps-Pipelines und Datenquellen. Skalierbarkeit, Erklärbarkeitsfunktionen und robuste Berichtsfunktionen sind ebenfalls entscheidend für eine effektive Modellgovernance und Compliance.
BewertungAnwendungsfälle
Modellvalidierung vor der Bereitstellung
Datenwissenschaftler nutzen Evaluierungstools, um neue KI-Modelle, wie z.B. ein Betrugserkennungssystem, vor der Bereitstellung rigoros gegen diverse Datensätze zu testen. Dies stellt sicher, dass das Modell Genauigkeits- und Zuverlässigkeitsbenchmarks erfüllt und potenzielle Schwachstellen oder Grenzfälle identifiziert werden, die zu kostspieligen Fehlern in der Produktion führen könnten. Der Prozess hilft, die Einsatzbereitschaft des Modells für reale Anwendungen zu validieren und Risiken zu minimieren.
Bias- und Fairness-Bewertung
KI-Ethiker und Entwickler setzen Evaluierungsplattformen ein, um systematisch Verzerrungen in Modellen, wie sie für Kreditanträge oder Einstellungen verwendet werden, zu erkennen und zu quantifizieren. Durch die Analyse von Vorhersagen über verschiedene demografische Gruppen hinweg können sie unfaire Ergebnisse identifizieren, deren Ursachen verstehen und Strategien zur Minderung diskriminierenden Verhaltens implementieren, um einen ethischen KI-Einsatz zu gewährleisten.
Kontinuierliche Leistungsüberwachung
MLOps-Ingenieure integrieren Evaluierungstools in ihre Produktionspipelines, um die Leistung bereitgestellter KI-Modelle, wie z.B. Empfehlungssysteme, kontinuierlich zu überwachen. Diese Tools verfolgen wichtige Metriken über die Zeit und alarmieren Teams bei Leistungsabfall, Daten- oder Konzeptdrift, was proaktive Eingriffe ermöglicht, um die Modellgenauigkeit und -relevanz aufrechtzuerhalten.
Vergleichende Modellauswahl
Maschinelles Lernforscher nutzen Evaluierungstools, um die Leistung mehrerer Kandidatenmodelle oder verschiedener Versionen desselben Modells zu vergleichen. Zum Beispiel können sie bei der Entwicklung eines Modells zur Verarbeitung natürlicher Sprache objektiv beurteilen, welche Architektur oder welcher Satz von Hyperparametern die besten Ergebnisse bei verschiedenen linguistischen Aufgaben liefert, und so die optimale Modellauswahl leiten.
Berichterstattung zur Einhaltung gesetzlicher Vorschriften
Unternehmen in regulierten Branchen wie Finanzen oder Gesundheitswesen nutzen Evaluierungstools, um umfassende Audit-Trails und Leistungsberichte für ihre KI-Systeme zu erstellen. Dies hilft, die Einhaltung von Industriestandards und gesetzlichen Anforderungen, wie z.B. Erklärbarkeitsmandaten oder Fairness-Richtlinien, nachzuweisen und bietet Prüfern und Stakeholdern Transparenz und Rechenschaftspflicht.
Adversarielle Robustheitstests
Sicherheitsspezialisten wenden Evaluierungstools an, um KI-Modelle, insbesondere in kritischen Anwendungen wie autonomes Fahren oder Cybersicherheit, gegen adversarielle Angriffe zu testen. Durch die Simulation bösartiger Eingaben, die darauf abzielen, das Modell zu täuschen, können sie dessen Robustheit bewerten und Schwachstellen identifizieren, wodurch die Widerstandsfähigkeit des Modells gegen ausgeklügelte Bedrohungen gestärkt und seine Zuverlässigkeit in feindlichen Umgebungen gewährleistet wird.