
StoryPear
StoryPear ist eine KI-gestützte Plattform zum Erstellen und Erkunden interaktiver Hörgeschichten. Entwickelt für Kinder, Eltern und Pädagogen, verwandelt …
StoryPear ist eine KI-gestützte Plattform zum Erstellen und Erkunden interaktiver Hörgeschichten. Entwickelt für Kinder, Eltern und Pädagogen, verwandelt es einfache Ideen in fesselnde Abenteuer mit vielfältigen Charakteren und verzweigten Handlungssträngen. Es ist ein Werkzeug, um die Fantasie anzuregen, das Lernen zu verbessern und das Geschichtenerzählen zu einem personalisierten, fesselnden Erlebnis für alle zu machen.
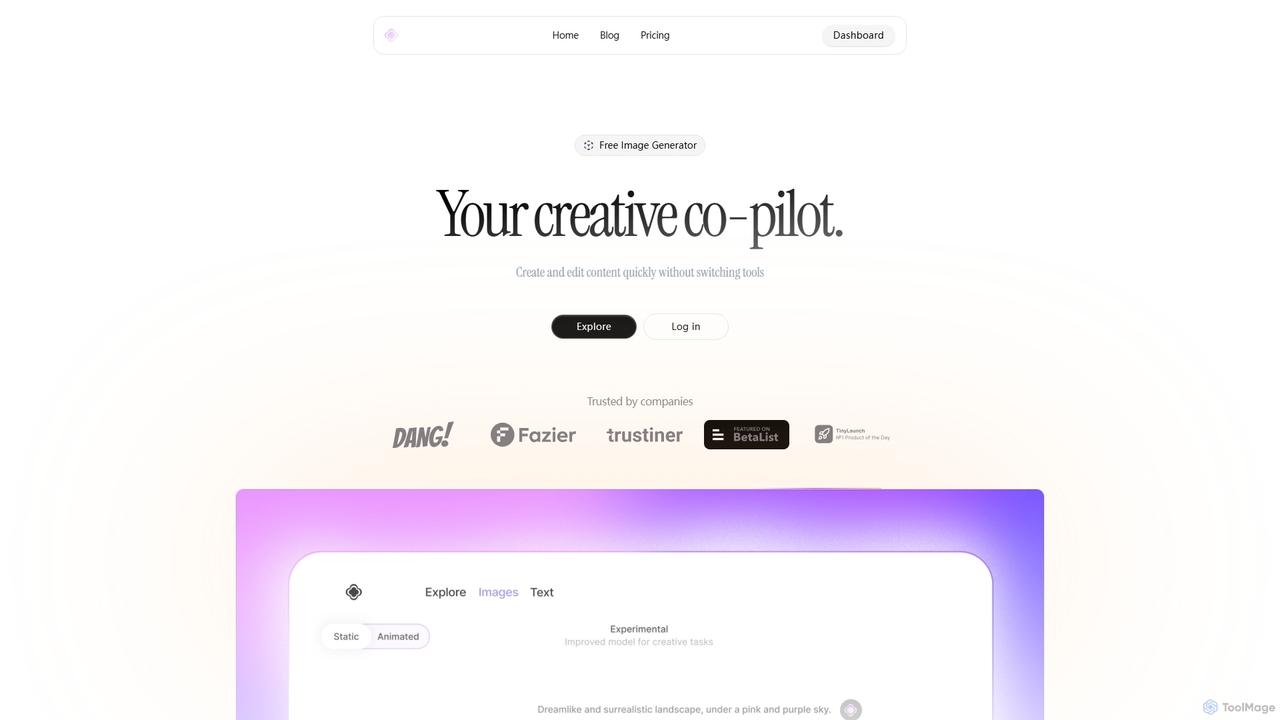
Artypa
Artypa ist Ihr kreativer Co-Pilot, eine All-in-One-KI-Plattform zur Erstellung hochwertiger Bilder, Videos, Audiodateien und Texte. Entwickelt für Kreative, …
Artypa ist Ihr kreativer Co-Pilot, eine All-in-One-KI-Plattform zur Erstellung hochwertiger Bilder, Videos, Audiodateien und Texte. Entwickelt für Kreative, Vermarkter und Marken, optimiert es den Content-Erstellungsprozess, indem es mehrere leistungsstarke KI-Tools in einer einzigen, intuitiven Benutzeroberfläche vereint. Erstellen und bearbeiten Sie Inhalte schnell, ohne zwischen verschiedenen Anwendungen wechseln zu müssen, und steigern Sie so Ihre Produktivität und Kreativität.
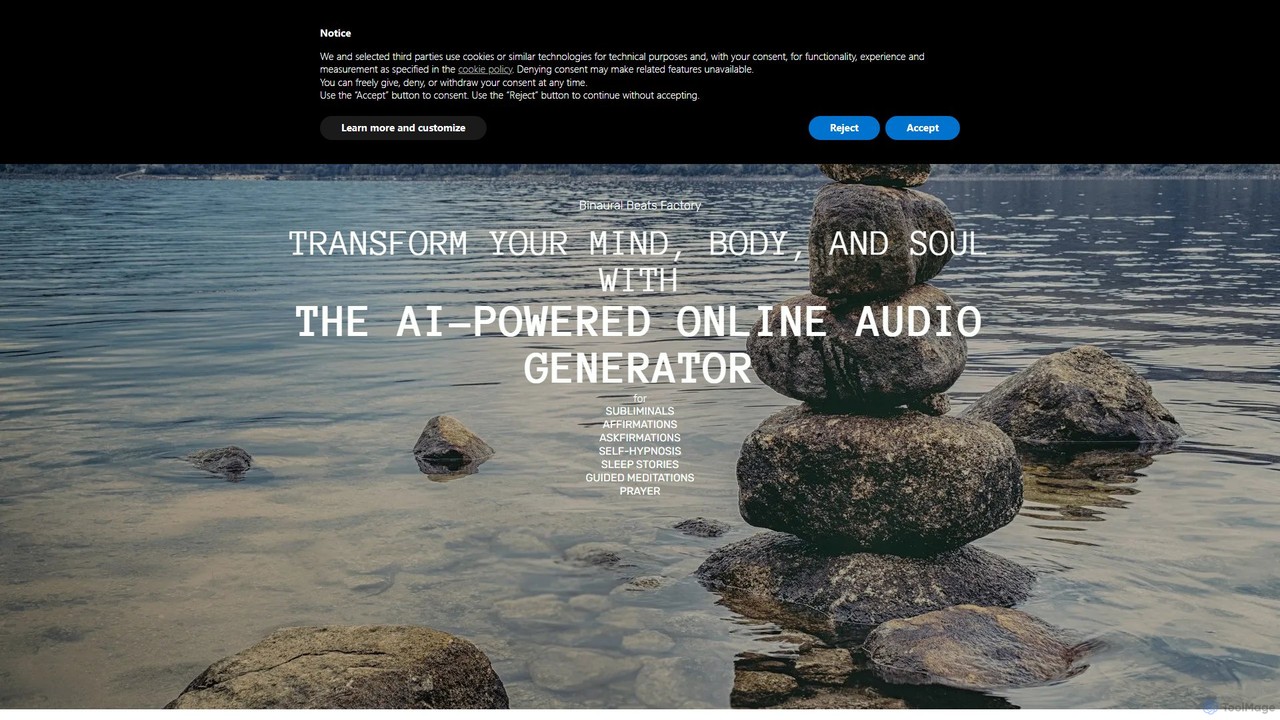
binauralbeatsfactory
Ein KI-gestützter Audiogenerator zur Erstellung personalisierter binauraler Beats, geführter Meditationen, subliminaler Affirmationen, Selbsthypnose und Schlafgeschichten. Passen Sie Audiospuren …
Ein KI-gestützter Audiogenerator zur Erstellung personalisierter binauraler Beats, geführter Meditationen, subliminaler Affirmationen, Selbsthypnose und Schlafgeschichten. Passen Sie Audiospuren an Ihre spezifischen Ziele für mentales Wohlbefinden, Fokus und persönliches Wachstum an. Kostenlos testen.
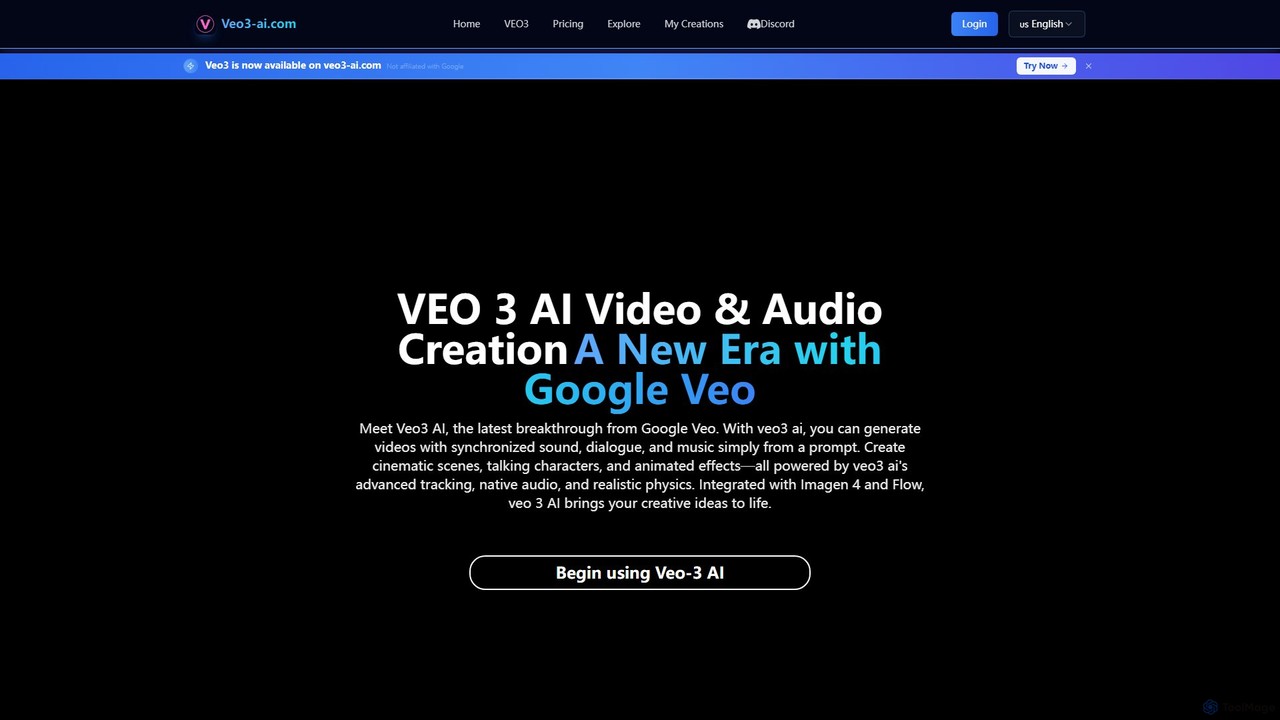
veo3_ai
veo3_ai ist eine fortschrittliche KI-Videogenerierungsplattform, die Text-Prompts und Bilder in hochwertige Videos mit synchronisiertem Audio, Dialog und Musik …
veo3_ai ist eine fortschrittliche KI-Videogenerierungsplattform, die Text-Prompts und Bilder in hochwertige Videos mit synchronisiertem Audio, Dialog und Musik umwandelt. Durch die Nutzung leistungsstarker generativer Modelle ermöglicht sie Benutzern, filmische Szenen, animierte Charaktere und dynamische Effekte mit realistischer Physik und Lippensynchronisation zu erstellen. Sie ist für Kreative, Vermarkter und Filmemacher konzipiert, die ein integriertes Werkzeug für die End-to-End-Videoproduktion suchen.
Über Audio-Generierung
Audio-Generierungstools sind eine Klasse von Software, die mithilfe künstlicher Intelligenz neue Audioinhalte von Grund auf erstellt. Sie funktionieren typischerweise durch die Interpretation von Textaufforderungen, musikalischen Notationen oder beschreibenden Eingaben, um Sprache zu synthetisieren, Musik zu komponieren oder Soundeffekte zu erzeugen. Diese Tools ermöglichen es Kreativen, Entwicklern und Unternehmen, hochwertiges, individuelles Audio für Videos, Podcasts und Anwendungen zu produzieren, ohne traditionelle Aufnahmegeräte oder musikalisches Fachwissen zu benötigen. Die Technologie reicht von hochrealistischen Text-zu-Sprache-Systemen (TTS) bis hin zu komplexen Modellen, die ganze musikalische Kompositionen in verschiedenen Stilen generieren können.
Kernfunktionen
- Text-zu-Sprache (TTS) Synthese: Wandelt geschriebenen Text in natürlich klingende menschliche Sprache in verschiedenen Stimmen, Sprachen und Akzenten um.
- Musikgenerierung: Erstellt originelle, lizenzfreie Musiktitel basierend auf Genre, Stimmung, Tempo oder beschreibenden Textaufforderungen.
- Soundeffekt (SFX) Erstellung: Generiert einzigartige Soundeffekte aus textuellen Beschreibungen, ideal für Spiele, Filme und interaktive Medien.
- Stimmklonung: Repliziert eine bestimmte Stimme aus einer kurzen Audio-Probe, um neue Sprachinhalte mit derselben Stimme zu erstellen.
- API-Zugang: Bietet programmatischen Zugriff für Entwickler, um Audio-Generierungsfunktionen direkt in ihre Anwendungen und Dienste zu integrieren.
Anwendungsfälle
Diese Tools werden von Content-Erstellern häufig zur Erzeugung von Voice-Overs und Hintergrundmusik für Videos und Podcasts verwendet. Spieleentwickler und Filmemacher nutzen sie, um schnell Prototypen zu erstellen und einzigartige Soundeffekte zu produzieren. In der Unternehmenswelt werden sie zur Erstellung von Schulungsmaterialien, Marketinginhalten und automatisierten Sprachantworten für Kundenservice-Systeme eingesetzt.
Wie man wählt
Bei der Auswahl eines Audio-Generierungstools sollten Sie den primären Ausgabetyp berücksichtigen, den Sie benötigen (Sprache, Musik oder SFX). Bewerten Sie die Audioqualität, den Realismus und den Grad der verfügbaren Anpassung (z. B. Stimm-Emotion, Musikinstrumente). Für Entwickler sind die Verfügbarkeit und Dokumentation einer API entscheidend. Überprüfen Sie auch das Preismodell und die Lizenzbedingungen für die kommerzielle Nutzung des generierten Audios.
Audio-GenerierungAnwendungsfälle
Erstellung von Voice-Overs für Marketingvideos
Ein Marketingteam muss ein Werbevideo für eine globale Kampagne erstellen, das Voice-Overs in fünf verschiedenen Sprachen erfordert. Anstatt mehrere Synchronsprecher zu engagieren und Aufnahmesitzungen zu koordinieren, was kostspielig und zeitaufwändig ist, verwenden sie ein KI-Audio-Generierungstool. Das Team gibt die übersetzten Skripte in das Tool ein, wählt für jede Sprache eine professionelle und markenkonforme Stimme aus und passt das Tempo und den Ton an. Innerhalb weniger Stunden generieren sie alle fünf hochwertigen, konsistenten Voice-Over-Spuren, was die Produktionszeit um über 90 % reduziert und die Kosten erheblich senkt.
Erstellung von benutzerdefinierter Hintergrundmusik für Inhalte
Ein YouTuber, der Videos im Dokumentarstil erstellt, benötigt einzigartige Hintergrundmusik, die zur spezifischen Stimmung jeder Szene passt – von spannend bis erhebend. Die Verwendung von lizenzfreien Musikbibliotheken führt oft zu generisch klingenden Tracks, die von anderen Kreatoren überbeansprucht werden. Durch die Verwendung eines KI-Musikgenerierungstools kann der Ersteller Anweisungen wie „dramatische Orchesterpartitur mit langsamem Tempo“ oder „fröhlicher, leichter elektronischer Track“ eingeben. Die KI generiert mehrere originelle Optionen, sodass der Ersteller das perfekte Stück auswählen kann, das sein Storytelling verbessert und sicherstellt, dass sein Inhalt zu 100 % urheberrechtsfrei ist.
Entwicklung einzigartiger In-Game-Soundeffekte
Ein Indie-Spieleentwickler erstellt ein Fantasy-Rollenspiel und benötigt eine breite Palette von Soundeffekten, von magischen Zaubersprüchen bis hin zu Monstergebrüll. Diese aus Soundbibliotheken zu beziehen, kann teuer sein und bietet möglicherweise nicht die einzigartige Audio-Identität, die sie für ihr Spiel wünschen. Mit einem KI-Soundeffekt-Generierungstool gibt der Entwickler Beschreibungen wie „knisternder Feuerzauber mit einem hohen magischen Glockenspiel“ oder „tiefes, kehliges Brüllen einer Höhlenbestie“ ein. Das Tool generiert mehrere Variationen für jede Eingabe, sodass der Entwickler schnell eine reichhaltige, benutzerdefinierte Klanglandschaft für seine Spielwelt erstellen und dabei erheblich Zeit und Budget sparen kann.
Produktion von Hörbüchern und E-Learning-Inhalten
Ein Bildungsverlag möchte seinen Katalog von Lehrbüchern in Hörbücher umwandeln, um die Zugänglichkeit für Schüler mit Sehbehinderungen und Lernschwierigkeiten zu verbessern. Sprecher für Hunderte von Büchern zu engagieren, ist nicht machbar. Sie verwenden eine KI-Text-zu-Sprache-Plattform (TTS), die natürliche, ausdrucksstarke Stimmen bietet. Durch die Integration der API der Plattform automatisieren sie den Prozess der Umwandlung ganzer Bücher in Audiodateien. Sie können verschiedene Stimmen für Erzählungen und Charakterdialoge wählen, was ein fesselndes Hörerlebnis schafft und ihre Bildungsinhalte einem viel breiteren Publikum zu einem Bruchteil der traditionellen Kosten zugänglich macht.
Prototyping von Sprachassistenten-Antworten
Ein UX-Designteam entwickelt ein neues sprachgesteuertes Smart-Home-Gerät. Sie müssen testen, wie sich verschiedene Stimmlagen – freundlich, formell, empathisch – auf die Benutzererfahrung auswirken. Anstatt für jede Iteration Dutzende von Zeilen mit einem Sprecher aufzunehmen, verwenden sie einen KI-Stimmengenerator. Die Designer können eine Antwort eingeben, sie sofort in mehreren Stimmen und emotionalen Stilen generieren und sie für Benutzertests auf ihren Prototyp laden. Dieser schnelle Iterationszyklus ermöglicht es ihnen, schnell die effektivste Stimmpersönlichkeit für ihr Produkt zu finden, den Designprozess zu verbessern und Wochen an Entwicklungszeit zu sparen.
Erstellung barrierefreier Versionen von geschriebenen Artikeln
Eine Nachrichtenorganisation möchte ihre Online-Artikel für Menschen mit Sehbehinderungen oder solche, die Inhalte lieber beim Multitasking hören, zugänglicher machen. Eine Audioversion jedes Artikels manuell aufzunehmen, ist unpraktisch. Sie implementieren ein KI-TTS-Tool über eine API auf ihrer Website. Jetzt gibt es neben jedem Artikel einen „Diesen Artikel anhören“-Button. Wenn darauf geklickt wird, wandelt das Tool den Text des Artikels sofort in einen klaren, natürlich klingenden Audiostream um. Diese Funktion erweitert nicht nur ihre Reichweite, sondern verbessert auch das Nutzerengagement, indem sie eine bequeme Alternative zum Lesen bietet.