ACE Studio
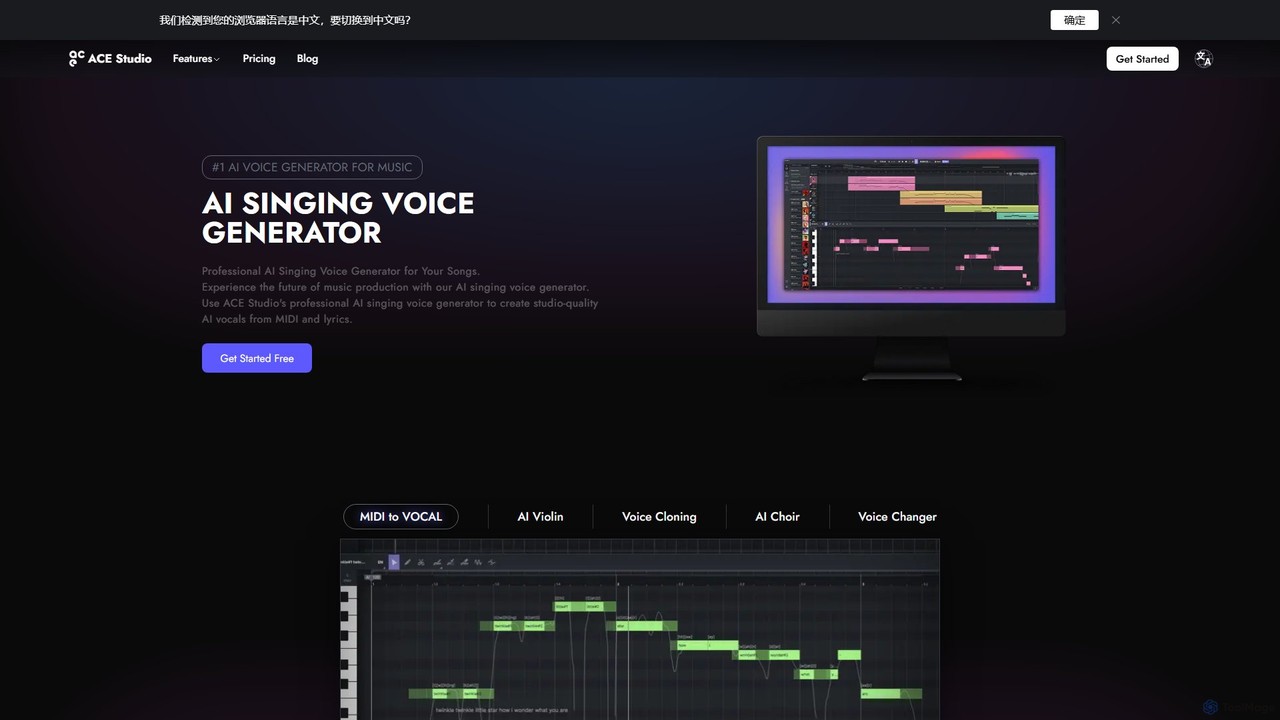
ACE Studio ist ein professioneller KI-Gesangsstimmengenerator für die Musikproduktion. Er ermöglicht es Benutzern, studiogleiche, lizenzfreie Vocals aus MIDI …
ACE Studio ist ein professioneller KI-Gesangsstimmengenerator für die Musikproduktion. Er ermöglicht es Benutzern, studiogleiche, lizenzfreie Vocals aus MIDI und Texten zu erstellen, indem sie eine Bibliothek von über 80 KI-Sängern nutzen oder ihre eigene Stimme klonen. Es bietet erweiterte Vocal-Bearbeitung, einen einzigartigen Voice-Designer, einen Stem-Splitter und eine nahtlose Integration mit DAWs über VST3/AU/AAX-Plugins.
Über Sprachsynthese
Sprachsynthese-Tools sind eine Art von KI-Sprachtechnologie, die geschriebenen Text in natürlich klingende menschliche Sprache umwandelt. Diese Tools nutzen fortschrittliche Text-zu-Sprache (TTS)-Modelle, um Audio zu erzeugen, und ermöglichen oft eine detaillierte Anpassung von Ton, Emotion und Tempo. Ihr Hauptwert liegt in der Erstellung hochwertiger, konsistenter Voiceovers für Videos, Podcasts und E-Learning, ohne dass menschliche Aufnahmen erforderlich sind. Viele fortschrittliche Plattformen unterstützen auch mehrere Sprachen und Akzente, was sie für die globale Inhaltserstellung vielseitig macht.
Kernfunktionen
- Text-zu-Sprache (TTS)-Konvertierung: Die grundlegende Fähigkeit, Texteingaben in gesprochene Audiodateien umzuwandeln.
- Stimmenbibliothek & Anpassung: Zugriff auf eine breite Palette vorgefertigter Stimmen mit Optionen zur Anpassung von Tonhöhe, Geschwindigkeit und emotionalem Ton.
- Mehrsprachige & Akzent-Unterstützung: Fähigkeit, Sprache in zahlreichen Sprachen und regionalen Akzenten für ein globales Publikum zu erzeugen.
- SSML-Unterstützung: Verwendung der Speech Synthesis Markup Language zur feingranularen Steuerung von Aussprache, Pausen und Intonation.
- API-Zugang: Ermöglicht Entwicklern, Spracherzeugungsfunktionen direkt in ihre eigenen Anwendungen und Dienste zu integrieren.
Anwendungsfälle
Sprachsynthese-Tools werden häufig von Content-Erstellern für YouTube-Video-Voiceovers, von Podcastern zur Erzeugung konsistenter Audiospuren und von Lehrdesignern zur Entwicklung von E-Learning-Modulen verwendet. Sie sind auch im Geschäftsbereich für die Erstellung professioneller interaktiver Sprachdialogsysteme (IVR) und für Entwickler, die Barrierefreiheitsfunktionen wie Screenreader für Websites und Anwendungen erstellen, von wesentlicher Bedeutung.
Wie man wählt
Bei der Auswahl eines Sprachsynthese-Tools bewerten Sie zunächst die Natürlichkeit und Qualität der angebotenen Stimmen. Berücksichtigen Sie die Breite der Sprach- und Akzentbibliothek, um sicherzustellen, dass sie den Bedürfnissen Ihres Publikums entspricht. Beurteilen Sie den Grad der verfügbaren Anpassungsmöglichkeiten für Stimmparameter wie Emotion und Tempo. Überprüfen Sie schließlich das Preismodell (z. B. pro Zeichen oder Abonnement) und prüfen Sie die API-Verfügbarkeit, falls eine Integration erforderlich ist.
SprachsyntheseAnwendungsfälle
Erstellung von Voiceovers für Videoinhalte
Videoersteller und Marketingteams benötigen oft konsistente, hochwertige Erzählungen für Tutorials, Produktdemonstrationen oder Social-Media-Anzeigen. Mit einem Sprachsynthese-Tool können sie ein Skript eingeben und eine Stimme auswählen, die zum Ton ihrer Marke passt – sei es professionell, freundlich oder energisch. Anschließend können sie das Tempo feinabstimmen und wichtige Punkte betonen. Dieser Prozess erzeugt in wenigen Minuten eine Audiospur in Studioqualität, eliminiert die Kosten und die Terminkomplexität bei der Beauftragung eines Sprechers und ermöglicht schnelle Aktualisierungen durch einfaches Bearbeiten des Textes.
Produktion von Hörbüchern und Podcasts
Autoren und Verleger können geschriebene Werke in ansprechende Hörbücher umwandeln, ohne die erhebliche Investition in ein Aufnahmestudio tätigen zu müssen. Indem sie Text Kapitel für Kapitel einfügen, können sie stundenlanges Audiomaterial erzeugen. Für Podcaster gewährleisten diese Tools eine konsistente Gastgeberstimme über alle Episoden hinweg oder ermöglichen die Erstellung unterschiedlicher Stimmen für verschiedene Segmente oder Charaktere in einem narrativen Podcast. Die Möglichkeit, Aussprachefehler leicht zu korrigieren oder Inhalte durch die Neugenerierung kleiner Textausschnitte zu aktualisieren, ist ein wesentlicher Vorteil gegenüber der herkömmlichen Aufnahme.
Entwicklung von E-Learning- und Schulungsmodulen
Lehrdesigner verwenden Sprachsynthese, um klare und zugängliche Erzählungen für Online-Kurse und Unternehmensschulungsmaterialien zu erstellen. dieser Ansatz gewährleistet eine Einheitlichkeit in Stimme und Ton über Dutzende von Modulen hinweg. Ein wesentlicher Vorteil ist die einfache Wartung; wenn ein Kurs aktualisiert werden muss, muss nur der entsprechende Text geändert und das Audio neu generiert werden. Dies ist weitaus effizienter und kostengünstiger als die Planung neuer Aufnahmesitzungen mit einem Sprecher für geringfügige Änderungen, was den gesamten Lebenszyklus des Inhalts optimiert.
Aufbau von interaktiven Sprachdialogsystemen (IVR)
Unternehmen nutzen Sprachsynthese, um professionelle und dynamische Sprachansagen für ihre automatisierten Telefonsysteme zu erstellen. Anstatt sich auf statische, vorab aufgezeichnete Nachrichten zu verlassen, kann ein Entwickler eine API verwenden, um Ansagen spontan zu generieren. Zum Beispiel kann das System kundenspezifische Informationen wie einen Bestellstatus oder einen Kontostand mit einer klaren, konsistenten Stimme vorlesen. Dies ermöglicht ein personalisierteres Kundenerlebnis und macht es viel einfacher, das IVR-System mit neuen Menüoptionen oder Werbebotschaften zu aktualisieren, ohne neue Aufnahmen zu benötigen.
Prototyping von Sprachbenutzeroberflächen (VUI)
UX/UI-Designer und App-Entwickler verwenden Sprachsynthese für das schnelle Prototyping von sprachgesteuerten Anwendungen wie intelligenten Assistenten oder Bordsystemen. Anstatt Platzhalter-Audio aufzunehmen, können sie schnell Antworten für verschiedene Benutzerbefehle und Interaktionen generieren. Dies ermöglicht es ihnen, den Gesprächsfluss, das Timing und das gesamte Benutzererlebnis frühzeitig im Designprozess auf realistische Weise zu testen. Änderungen am Dialog können sofort durch Bearbeiten des Textes vorgenommen werden, was den Iterationszyklus beschleunigt und zu einem ausgefeilteren Endprodukt führt.
Erstellung barrierefreier Inhalte für alle Benutzer
Webentwickler und Content-Publisher integrieren Sprachsynthesetechnologie, um digitale Inhalte für Benutzer mit Sehbehinderungen oder Leseschwächen zugänglich zu machen. Durch die Implementierung einer „Vorlese“-Funktion, die von einer TTS-API angetrieben wird, können Artikel, Websites und Lehrmaterialien in Echtzeit in Audio umgewandelt werden. Dies hilft nicht nur bei der Einhaltung von Barrierefreiheitsstandards wie WCAG, sondern verbessert auch das Benutzererlebnis für ein breiteres Publikum, einschließlich derjenigen, die es vorziehen, Inhalte während des Multitaskings anzuhören. Es ist eine praktische Anwendung von KI, um eine inklusivere digitale Umgebung zu fördern.