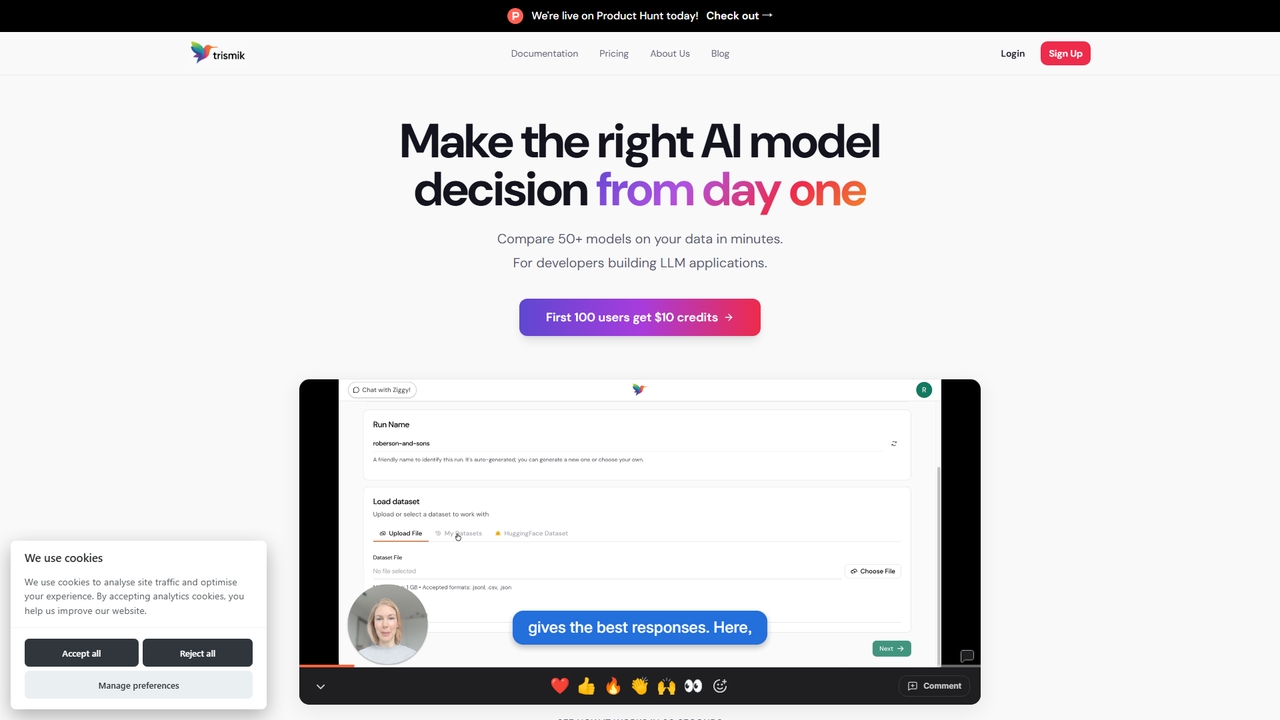
Trismik
Vergleichen Sie über 50 LLMs mit Ihren eigenen Daten in Minuten. Treffen Sie evidenzbasierte Modellentscheidungen zu Qualität, Kosten …
Vergleichen Sie über 50 LLMs mit Ihren eigenen Daten in Minuten. Treffen Sie evidenzbasierte Modellentscheidungen zu Qualität, Kosten und Geschwindigkeit.
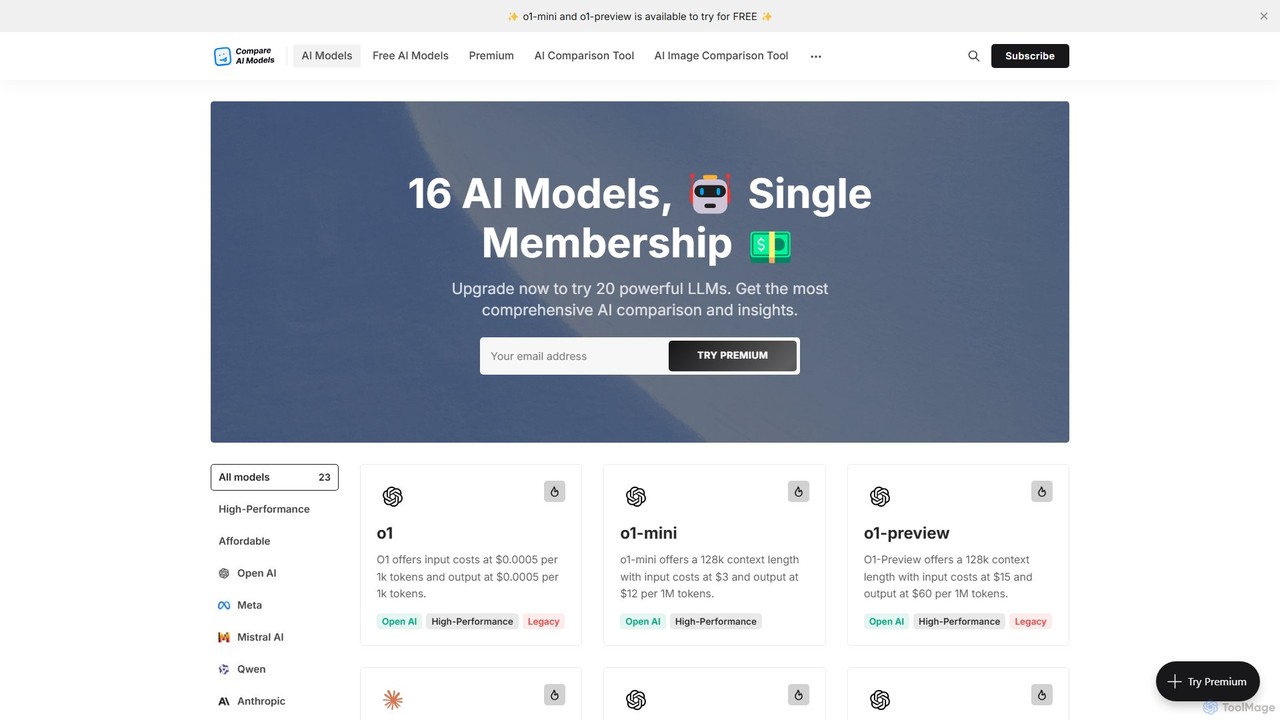
Compare AI Models
Eine umfassende Plattform zum Vergleich von über 20 führenden Large Language Models (LLMs). Sie bietet detaillierte Metriken zu …
Eine umfassende Plattform zum Vergleich von über 20 führenden Large Language Models (LLMs). Sie bietet detaillierte Metriken zu Leistung, API-Preisen, Kontextfenstern und Funktionen sowie einen kostenlosen Chat zum direkten Testen von Modellen. Ein unverzichtbares Werkzeug für Entwickler, Forscher und Unternehmen, um die perfekte KI für ihre Bedürfnisse zu finden.
Joythee AI
Joythee AI ist eine fortschrittliche Konversations-KI-Plattform, die es Ihnen ermöglicht, gleichzeitig mit mehreren KI-Agenten zu chatten. Vergleichen Sie …
Joythee AI ist eine fortschrittliche Konversations-KI-Plattform, die es Ihnen ermöglicht, gleichzeitig mit mehreren KI-Agenten zu chatten. Vergleichen Sie Antworten von verschiedenen LLMs in einer einzigen Oberfläche, genießen Sie personalisierte Gespräche und schützen Sie Ihre Privatsphäre mit einem Inkognito-Modus. Ideal für Einzelpersonen, Teams und Unternehmen, die ihre Produktivität und Kreativität steigern möchten.
Über Modellvergleich
Modellvergleichs-Tools sind spezialisierte Plattformen innerhalb des Entwickler-Toolkits, die dazu dienen, die Leistung verschiedener KI-Modelle systematisch zu bewerten, zu benchmarken und zu vergleichen. Diese Tools bieten eine strukturierte Umgebung, um Modelle wie LLMs oder Bildgeneratoren mit denselben Eingaben und Datensätzen auszuführen und ihre Ergebnisse objektiv zu messen. Sie sind entscheidend für datengestützte Entscheidungen und ermöglichen es Entwicklern und Forschern, das genaueste, kostengünstigste und effizienteste Modell für eine bestimmte Anwendung auszuwählen. Durch die Bereitstellung von Side-by-Side-Analysen und quantitativen Metriken optimieren sie den ansonsten komplexen und zeitaufwändigen Prozess der Modellauswahl.
Kernfunktionen
- Side-by-Side-Playground: Vergleichen Sie sofort die Ausgaben mehrerer Modelle für denselben Prompt in einer einheitlichen Oberfläche.
- Automatisiertes Benchmarking: Führen Sie standardisierte Branchen-Benchmarks (z. B. MMLU, HumanEval) durch, um Modelle nach verschiedenen Fähigkeiten zu bewerten.
- Kosten- und Latenzanalyse: Verfolgen und vergleichen Sie die finanziellen Kosten und die Antwortzeit für die Inferenz jedes Modells.
- Qualitative Bewertung: Erleichtern Sie menschliches Feedback und Bewertungen nach subjektiven Kriterien wie Kohärenz, Stil oder Sicherheit.
- Versionskontrolle & Verlauf: Protokollieren und verfolgen Sie Bewertungsexperimente im Laufe der Zeit, um Leistungsänderungen und Regressionen zu überwachen.
Anwendungsfälle
Diese Tools sind für KI-Entwickler, MLOps-Ingenieure und Produktmanager während des Entwicklungs- und Wartungslebenszyklus von entscheidender Bedeutung. Sie werden bei der Auswahl eines Basismodells für eine neue Funktion, der Bewertung der Auswirkungen des Fine-Tunings oder der Durchführung von Regressionstests nach einem Modellupdate verwendet. Beispielsweise würde ein Team, das einen Kundenservice-Chatbot entwickelt, diese Tools verwenden, um die Konversationsfähigkeiten und Kosten von Modellen von OpenAI, Anthropic und Google zu vergleichen, bevor es sich für eines entscheidet.
Auswahlkriterien
Bei der Auswahl eines Modellvergleichs-Tools sollten Sie die Bandbreite der unterstützten Modelle berücksichtigen, einschließlich proprietärer APIs und Open-Source-Optionen. Bewerten Sie die verfügbaren Benchmark-Suiten und die Flexibilität, benutzerdefinierte Bewertungsdatensätze zu erstellen. Prüfen Sie die Integrationsfähigkeiten mit Ihrem bestehenden MLOps-Workflow und Ihren CI/CD-Pipelines. Berücksichtigen Sie schließlich Kollaborationsfunktionen, die es Teammitgliedern ermöglichen, Ergebnisse zu überprüfen, sowie Preismodelle, die mit Ihren Bewertungsanforderungen skalieren.
ModellvergleichAnwendungsfälle
Auswahl des optimalen LLM für einen neuen Chatbot
Ein Produktteam entwickelt einen neuen KI-gestützten Kundensupport-Chatbot. Sie verwenden ein Modellvergleichs-Tool, um GPT-4, Claude 3 Sonnet und Llama 3 70B zu bewerten. Sie erstellen einen 'goldenen Datensatz' mit 100 häufigen Kundenanfragen und testen alle drei Modelle damit. Die Plattform bietet eine nebeneinanderliegende Ansicht der Antworten sowie automatisierte Metriken für Hilfsbereitschaft und Ton. Sie berechnet auch die durchschnittlichen Kosten pro 1.000 Konversationen für jedes Modell. Basierend auf den Ergebnissen wählen sie Claude 3 Sonnet, da es das beste Gleichgewicht zwischen Gesprächsqualität und Betriebskosten für ihren spezifischen Anwendungsfall bietet.
Bewertung der Leistung eines feingetunten Modells
Ein ML-Ingenieur hat ein Open-Source-Modell Mistral 7B auf internen Unternehmensdokumenten für eine Frage-Antwort-Aufgabe feingetunt. Um die Bereitstellung zu rechtfertigen, verwendet er ein Vergleichs-Tool, um das feingetunte Modell mit dem Basismodell Mistral 7B und einem proprietären Modell wie GPT-4 zu benchmarken. Er lädt einen Testsatz von 50 technischen Fragen hoch. Das Tool misst die faktische Genauigkeit und Relevanz. Die Ergebnisse zeigen, dass sein feingetuntes Modell das Basismodell um 30 % in der Genauigkeit übertrifft und 10-mal günstiger ist als GPT-4, was einen klaren Beweis für die Fortsetzung der Bereitstellung liefert.
Regressionstests für Modell-API-Updates
Ein MLOps-Team verwaltet eine Zusammenfassungsfunktion, die auf einer externen Modell-API basiert. Der API-Anbieter kündigt eine neue Version an. Vor dem Wechsel verwendet das Team eine Modellvergleichsplattform, um seine Suite von 500 Testdokumenten sowohl mit der alten als auch mit der neuen API-Version durchlaufen zu lassen. Die Plattform markiert automatisch alle Zusammenfassungen der neuen Version, die im Vergleich zur Ausgabe der alten Version erheblich kürzer, weniger kohärent oder sachlich falsch sind. Diese automatisierten Regressionstests verhindern eine Verschlechterung der Servicequalität und gewährleisten einen reibungslosen Übergang zum aktualisierten Modell.
Vergleich von Bildgenerierungsmodellen für das Marketing
Eine Marketingagentur muss ein Bildgenerierungsmodell für die Erstellung von Werbemitteln auswählen. Sie verwenden ein Vergleichs-Tool, um DALL-E 3, Midjourney und Stable Diffusion mit 20 verschiedenen Prompts zu testen, die sich auf die Produkte ihres Kunden beziehen. Das Tool ermöglicht es ihrem Kreativteam, jedes generierte Bild auf einer Skala von 1-5 nach Prompt-Treue, ästhetischer Qualität und Markenausrichtung zu bewerten. Die aggregierten Bewertungen zeigen, dass Midjourney zwar die ästhetisch ansprechendsten Bilder erzeugt, DALL-E 3 jedoch bei der genauen Einbeziehung spezifischer Produktdetails, die in den Prompts erwähnt werden, überlegen ist, was es zur besseren Wahl für ihre Bedürfnisse macht.
Optimierung des Kosten-Leistungs-Verhältnisses für eine Zusammenfassungs-API
Ein Nachrichtenaggregator-Dienst verwendet ein LLM zur Zusammenfassung von Artikeln. Um Kosten zu senken, möchten sie das günstigste Modell finden, das die Qualität beibehält. Mit einem Vergleichs-Tool testen sie fünf verschiedene Modelle, vom High-End-Modell GPT-4 bis hin zu kleineren Open-Source-Alternativen. Sie lassen 1.000 Artikel durch jedes Modell laufen und verwenden automatisierte ROUGE-Scores, um die Zusammenfassungsqualität zu messen, während das Tool die Kosten für jedes Modell verfolgt. Sie entdecken, dass eine quantisierte Version eines Llama 3 8B-Modells 95 % der Qualität von GPT-4 bei nur 10 % der Kosten liefert, was zu erheblichen monatlichen Einsparungen führt.
A/B-Tests von Prompts über mehrere Modelle hinweg
Ein Prompt-Ingenieur hat die Aufgabe, den effektivsten Prompt für eine Codegenerierungsfunktion zu erstellen. Anstatt Prompts einzeln zu testen, verwendet er ein Modellvergleichs-Tool, um ein Matrix-Experiment einzurichten. Er gibt drei verschiedene Prompt-Variationen ein und testet sie mit vier Modellen (z. B. GPT-4, Claude 3 Opus, Gemini Pro und ein spezialisiertes Codemodell). Die Plattform führt alle 12 Kombinationen aus und präsentiert die Ergebnisse in einer Heatmap, die zeigt, welches Prompt-Modell-Paar den genauesten und effizientesten Code erzeugt. Dies beschleunigt den Prozess der Prompt-Optimierung um das Zehnfache.