LLM Hub
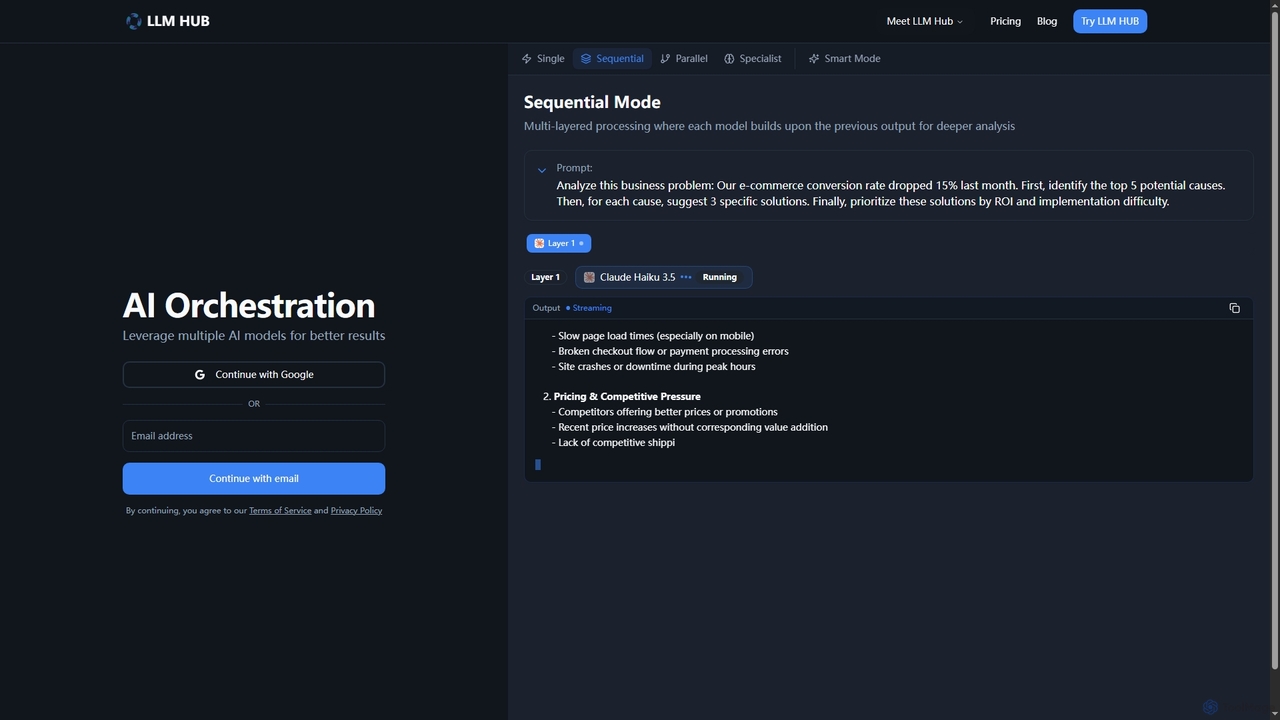
LLM Hub ist eine fortschrittliche Multi-Modell-KI-Orchestrierungsplattform, die entwickelt wurde, um die Leistungsfähigkeit von über 20 großen Sprachmodellen von …
LLM Hub ist eine fortschrittliche Multi-Modell-KI-Orchestrierungsplattform, die entwickelt wurde, um die Leistungsfähigkeit von über 20 großen Sprachmodellen von 5 großen Anbietern zu nutzen. Sie ermöglicht es Benutzern, verschiedene KI-Modelle durch sequentielle, parallele, spezialisierte und intelligente (Auto-Routing) Modi zu kombinieren und zu verketten, um tiefere Analysen und überlegene Ergebnisse bei komplexen Aufgaben zu erzielen.
Über Multimodell
Multimodale KI-Tools sind eine Klasse von Systemen, die in der Lage sind, Informationen über mehrere Datentypen wie Text, Bilder und Audio gleichzeitig zu verarbeiten, zu verstehen und zu generieren. Diese Tools nutzen einheitliche Architekturen, um den Kontext und die Beziehungen zwischen verschiedenen Modalitäten zu interpretieren und gehen über KI mit Einzelfunktionen hinaus. Dies ermöglicht es ihnen, komplexe Aufgaben wie die detaillierte Beschreibung eines Bildes oder die Erstellung eines Videos aus einem Textskript durchzuführen. Als Schlüsselkomponente in der KI-Orchestrierung fungieren sie als leistungsstarke Knoten zur Handhabung anspruchsvoller, gemischter Medien-Workflows, die menschliches Verständnis nachahmen.
Kernfunktionen
- Crossmodales Verständnis: Analysiert und korreliert Informationen aus verschiedenen Quellen, z. B. das Abgleichen einer Textbeschreibung mit spezifischem Inhalt in einem Bild oder Video.
- Multi-Input-Verarbeitung: Akzeptiert eine Kombination aus Text, Bildern, Audio oder Video als einzelne, kohärente Anweisung, um die Analyse oder Generierung zu steuern.
- Generierung gemischter Medien: Erstellt Ausgaben, die verschiedene Formate kombinieren, wie z. B. die Erstellung eines Berichts, der sowohl zusammenfassenden Text als auch illustrative Bilder enthält.
- Einheitliche Datenrepräsentation: Wandelt intern verschiedene Datentypen in einen gemeinsamen semantischen Raum um, was eine ganzheitliche Argumentation und Analyse über alle Eingaben hinweg ermöglicht.
Anwendungsfälle
Multimodale Tools werden in Branchen wie den Medien für die automatisierte Videoanalyse und Inhaltszusammenfassung, im E-Commerce für die Generierung von Produktbeschreibungen aus Bildern und in der Barrierefreiheitsentwicklung zur Erstellung von Echtzeitbeschreibungen der visuellen Welt für sehbehinderte Benutzer eingesetzt. Sie sind auch für Forscher, die komplexe, multiformatige Datensätze analysieren, von entscheidender Bedeutung.
Wie man wählt
Bei der Auswahl eines multimodalen Tools sollten Sie die spezifischen Modalitäten berücksichtigen, die es unterstützt (z. B. Text, Bild, Audio, Video). Bewerten Sie seine Leistung bei wichtigen crossmodalen Aufgaben, die für Ihre Bedürfnisse relevant sind, wie z. B. visuelle Fragenbeantwortung oder Text-zu-Bild-Generierung. Beurteilen Sie auch die einfache Integration der API, die Verarbeitungsgeschwindigkeit für große Dateien und die Kostenstruktur, die mit verschiedenen Eingabetypen verbunden ist.
MultimodellAnwendungsfälle
Intelligente Videoinhaltsanalyse
Ein Medienanalyst muss den Inhalt eines zweistündigen Dokumentarfilms schnell verstehen. Er lädt die Videodatei in ein multimodales KI-Tool hoch. Die KI transkribiert gleichzeitig den gesprochenen Dialog (Audio), identifiziert Schlüsselszenen und Objekte (Video) und erkennt Text auf dem Bildschirm (Bild). Anschließend generiert sie ein zeitgestempeltes Transkript, eine visuelle Szenenübersicht und eine prägnante Textzusammenfassung des gesamten Films. Dieser Prozess reduziert die manuelle Protokollierungszeit um über 90 % und macht den Inhalt sofort durchsuchbar.
Verbesserte E-Commerce-Produktlistung
Ein E-Commerce-Manager möchte reichhaltige Produktlistungen für eine neue Möbelserie erstellen. Er lädt mehrere Fotos eines Stuhls aus verschiedenen Blickwinkeln hoch. Die multimodale KI analysiert die Bilder, um den Stil ('Mid-Century Modern'), das Material ('Eichenholz, Leinenpolsterung') und die Merkmale ('Konische Beine, geknöpfte Rückenlehne') zu identifizieren. Basierend auf dieser visuellen Analyse generiert sie eine ansprechende, SEO-freundliche Produktbeschreibung und eine Liste relevanter Tags, was den Content-Erstellungsprozess optimiert und die Auffindbarkeit des Produkts verbessert.
Erstellung interaktiver Lehrmaterialien
Ein Pädagoge entwirft eine digitale Lektion über das Sonnensystem. Er gibt einem multimodalen Tool eine Textanweisung: 'Erstelle eine 5-Folien-Präsentation über den Mars für Fünftklässler, einschließlich wichtiger Fakten und eines Quiz.' Die KI verarbeitet den Text, generiert prägnante Beschreibungen für jede Folie, findet oder erstellt relevante Bilder der Marsoberfläche und von Rovern und komponiert sogar eine kurze Audionacherzählung für die Einleitung. Das Ergebnis ist ein reichhaltiges, multisensorisches Lernmodul, das in Minuten statt in Stunden erstellt wird.
Automatisierte Barrierefreiheitsbeschreibungen (Alt-Text)
Ein Web-Content-Manager ist dafür verantwortlich, sicherzustellen, dass eine große Nachrichten-Website für sehbehinderte Benutzer zugänglich ist. Er verwendet ein multimodales Tool, das neue Artikel scannt. Für jedes Bild analysiert die KI nicht nur den visuellen Inhalt, sondern auch den umgebenden Text (den Titel und die Bildunterschriften des Artikels), um den Kontext zu verstehen. Anschließend generiert sie automatisch sehr beschreibenden und kontextuell relevanten Alternativtext, wie z. B. 'Ein Wissenschaftler im Laborkittel zeigt auf ein Diagramm, das steigende globale Temperaturen darstellt', was weitaus nützlicher ist als ein generisches 'Person und Diagramm'-Tag.
Fortgeschrittene Unterstützung bei medizinischen Berichten
Ein Radiologe lädt das Röntgenbild eines Patienten (Bild) hoch und diktiert seine ersten Beobachtungen in ein Mikrofon (Audio). Ein multimodales KI-System verarbeitet beide Eingaben. Es analysiert das Röntgenbild auf potenzielle Anomalien und gleicht diese mit den gesprochenen Notizen des Arztes ab. Das System entwirft dann einen strukturierten medizinischen Bericht (Text), hebt die vom Radiologen genannten Problembereiche hervor und schlägt Standardterminologie vor. Dies fungiert als hochentwickelter Assistent, der Transkriptionsfehler reduziert und den Berichtsworkflow beschleunigt.
Komplexe Problemlösung im Ingenieurwesen
Ein Ingenieur lädt ein technisches Diagramm eines Maschinenteils (Bild) zusammen mit einer Textdatei hoch, die ein wiederkehrendes Leistungsproblem beschreibt. Die multimodale KI analysiert die visuelle Struktur des Diagramms, identifiziert im Text erwähnte Komponenten und korreliert das beschriebene Problem mit spezifischen Belastungspunkten oder Designmerkmalen im Diagramm. Sie kann dann einen Bericht erstellen, der potenzielle Fehlerursachen vorschlägt, wie z. B. 'Vibrationsbelastung an Verbindung C, wie durch Bruchmuster in ähnlichen Designs angezeigt', und bietet so eine wertvolle zweite Meinung zur Fehlerbehebung.