RecurseChat
RecurseChat ist ein leistungsstarker, datenschutzorientierter KI-Client für macOS. Er arbeitet lokal-first und ermöglicht es Ihnen, auch offline mit …
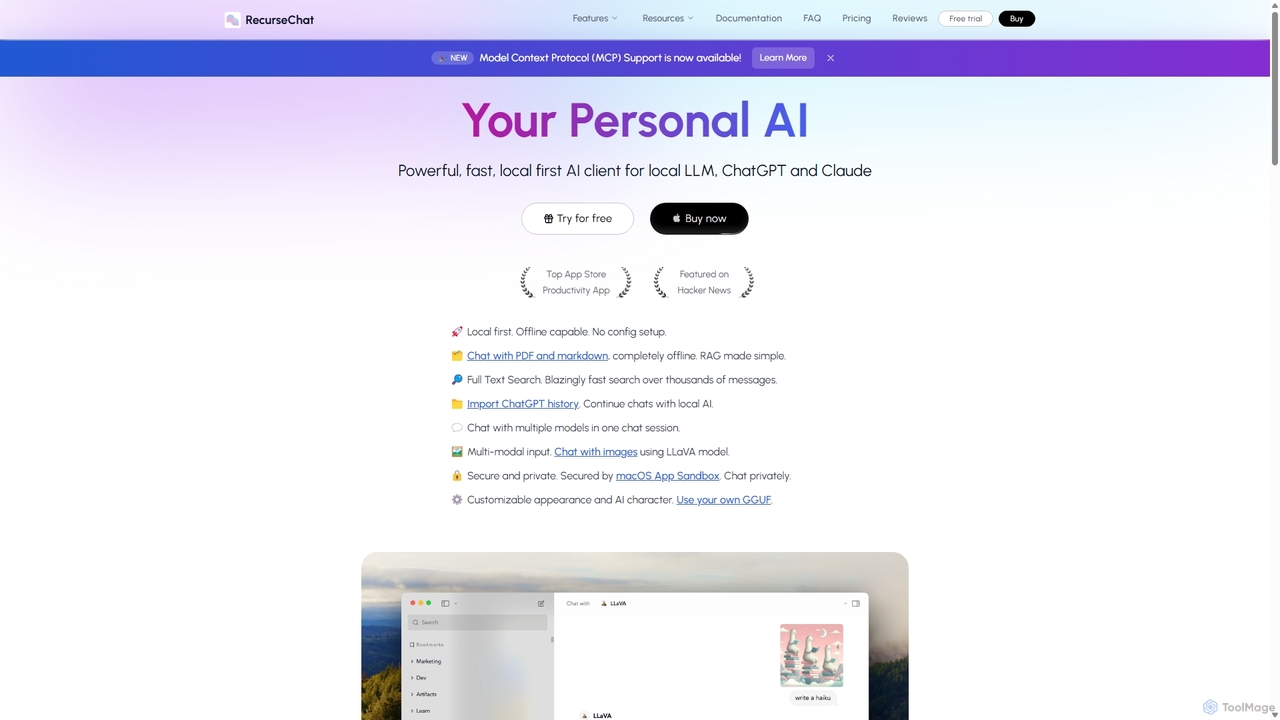
RecurseChat ist ein leistungsstarker, datenschutzorientierter KI-Client für macOS. Er arbeitet lokal-first und ermöglicht es Ihnen, auch offline mit lokalen LLMs, ChatGPT und Claude zu chatten. Interagieren Sie sicher mit Ihren PDFs und Dokumenten auf Ihrem Gerät mithilfe der RAG-Technologie. Er bietet multimodale Eingaben, Volltextsuche und umfangreiche Anpassungsmöglichkeiten ohne Abonnement.
Über LLM-Clients
LLM-Clients sind spezialisierte Anwendungen, die eine einheitliche grafische Benutzeroberfläche für die Interaktion mit verschiedenen Großen Sprachmodellen (LLMs) bieten. Diese Tools fungieren als zentraler Hub, der die Komplexität von API-Aufrufen abstrahiert und erweiterte Funktionen zur Verwaltung von Prompts, Konversationen und Modelleinstellungen bietet. Sie sind für Entwickler, Forscher und Power-User konzipiert, um verschiedene LLMs effizient zu testen, zu vergleichen und zu iterieren, ohne für jede Interaktion Code schreiben zu müssen. Im Gegensatz zur direkten API-Nutzung steigern LLM-Clients die Produktivität durch Funktionen wie Konversationsverlauf, Prompt-Bibliotheken und den direkten Vergleich von Modellen.
Kernfunktionen
- Multi-Modell-Unterstützung: Verbinden und wechseln Sie zwischen verschiedenen LLMs von Anbietern wie OpenAI, Anthropic, Google und lokalen Modellen über eine einzige Oberfläche.
- Prompt-Management: Erstellen, speichern, organisieren und wiederverwenden Sie Prompts oder Prompt-Vorlagen für konsistente und effiziente Arbeitsabläufe.
- Konversationsverlauf: Speichern, suchen und verwalten Sie vergangene Interaktionen mit verschiedenen Modellen zur einfachen Referenz und Kontextkontinuität.
- Parametersteuerung: Passen Sie Modellparameter wie Temperatur, Top-p und maximale Token visuell an, um die KI-Antworten fein abzustimmen.
- Integration lokaler LLMs: Unterstützung für die Verbindung mit lokal gehosteten Modellen (z. B. über Ollama, LM Studio), um Datenschutz und Offline-Zugriff zu gewährleisten.
Anwendungsfälle
LLM-Clients werden häufig von Entwicklern für das schnelle Prototyping von KI-Funktionen, von Forschern zum Vergleich des Modellverhaltens und von Content-Erstellern zur Generierung verschiedener Textformate verwendet. Sie sind besonders wertvoll in Arbeitsabläufen, die eine häufige Interaktion mit mehreren Modellen oder systematische Prompt-Tests erfordern, wie z. B. beim Prompt-Engineering und bei vergleichenden Analysen.
Wie man wählt
Bei der Auswahl eines LLM-Clients sollten Sie die Bandbreite der unterstützten Modelle (sowohl Cloud als auch lokal), die Plattformverfügbarkeit (Windows, macOS, Linux, Web) und die Robustheit der Prompt-Management-Funktionen berücksichtigen. Bewerten Sie auch die Benutzeroberfläche hinsichtlich der Workflow-Effizienz und überprüfen Sie die Datenschutzrichtlinien, insbesondere wenn Sie planen, sensible Informationen zu verwenden. Für Teams können auch Kollaborationsfunktionen ein entscheidender Faktor sein.
LLM-ClientsAnwendungsfälle
Schnelles Prototyping für KI-Anwendungen
Ein KI-Entwickler muss das beste Sprachmodell für eine neue Chatbot-Funktion auswählen. Anstatt für jede API separate Integrationsskripte zu schreiben, verwendet er einen LLM-Client. Er sendet denselben Test-Prompt gleichzeitig an GPT-4, Claude 3 und Llama 3. Der Client zeigt die Antworten nebeneinander an, sodass der Entwickler sofort die Antwortqualität, den Ton, die Formatierung und die Latenz vergleichen kann. Dieser Prozess beschleunigt die Entscheidungsfindung, reduziert die Entwicklungszeit von Stunden auf Minuten und stellt sicher, dass das optimale Modell für die benutzerseitige Funktion ausgewählt wird.
Vergleichende Content-Erstellung für das Marketing
Ein Content-Marketer hat die Aufgabe, Werbetexte für eine neue Kampagne zu erstellen. Mit einem LLM-Client erstellt er eine Prompt-Vorlage mit Produktdetails und Zielgruppeninformationen. Anschließend führt er diese Vorlage auf drei verschiedenen Modellen aus, die für ihre kreativen Schreibfähigkeiten bekannt sind. Innerhalb von Sekunden erhält er Dutzende von Variationen. Er kann die überzeugendsten Optionen leicht überprüfen, bewerten und auswählen, was den kreativen Brainstorming-Prozess erheblich beschleunigt und eine breitere Palette hochwertiger Texte für A/B-Tests bereitstellt.
Akademische Forschung zum Verhalten von LLMs
Ein KI-Forscher untersucht, wie verschiedene Modelle mit logischen Trugschlüssen in Prompts umgehen. Er verwendet einen LLM-Client, um einen Datensatz von 100 Prompts, die Trugschlüsse enthalten, systematisch an fünf verschiedene Modelle zu senden, einschließlich eines lokal gehosteten Open-Source-Modells. Die Konversationsverlaufsfunktion des Clients ermöglicht es ihm, alle Interaktionen nach Modell und Prompt geordnet zu halten. Er kann die vollständigen Protokolle problemlos als strukturierte Daten (z. B. JSON oder CSV) für die quantitative Analyse in seiner Forschungssoftware exportieren und so die Datenerfassungsphase seiner Studie optimieren.
Aufbau einer persönlichen Prompt-Bibliothek
Ein Prompt-Ingenieur verwendet täglich einen LLM-Client, um Prompts für verschiedene Aufgaben zu erstellen und zu verfeinern. Er nutzt die Prompt-Management-Funktion des Clients, um eine strukturierte Bibliothek zu erstellen. Prompts für die 'Codegenerierung' werden entsprechend getaggt, während Prompts für die 'Zusammenfassung' in einem separaten Ordner gespeichert werden. Für jeden Prompt fügt er Notizen hinzu, mit welchem Modell er am besten funktioniert und welche die optimale Temperatureinstellung ist. Dies verwandelt den Client in eine persönliche Wissensdatenbank, die es ihm ermöglicht, sofort auf hochwirksame, vorab getestete Prompts zuzugreifen und diese einzusetzen, was seine tägliche Produktivität steigert.
Sichere Interaktion mit lokalen LLMs
Ein Datenwissenschaftler in einem Gesundheitsunternehmen muss sensible Patientendaten mit einem LLM analysieren. Aufgrund strenger Datenschutzbestimmungen ist das Senden dieser Daten an eine Cloud-basierte API keine Option. Er verwendet einen LLM-Client, der lokale Modelle über Ollama unterstützt. Er lädt ein spezialisiertes medizinisches LLM auf seinen lokalen Rechner und verbindet sich über den Client damit. Diese Einrichtung ermöglicht es ihm, die Leistungsfähigkeit des LLM für die Datenanalyse in einer sicheren, abgeschotteten Umgebung zu nutzen und die vollständige Einhaltung von Datenschutzstandards wie HIPAA zu gewährleisten.
Optimierung der Erstellung technischer Dokumentation
Ein technischer Redakteur ist für die Erstellung von API-Dokumentationen verantwortlich. Er verwendet einen LLM-Client, um Entwürfe für Erklärungen komplexer Funktionen zu erstellen. Er führt separate Konversationsstränge für jeden API-Endpunkt, um den Kontext klar zu halten. Indem er Code-Schnipsel eingibt und um Erklärungen in einfacher Sprache bittet, kann er klare, konsistente und genaue Entwürfe erstellen. Anschließend vergleicht er die Ausgaben eines technischen Modells (wie Code Llama) und eines allgemeinen Modells (wie GPT-4), um die beste Mischung aus technischer Genauigkeit und Lesbarkeit zu finden, was die Dokumentationsqualität verbessert und Zeit spart.