Oneinfer
Oneinfer ist eine hochleistungsfähige KI-Inferenzplattform für Entwickler. Sie bietet eine einheitliche API für den Zugriff auf über 15 …
Oneinfer ist eine hochleistungsfähige KI-Inferenzplattform für Entwickler. Sie bietet eine einheitliche API für den Zugriff auf über 15 LLMs wie GPT-4 und Claude und vereinfacht die KI-Integration. Die Plattform zeichnet sich durch serverlose Bereitstellung, automatische Skalierung, unternehmenstaugliche Sicherheit und Pay-as-you-go-Preise aus. Sie bietet auch einen Marktplatz zum Mieten von GPU-Instanzen für benutzerdefinierte KI-Workloads.

Dank
Dank ist ein JavaScript-natives Open-Source-Framework zur Orchestrierung und Bereitstellung von containerisierten KI-Agenten. Es ermöglicht Entwicklern, mehrere KI-Agenten als …
Dank ist ein JavaScript-natives Open-Source-Framework zur Orchestrierung und Bereitstellung von containerisierten KI-Agenten. Es ermöglicht Entwicklern, mehrere KI-Agenten als Microservices in jeder Cloud-Infrastruktur zu erstellen, zu verwalten und zu skalieren, wodurch komplexe KI-Bereitstellungen mit Docker-nativer Architektur und Echtzeitüberwachung vereinfacht werden.
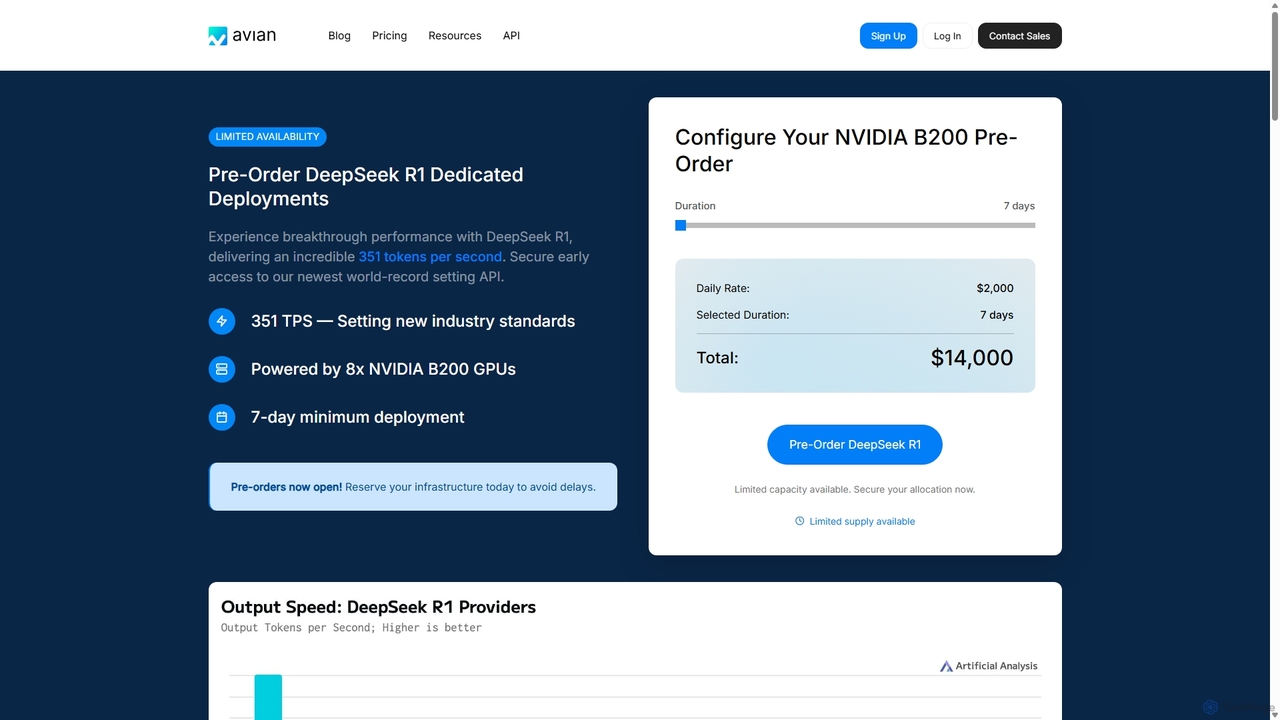
Avian
Avian ist eine hochleistungsfähige KI-Inferenzplattform, die Weltrekordgeschwindigkeiten für große Sprachmodelle (LLMs) bietet. Sie stellt sowohl eine serverlose API …
Avian ist eine hochleistungsfähige KI-Inferenzplattform, die Weltrekordgeschwindigkeiten für große Sprachmodelle (LLMs) bietet. Sie stellt sowohl eine serverlose API für beliebte Modelle als auch dedizierte GPU-Deployments für benutzerdefinierte Modelle von HuggingFace bereit. Avian ist auf Skalierbarkeit und Produktions-Workloads ausgelegt und liefert 3-10x schnellere Inferenzgeschwindigkeiten als der Branchendurchschnitt, mit unternehmenstauglicher Sicherheit und wettbewerbsfähigen Preisen.
Zetic.ai
Zetic.ai ist eine Plattform, die es Entwicklern ermöglicht, KI-Modelle direkt auf Edge-Geräten bereitzustellen und so die Notwendigkeit teurer …
Zetic.ai ist eine Plattform, die es Entwicklern ermöglicht, KI-Modelle direkt auf Edge-Geräten bereitzustellen und so die Notwendigkeit teurer GPU-Server zu eliminieren. Die automatisierte Pipeline, ZETIC.MLange, optimiert und konvertiert Modelle für die Ausführung auf dem Gerät, erreicht eine bis zu 60-mal schnellere Leistung durch NPU-Beschleunigung und gewährleistet dabei Datenschutz und reduzierte Latenz.
SiliconFlow
SiliconFlow ist eine einheitliche KI-Infrastrukturplattform, die für die hochleistungsfähige Inferenz von Großen Sprachmodellen (LLMs) und multimodalen Modellen entwickelt …
SiliconFlow ist eine einheitliche KI-Infrastrukturplattform, die für die hochleistungsfähige Inferenz von Großen Sprachmodellen (LLMs) und multimodalen Modellen entwickelt wurde. Sie bietet Entwicklern und Unternehmen skalierbare, kostengünstige und flexible Bereitstellungsoptionen, einschließlich serverloser APIs, reservierter GPUs und Feinabstimmungsfunktionen, die alle über eine einzige, OpenAI-kompatible API zugänglich sind.
FriendliAI
FriendliAI ist eine generative KI-Infrastrukturplattform, die entwickelt wurde, um die Inferenz von KI-Modellen zu beschleunigen und zu optimieren. …
FriendliAI ist eine generative KI-Infrastrukturplattform, die entwickelt wurde, um die Inferenz von KI-Modellen zu beschleunigen und zu optimieren. Sie bietet leistungsstarke, kosteneffiziente Lösungen für die Bereitstellung, das Servieren und die Skalierung großer Sprach- und multimodaler Modelle in der Produktion, mit flexiblen Optionen für dedizierte, serverlose oder On-Premise-Umgebungen.