Avian
Website besuchen



Avian Übersicht
Avian ist eine hochmoderne KI-Infrastrukturplattform, die entwickelt wurde, um die schnellste und zuverlässigste KI-Inferenz auf dem Markt zu bieten. Sie richtet sich an Entwickler, KI-Ingenieure und Unternehmen, die für ihre KI-Anwendungen einen hohen Durchsatz und eine geringe Latenz benötigen. Durch den Einsatz neuester Hardware wie NVIDIA B200 und H200 GPUs und fortschrittlicher Optimierungstechniken wie spekulativer Dekodierung erreicht Avian branchenführende Geschwindigkeiten und setzt neue Maßstäbe für Modelle wie DeepSeek R1 mit 351 Token pro Sekunde.
Die Plattform bietet zwei Hauptdienste, um unterschiedlichen Anforderungen gerecht zu werden: eine flexible Serverless API und leistungsstarke dedizierte Deployments. Dieser duale Ansatz ermöglicht es den Nutzern, entweder schnell erstklassige Modelle über einen einfachen API-Aufruf in ihre Anwendungen zu integrieren oder die volle Kontrolle über ihre Infrastruktur zu erlangen, um benutzerdefinierte, feinabgestimmte Modelle für spezielle Aufgaben auszuführen. Avian ist auf Skalierbarkeit ausgelegt und arbeitet ohne Ratenbegrenzungen, um Anwendungen beim Wachstum vom Prototyp bis zur vollen Produktion zu unterstützen.
Wie man Avian verwendet
Der Einstieg in Avian ist unkompliziert und auf die Effizienz von Entwicklern ausgelegt. Es gibt zwei Hauptmethoden, um seine Leistungsfähigkeit zu nutzen:
- Verwendung der Avian Serverless API: Dies ist der schnellste Weg, um auf Hochleistungsmodelle zuzugreifen. Entwickler können sich einfach anmelden, einen API-Schlüssel erhalten und Anfragen an verschiedene Modell-Endpunkte (z. B. die Meta Llama 3.1-Serie) stellen. Der Prozess umfasst eine einfache Code-Implementierung, ähnlich wie bei anderen KI-APIs, und ermöglicht eine nahtlose Integration in bestehende Anwendungen, ohne dass eine Infrastruktur verwaltet werden muss.
- Konfiguration dedizierter Deployments: Für Benutzer, die benutzerdefinierte Modelle von HuggingFace ausführen müssen oder dedizierte Ressourcen für einen konstant hohen Durchsatz benötigen, bietet Avian dedizierte GPU-Instanzen. Benutzer können ihren gewünschten GPU-Typ (z. B. NVIDIA H200 SXM) auswählen, die Bereitstellungsdauer konfigurieren und ihr Modell auf der optimierten Infrastruktur von Avian bereitstellen. Dies ist ideal für Produktions-Workloads, die eine garantierte Leistung und Ressourcenzuweisung erfordern.
Kernfunktionen von Avian
- Rekordverdächtige Inferenzgeschwindigkeit: Erreicht Geschwindigkeiten von bis zu 351 Token pro Sekunde, was den Branchendurchschnitt deutlich übertrifft und Echtzeit-KI-Anwendungen ermöglicht.
- Serverless API: Bietet Pay-as-you-go-Zugriff auf eine Reihe von Hochleistungsmodellen wie Meta Llama 3.1 und DeepSeek R1, ohne Ratenbegrenzungen.
- Dedizierte GPU-Deployments: Bietet dedizierte Instanzen mit den neuesten NVIDIA GPUs (B200, H200, H100) zur Bereitstellung jedes Modells von HuggingFace, um maximale Leistung und Kontrolle zu gewährleisten.
- Unternehmenstaugliche Sicherheit: Verfügt über robuste Sicherheitsmaßnahmen, einschließlich SOC2 Typ 2-Konformität (in Arbeit), GDPR-Einhaltung, TLS 1.2+ Verschlüsselung und Multi-Faktor-Authentifizierung (MFA). Daten werden nicht dauerhaft gespeichert, um die Privatsphäre der Benutzer zu gewährleisten.
- Skalierbar und produktionsreif: Entwickelt, um hochvolumige Produktions-Workloads ohne Leistungsabfall zu bewältigen und Unternehmen bei der Skalierung zu unterstützen.
- Datenkonnektoren: Bietet eine Reihe von Konnektoren für Plattformen wie Looker Studio und Google Sheets, die eine nahtlose Datenintegration aus Quellen wie Google Analytics, Facebook Ads und mehr ermöglichen.
Anwendungsfälle für Avian
Die Hochgeschwindigkeitsinfrastruktur von Avian eignet sich für eine Vielzahl anspruchsvoller KI-Anwendungen:
- Echtzeit-Chatbots und KI-Assistenten: Betreiben von Konversations-KI, die sofort reagieren kann und ein natürliches und flüssiges Benutzererlebnis bietet.
- Großangelegte Inhaltserstellung: Ermöglicht Plattformen, Artikel, Marketingtexte und Code in beispiellosem Umfang und mit beispielloser Geschwindigkeit zu generieren.
- Komplexe Datenanalyse und Zusammenfassung: Verarbeitung und Analyse großer Mengen von Textdaten in Echtzeit für Finanzanalysen, Forschung und Business Intelligence.
- Bereitstellung proprietärer Modelle: Unternehmen mit benutzerdefinierten oder feinabgestimmten Modellen können diese auf der dedizierten Infrastruktur von Avian bereitstellen, um eine optimale Leistung in Produktionsumgebungen zu erzielen.
Vorteile von Avian
Avian hebt sich im wettbewerbsintensiven KI-Infrastrukturmarkt durch mehrere entscheidende Vorteile ab:
- Unübertroffene Leistung: Liefert 3-10x schnellere Inferenzgeschwindigkeiten im Vergleich zu anderen großen Cloud-Anbietern und Inferenzdiensten.
- Flexibilität: Unterstützt sowohl Standardmodelle über eine einfache API als auch benutzerdefinierte Modelle auf dedizierter Hardware und bedient damit alle Ebenen der KI-Entwicklung.
- Kosteneffizienz: Bietet wettbewerbsfähige Preise für seine API und dedizierte Instanzen und liefert ein überlegenes Preis-Leistungs-Verhältnis.
- Zuverlässigkeit und Skalierbarkeit: Das Fehlen von Ratenbegrenzungen und die Verwendung von produktionsreifer Infrastruktur stellen sicher, dass Anwendungen nahtlos skalieren können, ohne auf Leistungsengpässe zu stoßen.
- Starke Sicherheitsposition: Ein klares Bekenntnis zur Datensicherheit und zum Datenschutz schafft Vertrauen bei Unternehmenskunden, die mit sensiblen Informationen umgehen.
Preise und Pläne
Avian bietet eine transparente und flexible Preisstruktur, die auf unterschiedliche Nutzungsmuster zugeschnitten ist:
- Avian API (Pay-per-use): Benutzer werden pro Million Token für Eingabe und Ausgabe abgerechnet. Die Preise sind wettbewerbsfähig und variieren je nach Modell. Zum Beispiel:
- Meta Llama 3.1 8B Instruct: 0,10 $ pro Million Eingabe-/Ausgabetoken.
- Meta Llama 3.1 70B Instruct: 0,45 $ pro Million Eingabe-/Ausgabetoken.
- Meta Llama 3.1 405B Instruct: 1,50 $ pro Million Eingabe-/Ausgabetoken.
- Dedizierte Deployments: Abrechnung pro Sekunde für reservierte GPU-Instanzen. Dies ist ideal für Workloads mit hohem Durchsatz. Beispielraten für reservierte Instanzen:
- NVIDIA H100 SXM (80GB HBM3): Ab 0,00139 $/Sekunde.
- NVIDIA H200 SXM (141GB HBM3): Ab 0,00208 $/Sekunde.
- Vorbestellungen für neue Hardware: Avian bietet auch Vorbestellungen für modernste Hardware wie die NVIDIA B200 an, damit Kunden sich den Zugang zur neuesten Technologie sichern können. Zum Beispiel kostet ein 7-tägiges Deployment eines DeepSeek R1 auf einem 8x NVIDIA B200-Setup 14.000 $.
Avian Kommentare (0)
Melden Sie sich an, um einen Kommentar zu hinterlassen
Jetzt anmeldenAvianWebsite-Traffic-Analyse
Aktueller Traffic-Status
Status
Monatlicher Traffic-Trend
Standort
Top 5 Länder/Regionen
-
🇺🇸 United States34,45%
-
🇻🇳 Vietnam30,53%
-
🇬🇧 United Kingdom20,68%
-
🇮🇳 India14,34%
Beliebte Keywords
| Keyword | Kosten pro Klick |
|---|---|
|
$0,23
|
|
|
$0,00
|
|
|
$0,96
|
|
|
$0,00
|
|
|
$0,00
|
Avian Alternativen
Alle anzeigen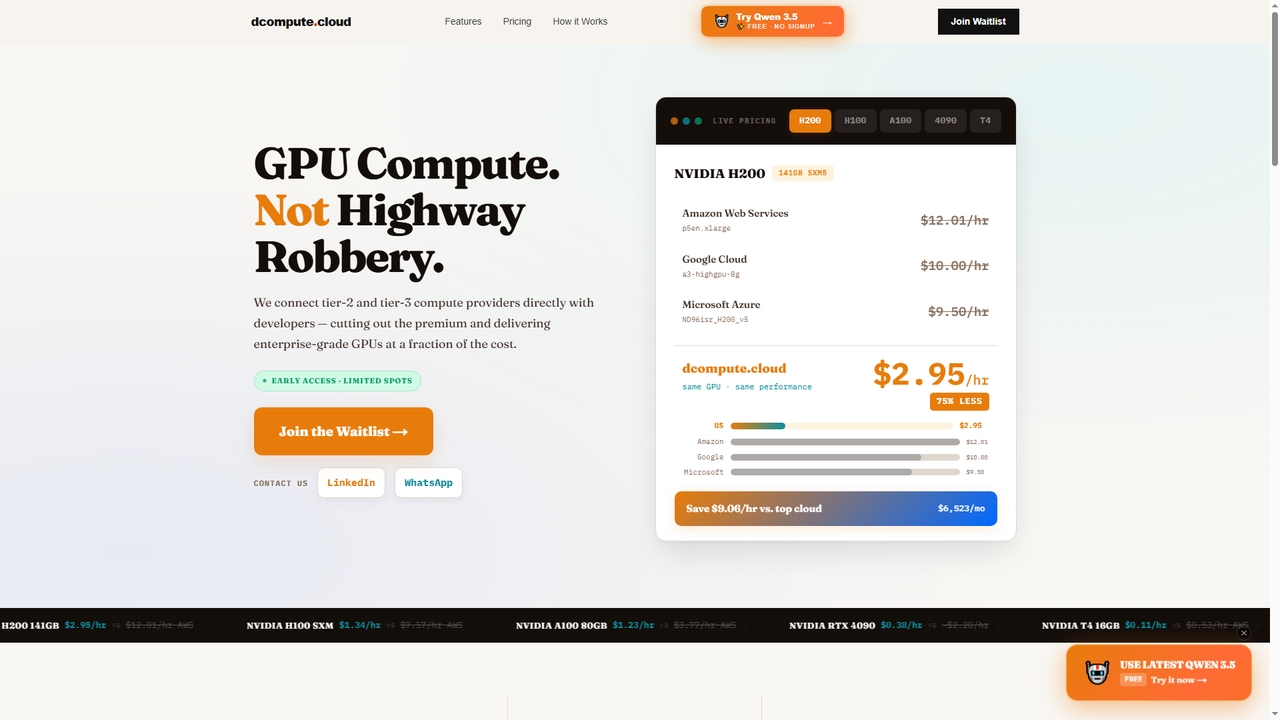
Dcompute
Dcompute ist ein dezentraler GPU-Computing-Marktplatz, der Entwickler direkt mit Tier-2- und Tier-3-Rechenzentrumsanbietern verbindet. Es bietet Enterprise-Grade-NVIDIA-GPUs (H200, H100, …
Dcompute ist ein dezentraler GPU-Computing-Marktplatz, der Entwickler direkt mit Tier-2- und Tier-3-Rechenzentrumsanbietern verbindet. Es bietet Enterprise-Grade-NVIDIA-GPUs (H200, H100, A100, RTX 4090, T4) zu einem Bruchteil der Kosten großer Cloud-Anbieter und verspricht Einsparungen von bis zu 90 %. Die Plattform bietet sofortige Bereitstellung, eine einheitliche API/Oberfläche, vollständige Orchestrierung und reine nutzungsabhängige Abrechnung pro Sekunde ohne Mindestgebühren.
Zetic.ai
Zetic.ai ist eine Plattform, die es Entwicklern ermöglicht, KI-Modelle direkt auf Edge-Geräten bereitzustellen und so die Notwendigkeit teurer …
Zetic.ai ist eine Plattform, die es Entwicklern ermöglicht, KI-Modelle direkt auf Edge-Geräten bereitzustellen und so die Notwendigkeit teurer GPU-Server zu eliminieren. Die automatisierte Pipeline, ZETIC.MLange, optimiert und konvertiert Modelle für die Ausführung auf dem Gerät, erreicht eine bis zu 60-mal schnellere Leistung durch NPU-Beschleunigung und gewährleistet dabei Datenschutz und reduzierte Latenz.
Symphony
Symphony ist eine universelle LLM-Schnittstelle, die eine OpenAI-kompatible API zur Bereitstellung, Verwaltung und Skalierung von KI-Anwendungen bietet. Sie …
Symphony ist eine universelle LLM-Schnittstelle, die eine OpenAI-kompatible API zur Bereitstellung, Verwaltung und Skalierung von KI-Anwendungen bietet. Sie zeichnet sich durch unternehmensgerechte Zuverlässigkeit, bis zu 20 % niedrigere Kosten und die Unterstützung von über 100 wichtigen KI-Modellen wie GPT-5 und Llama 4 aus, was sie zur idealen Lösung für Entwickler und Unternehmen macht, die eine effiziente und robuste KI-Infrastruktur suchen.
SiliconFlow
SiliconFlow ist eine einheitliche KI-Infrastrukturplattform, die für die hochleistungsfähige Inferenz von Großen Sprachmodellen (LLMs) und multimodalen Modellen entwickelt …
SiliconFlow ist eine einheitliche KI-Infrastrukturplattform, die für die hochleistungsfähige Inferenz von Großen Sprachmodellen (LLMs) und multimodalen Modellen entwickelt wurde. Sie bietet Entwicklern und Unternehmen skalierbare, kostengünstige und flexible Bereitstellungsoptionen, einschließlich serverloser APIs, reservierter GPUs und Feinabstimmungsfunktionen, die alle über eine einzige, OpenAI-kompatible API zugänglich sind.

Baseten
Baseten ist eine produktionsreife Inferenzplattform für die Bereitstellung, Skalierung und Verwaltung von KI-Modellen. Sie bietet hochleistungsfähige Laufzeitumgebungen, nahtlose …
Baseten ist eine produktionsreife Inferenzplattform für die Bereitstellung, Skalierung und Verwaltung von KI-Modellen. Sie bietet hochleistungsfähige Laufzeitumgebungen, nahtlose Entwickler-Workflows und flexible Bereitstellungsoptionen (Cloud, Self-Hosted, Hybrid). Ideal für Ingenieur- und ML-Teams, die geschäftskritische KI-Anwendungen erstellen.
Nexlayer
Nexlayer ist die erste agenten-native Cloud-Plattform, die KI-Codierungsagenten befähigt, produktionsreife Anwendungen schnell bereitzustellen. Sie automatisiert komplexe Infrastrukturen und …
Nexlayer ist die erste agenten-native Cloud-Plattform, die KI-Codierungsagenten befähigt, produktionsreife Anwendungen schnell bereitzustellen. Sie automatisiert komplexe Infrastrukturen und ermöglicht es Entwicklern und Gründern, Full-Stack-Apps, APIs und Datenbanken in Minutenschnelle ohne DevOps-Aufwand zu veröffentlichen.

Truefoundry
Truefoundry ist eine unternehmenstaugliche Plattform für die Bereitstellung, Verwaltung und Skalierung von agentenbasierten KI-Anwendungen. Es bietet ein einheitliches …
Truefoundry ist eine unternehmenstaugliche Plattform für die Bereitstellung, Verwaltung und Skalierung von agentenbasierten KI-Anwendungen. Es bietet ein einheitliches KI-Gateway zur Orchestrierung komplexer KI-Workflows, zur Verwaltung von Modellen und zur Gewährleistung von Sicherheit, Governance und Beobachtbarkeit. Entwickelt für Entwickler und MLOps-Teams, unterstützt es On-Premise-, Cloud- und Hybrid-Bereitstellungen, optimiert die GPU-Auslastung und beschleunigt die Markteinführung.
Vespa.ai
Vespa.ai ist eine hochleistungsfähige KI-Suchplattform zur Erstellung von Großanwendungen. Sie vereint Vektorsuche, Textsuche und maschinelles Lernranking, um fortschrittliche …
Vespa.ai ist eine hochleistungsfähige KI-Suchplattform zur Erstellung von Großanwendungen. Sie vereint Vektorsuche, Textsuche und maschinelles Lernranking, um fortschrittliche Anwendungsfälle wie Retrieval-Augmented Generation (RAG), Empfehlungssysteme und intelligente Suche zu ermöglichen. Entwickelt für Echtzeit-Inferenz und Skalierbarkeit, wird sie von führenden Unternehmen wie Spotify und Perplexity für die Verarbeitung riesiger Datenmengen mit geringer Latenz geschätzt.
novita.ai
Novita AI ist eine entwicklerorientierte Cloud-Plattform, die erschwinglichen, skalierbaren Zugriff auf über 200 KI-Modelle über einfache APIs bietet. …
Novita AI ist eine entwicklerorientierte Cloud-Plattform, die erschwinglichen, skalierbaren Zugriff auf über 200 KI-Modelle über einfache APIs bietet. Sie stellt serverlose GPUs, dedizierte GPU-Instanzen und die Bereitstellung benutzerdefinierter Modelle zur Verfügung, sodass Entwickler KI-Anwendungen erstellen und skalieren können, ohne die Infrastruktur verwalten zu müssen.
Portkey AI
Portkey AI ist ein fortschrittliches KI-Gateway und eine LLM-Ops-Plattform für Entwickler. Es vereinfacht die Entwicklung zuverlässiger, skalierbarer und …
Portkey AI ist ein fortschrittliches KI-Gateway und eine LLM-Ops-Plattform für Entwickler. Es vereinfacht die Entwicklung zuverlässiger, skalierbarer und kostengünstiger KI-Anwendungen durch eine einheitliche API für verschiedene LLMs, Echtzeit-Beobachtbarkeit, semantisches Caching und intelligentes Load Balancing.
Avian Kategorie
Avian Tags
Avian Anwendbare Berufe
Avian KI-Tool
Avian Einbettungsfunktion
Kopieren Sie einfach den Einbettungscode unten und fügen Sie das ansprechende Abzeichen in Ihren Blog, Artikel oder auf die offizielle Website Ihrer App ein, um den Traffic direkt auf die Detailseite dieses Tools zu leiten und so schnell die Sichtbarkeit und Nutzerzahlen zu steigern!

Noch keine Kommentare, seien Sie der Erste!