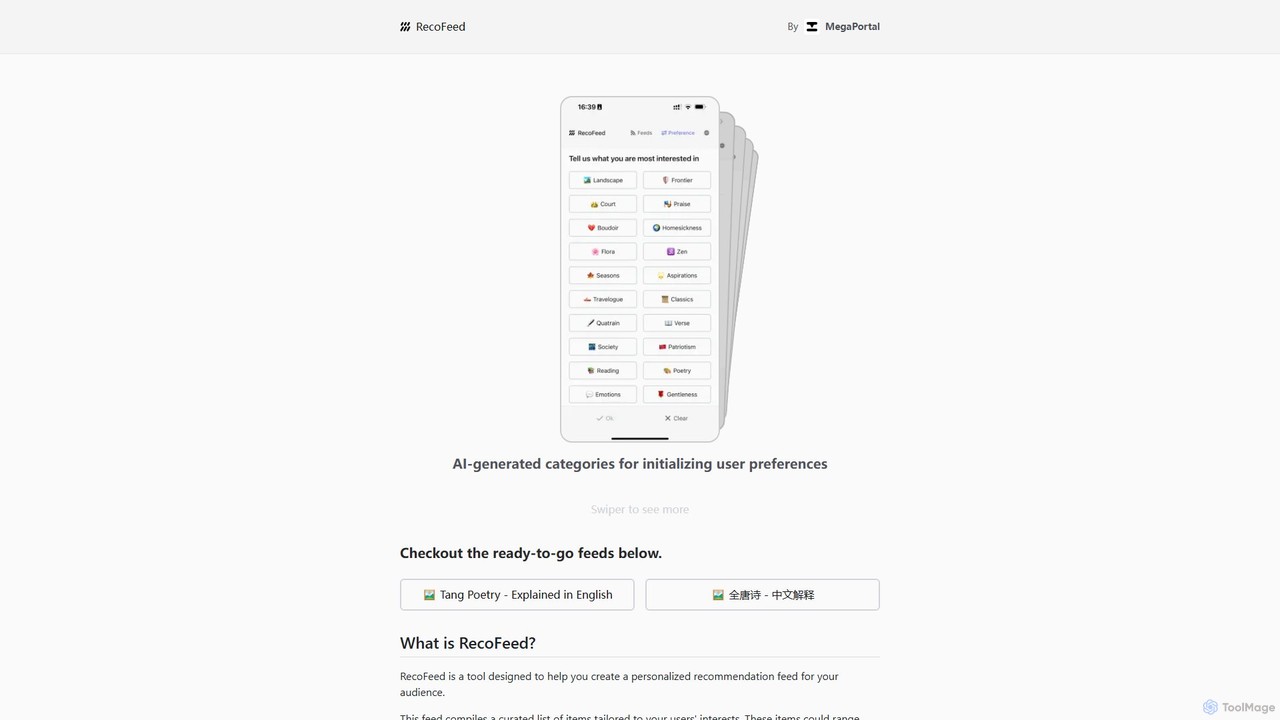
RecoFeed
RecoFeed ist ein auf Entwickler ausgerichtetes Tool zur Erstellung personalisierter Empfehlungs-Feeds. Es verwendet eine geräteinterne Vektordatenbank, CloseVector, um …
RecoFeed ist ein auf Entwickler ausgerichtetes Tool zur Erstellung personalisierter Empfehlungs-Feeds. Es verwendet eine geräteinterne Vektordatenbank, CloseVector, um Echtzeit-Vorschläge lokal auf dem Gerät des Benutzers zu generieren und so maximale Datensicherheit und geringe Latenz zu gewährleisten. Es ist für Apps und Websites in verschiedenen Sektoren wie E-Commerce, Content-Plattformen und sozialen Medien konzipiert.
Über Vektordatenbank
Eine Vektordatenbank ist ein spezialisiertes Datenbanksystem, das für die effiziente Speicherung, Verwaltung und Suche von hochdimensionalen Vektoreinbettungen konzipiert ist. Im Gegensatz zu herkömmlichen Datenbanken, die Daten anhand exakter Werte indizieren, verwenden Vektordatenbanken Algorithmen für die ungefähre nächste Nachbarsuche (Approximate Nearest Neighbor, ANN), um die ähnlichsten Elemente basierend auf ihren Vektorrepräsentationen zu finden. Diese Fähigkeit ist grundlegend für die Bereitstellung fortschrittlicher KI-Anwendungen wie semantische Suche, Empfehlungssysteme und Retrieval-Augmented Generation (RAG) für große Sprachmodelle. Sie bieten außergewöhnliche Geschwindigkeit und Skalierbarkeit für Ähnlichkeitssuchaufgaben auf massiven, unstrukturierten Datensätzen wie Text, Bildern und Audio.
Kernfunktionen
- Hochdimensionale Vektorindizierung: Organisiert Vektordaten effizient mit Algorithmen wie HNSW oder IVF für eine schnelle Abfrage.
- Ähnlichkeitssuche: Führt Suchen basierend auf Vektornähe (z. B. Kosinus-Ähnlichkeit, Euklidischer Abstand) durch, um semantisch ähnliche Elemente zu finden.
- Skalierbarkeit und Leistung: Entwickelt, um Milliarden von Vektoren und hohe Abfragelasten mit geringer Latenz zu bewältigen, was für Echtzeitanwendungen entscheidend ist.
- Metadaten-Filterung: Kombiniert die Vektor-Ähnlichkeitssuche mit traditioneller Metadaten-Filterung für präzisere und kontextbezogene Ergebnisse.
Anwendungsfälle
Vektordatenbanken sind für KI/ML-Ingenieure, Datenwissenschaftler und Entwickler unerlässlich, die Anwendungen erstellen, die das Verständnis semantischer Beziehungen in Daten erfordern. Sie werden häufig im E-Commerce für visuelle Suche und Empfehlungen, in Unternehmenssystemen für die intelligente Wissensdatenbanksuche und in der generativen KI eingesetzt, um großen Sprachmodellen sachlichen Kontext zu liefern und Ungenauigkeiten zu reduzieren.
Wie man wählt
Bei der Auswahl einer Vektordatenbank sollten Sie deren Indizierungsalgorithmen und Leistungsbenchmarks für Ihren spezifischen Datentyp bewerten. Berücksichtigen Sie das Bereitstellungsmodell – Cloud-verwaltete Dienste bieten Benutzerfreundlichkeit, während selbst gehostete Optionen mehr Kontrolle bieten. Überprüfen Sie auch die Verfügbarkeit robuster SDKs in Ihren bevorzugten Programmiersprachen und Integrationen mit beliebten KI-Frameworks wie LangChain oder LlamaIndex. Schließlich bewerten Sie die Skalierbarkeit und das Preismodell, um sicherzustellen, dass es Ihren langfristigen Anforderungen entspricht.
VektordatenbankAnwendungsfälle
KI-Chatbots mit Retrieval-Augmented Generation (RAG) betreiben
Ein KI-Entwickler hat die Aufgabe, einen Kundensupport-Chatbot zu erstellen, der präzise Antworten aus einer privaten Wissensdatenbank, wie z. B. Produkthandbüchern und internen FAQs, liefern muss. Um dies zu erreichen, werden Dokumente segmentiert, in Vektoreinbettungen umgewandelt und in einer Vektordatenbank gespeichert. Wenn ein Benutzer eine Frage stellt, wird seine Anfrage vektorisiert und zur Suche nach den relevantesten Dokumentenabschnitten in der Datenbank verwendet. Diese abgerufenen Abschnitte werden dann als Kontext an ein großes Sprachmodell (LLM) übergeben, wodurch der Chatbot präzise, kontextbezogene Antworten auf der Grundlage proprietärer Daten generieren und das Risiko von Halluzinationen erheblich reduzieren kann.
Implementierung der semantischen Suche für interne Dokumente
Ein Wissensmanager in einem großen Unternehmen muss verbessern, wie Mitarbeiter Informationen in Tausenden von internen Berichten und Richtliniendokumenten finden. Die herkömmliche Stichwortsuche ist ineffizient und kann oft konzeptionell verwandte Inhalte nicht aufdecken. Durch die Implementierung einer Vektordatenbank werden alle Dokumente vektorisiert, um ihre semantische Bedeutung zu erfassen. Mitarbeiter können nun mit natürlichsprachlichen Fragen suchen. Das System führt eine Ähnlichkeitssuche durch, um Dokumente basierend auf konzeptioneller Relevanz und nicht nur auf Stichwortübereinstimmungen abzurufen. Dies führt zu einer Verbesserung der Informationsabrufgeschwindigkeit um 80 %, was die Produktivität und den Wissensaustausch steigert.
Aufbau einer visuellen Suchmaschine für den E-Commerce
Ein E-Commerce-Entwickler für einen Online-Modehändler möchte eine „Shop the Look“-Funktion erstellen, die es Kunden ermöglicht, Produkte durch Hochladen eines Bildes zu finden. Um dies zu ermöglichen, wird der gesamte Produktbildkatalog von einem Bildverarbeitungsmodell verarbeitet, um Vektoreinbettungen zu generieren, die dann in einer Vektordatenbank gespeichert werden. Wenn ein Benutzer ein Bild hochlädt, wird es ebenfalls in einen Vektor umgewandelt. Die Datenbank führt dann eine Hochgeschwindigkeits-Ähnlichkeitssuche durch, um Produktbilder mit den nächstgelegenen Vektoren zu finden und anzuzeigen. Dieses intuitive Sucherlebnis verbessert die Produktentdeckung erheblich und hat gezeigt, dass es die Konversionsraten erhöht, indem es Kunden hilft, visuell ähnliche Artikel sofort zu finden.
Erstellung personalisierter Inhaltsempfehlungssysteme
Ein Datenwissenschaftler bei einem Medien-Streaming-Dienst zielt darauf ab, die Benutzerbindung durch die Bereitstellung hochrelevanter Inhaltsempfehlungen zu erhöhen. Sie repräsentieren jeden Inhalt (z. B. Filme, Artikel) und das Profil jedes Benutzers als hochdimensionale Vektoren. Wenn ein Benutzer mit Inhalten interagiert, wird sein Profilvektor aktualisiert. Eine Vektordatenbank wird verwendet, um Ähnlichkeitssuchen in Echtzeit durchzuführen und die Inhaltsvektoren zu finden, die dem Interessenvektor eines Benutzers am nächsten kommen. Dies ermöglicht der Plattform, dynamische, personalisierte Empfehlungen zu liefern, die sich an die sich ändernden Vorlieben des Benutzers anpassen, was zu längeren Sitzungsdauern und einer höheren Benutzerbindung führt.
Anomalieerkennung im Cybersicherheits-Netzwerkverkehr
Ein Cybersicherheitsanalyst muss potenzielle Bedrohungen in riesigen Mengen von Netzwerkverkehrsdaten in Echtzeit identifizieren. Normale Betriebsdaten wie Protokolleinträge und Netzwerkpakete werden in Vektoreinbettungen umgewandelt, um einen Basis-Cluster für „normale“ Aktivitäten im Vektorraum zu erstellen. Eine Vektordatenbank nimmt kontinuierlich neue Daten auf, wandelt sie in Vektoren um und vergleicht sie mit dieser Basis. Jeder Datenpunkt, dessen Vektor weit vom normalen Cluster abweicht, wird sofort als Anomalie gekennzeichnet. Dieser Ansatz ermöglicht die schnelle Erkennung von Zero-Day-Bedrohungen oder Systemausfällen, die nicht mit bekannten Signaturen übereinstimmen, und bietet eine entscheidende Ebene proaktiver Sicherheit.
Deduplizierung von großen Bilddatensätzen
Ein Ingenieur für maschinelles Lernen bereitet einen riesigen Bilddatensatz vor, um ein Computer-Vision-Modell zu trainieren. Um die Datenqualität zu gewährleisten und Modellverzerrungen zu vermeiden, ist es entscheidend, doppelte oder nahezu doppelte Bilder zu entfernen. Jedes Bild im Datensatz wird in eine Vektoreinbettung umgewandelt und in einer Vektordatenbank indiziert. Der Ingenieur führt dann für jedes Bild eine Ähnlichkeitssuche durch, um andere Bilder innerhalb eines sehr kleinen Abstandsschwellenwerts zu finden. Dieser Prozess identifiziert und markiert effizient alle Sätze von nahezu doppelten Bildern zur Entfernung, was zu einem saubereren, vielfältigeren Trainingsdatensatz führt. Dies verbessert die Genauigkeit und die Generalisierungsfähigkeiten des endgültigen Modells.