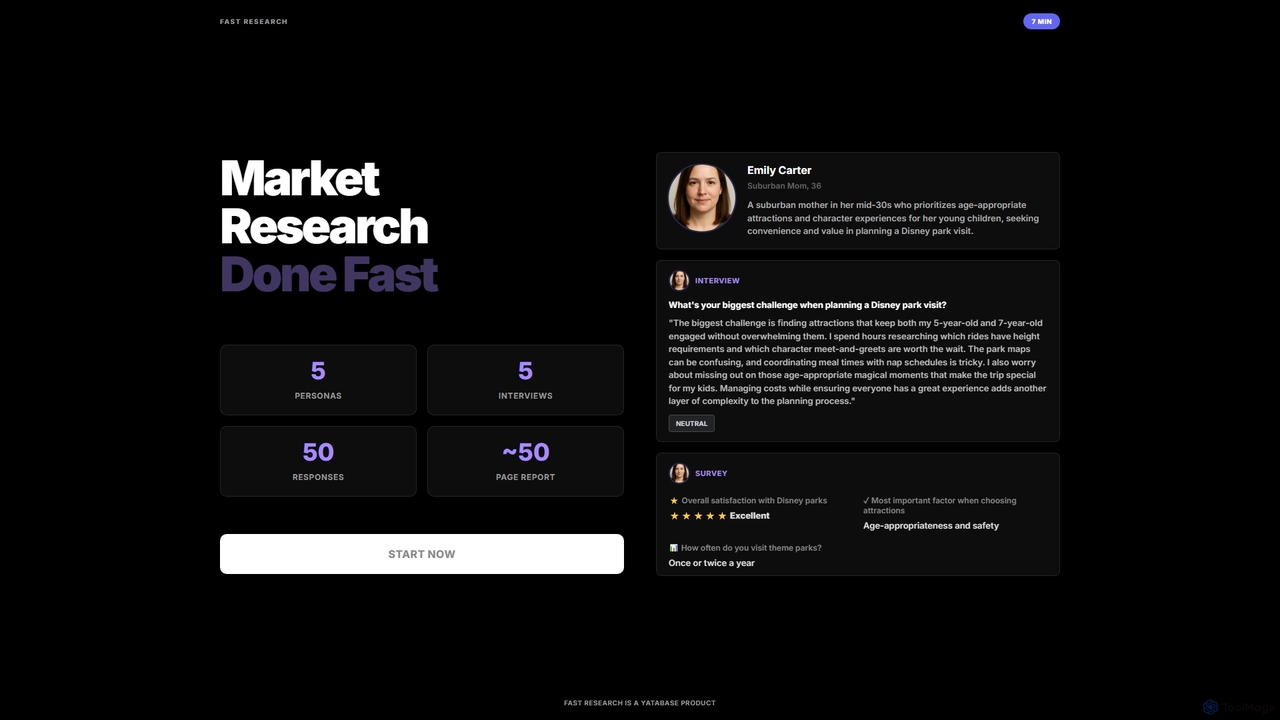
Fast Research
Fast Research ist ein KI-gestütztes Marktforschungstool, das schnell synthetische Daten generiert, einschließlich detaillierter Personas, simulierter Interviews und Umfrageantworten. …
Fast Research ist ein KI-gestütztes Marktforschungstool, das schnell synthetische Daten generiert, einschließlich detaillierter Personas, simulierter Interviews und Umfrageantworten. Es liefert umfassende Berichte, die Unternehmen ermöglichen, schnelle, umsetzbare Erkenntnisse für strategische Entscheidungen ohne die Komplexität traditioneller Datenerfassung zu gewinnen.
Über Synthetische Daten
Synthetische Daten beziehen sich auf künstlich generierte Datensätze, die die statistischen Eigenschaften und Muster realer Daten widerspiegeln, ohne tatsächliche persönliche oder sensible Informationen zu enthalten. Diese KI-gestützten Tools nutzen fortschrittliche Algorithmen, um realistische Daten zu erstellen und kritische Herausforderungen wie Datenschutz, Datenknappheit und Verzerrungen zu bewältigen. Sie bieten eine sichere und flexible Alternative für verschiedene Analyse- und Entwicklungszwecke, insbesondere in der Marktforschung.
Kernfunktionen
- Datenschutz: Generiert Daten, die die statistische Integrität wahren und gleichzeitig sicherstellen, dass keine realen individuellen Daten offengelegt werden.
- Datenaugmentation: Erstellt zusätzliche Datenpunkte, um bestehende Datensätze zu erweitern und die Modellschulung sowie Robustheit zu verbessern.
- Bias-Minderung: Ermöglicht die Generierung ausgewogener Datensätze, um inhärente Verzerrungen in realen Daten zu reduzieren.
- Realistische Simulation: Produziert Daten, die die Verteilungen, Korrelationen und Strukturen der Originaldaten genau widerspiegeln.
- Skalierbarkeit: Ermöglicht die bedarfsgerechte Generierung großer Datenmengen und überwindet die Einschränkungen der realen Datenerfassung.
Anwendungsfälle
Unternehmen nutzen synthetische Daten, um neue Produktfunktionen zu testen, Marktszenarien zu simulieren oder KI-Modelle zu trainieren, ohne die Kundendaten zu gefährden. Forscher können Trends und Muster in sensiblen Bereichen wie dem Gesundheitswesen oder dem Finanzwesen analysieren und so eine ethische Datenverarbeitung gewährleisten.
Auswahlkriterien
Bei der Auswahl eines Tools für synthetische Daten sollten Sie die erforderliche Wiedergabetreue (wie genau es reale Daten nachahmt), die Arten von Daten, die es generieren kann (tabellarisch, Bild, Text), seine Datenschutzgarantien und die Integrationsmöglichkeiten mit bestehenden Datenpipelines berücksichtigen. Bewerten Sie die Benutzerfreundlichkeit und den Grad der Kontrolle über die Datenmerkmale.
Synthetische DatenAnwendungsfälle
Entwicklung datenschutzfreundlicher KI-Modelle
Datenwissenschaftler nutzen synthetische Daten, um maschinelle Lernmodelle für sensible Anwendungen (z. B. medizinische Diagnostik, Finanzbetrugserkennung) zu trainieren, ohne auf reale Patienten- oder Kundeninformationen zuzugreifen oder diese offenzulegen. Dies gewährleistet die Einhaltung strenger Datenschutzbestimmungen wie DSGVO und HIPAA und ermöglicht eine robuste Modellentwicklung in stark regulierten Branchen.
Marktverhaltenssimulation für Produkttests
Marktforscher generieren synthetische Kundendatensätze, um verschiedene Marktbedingungen und Verbraucherreaktionen auf neue Produkteinführungen oder Marketingkampagnen zu simulieren. Dies ermöglicht risikofreie A/B-Tests, Szenarioplanung und Nachfrageprognosen vor der realen Bereitstellung, wodurch Kosten gespart und potenzielle negative Auswirkungen gemindert werden.
Überwindung von Datenknappheit in Nischenmärkten
Start-ups oder Unternehmen in Nischenbranchen mangelt es oft an ausreichenden realen Daten für robuste Analysen oder das Training von KI-Modellen. Synthetische Datentools helfen dabei, umfangreiche, repräsentative Datensätze zu erstellen, um diese Lücken zu schließen und so eine umfassende Analyse, Produktentwicklung und Wettbewerbsintelligenz auch bei begrenzten Originaldatenquellen zu ermöglichen.
Verbesserung von Softwaretests und -entwicklung
Softwareentwickler nutzen synthetische Daten, um Testumgebungen zu befüllen und sicherzustellen, dass Anwendungen vielfältige Dateneingaben und Grenzfälle verarbeiten können, ohne auf sensible Produktionsdaten angewiesen zu sein. Dies beschleunigt Testzyklen, verbessert die Softwarequalität und ermöglicht eine gründlichere Validierung neuer Funktionen und Updates in einer kontrollierten, sicheren Umgebung.
Minderung von Verzerrungen in KI-Trainingsdatensätzen
KI-Ethikforscher und -entwickler nutzen die Generierung synthetischer Daten, um ausgewogene Datensätze zu erstellen, die Verzerrungen in realen Daten (z. B. Unterrepräsentation bestimmter demografischer Gruppen) korrigieren. Dies führt zu faireren und gerechteren KI-Systemen, reduziert diskriminierende Ergebnisse und verbessert die allgemeine Vertrauenswürdigkeit von KI-Anwendungen.
Erleichterung des Datenaustauschs und der Zusammenarbeit
Organisationen können synthetische Versionen ihrer proprietären oder sensiblen Datensätze mit externen Partnern, Forschern oder Aufsichtsbehörden teilen. Dies ermöglicht kollaborative Innovation und Forschung unter strikter Einhaltung von Datengovernance- und Vertraulichkeitsvereinbarungen und fördert so ein sicheres Umfeld für datengesteuerte Erkenntnisse über Ökosysteme hinweg.