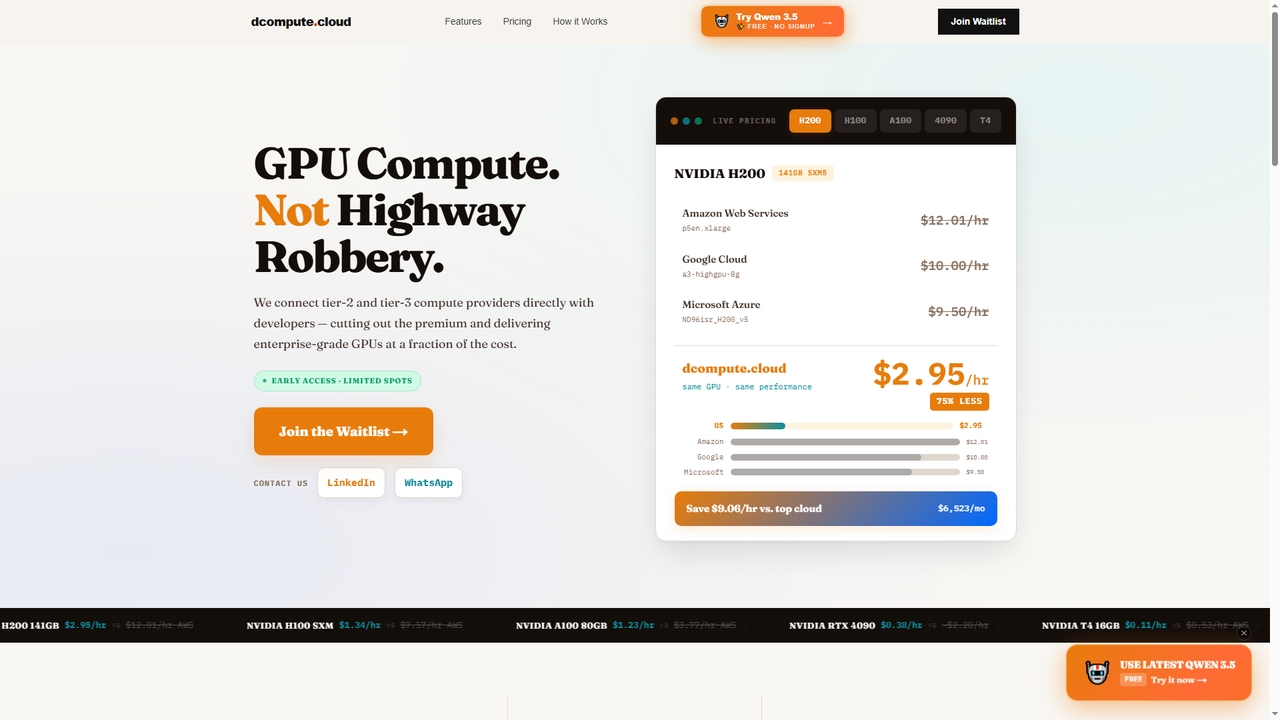
Dcompute
Dcompute ist ein dezentraler GPU-Computing-Marktplatz, der Entwickler direkt mit Tier-2- und Tier-3-Rechenzentrumsanbietern verbindet. Es bietet Enterprise-Grade-NVIDIA-GPUs (H200, H100, …
Dcompute ist ein dezentraler GPU-Computing-Marktplatz, der Entwickler direkt mit Tier-2- und Tier-3-Rechenzentrumsanbietern verbindet. Es bietet Enterprise-Grade-NVIDIA-GPUs (H200, H100, A100, RTX 4090, T4) zu einem Bruchteil der Kosten großer Cloud-Anbieter und verspricht Einsparungen von bis zu 90 %. Die Plattform bietet sofortige Bereitstellung, eine einheitliche API/Oberfläche, vollständige Orchestrierung und reine nutzungsabhängige Abrechnung pro Sekunde ohne Mindestgebühren.
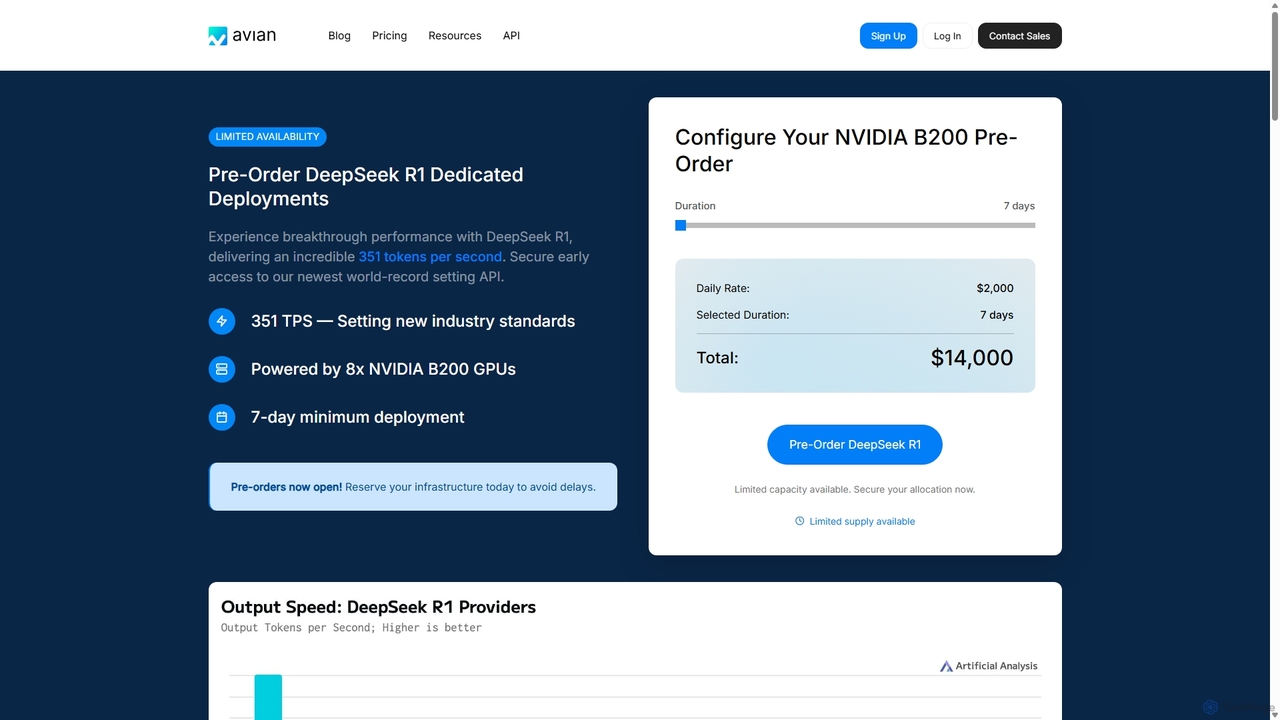
Avian
Avian ist eine hochleistungsfähige KI-Inferenzplattform, die Weltrekordgeschwindigkeiten für große Sprachmodelle (LLMs) bietet. Sie stellt sowohl eine serverlose API …
Avian ist eine hochleistungsfähige KI-Inferenzplattform, die Weltrekordgeschwindigkeiten für große Sprachmodelle (LLMs) bietet. Sie stellt sowohl eine serverlose API für beliebte Modelle als auch dedizierte GPU-Deployments für benutzerdefinierte Modelle von HuggingFace bereit. Avian ist auf Skalierbarkeit und Produktions-Workloads ausgelegt und liefert 3-10x schnellere Inferenzgeschwindigkeiten als der Branchendurchschnitt, mit unternehmenstauglicher Sicherheit und wettbewerbsfähigen Preisen.
novita.ai
Novita AI ist eine entwicklerorientierte Cloud-Plattform, die erschwinglichen, skalierbaren Zugriff auf über 200 KI-Modelle über einfache APIs bietet. …
Novita AI ist eine entwicklerorientierte Cloud-Plattform, die erschwinglichen, skalierbaren Zugriff auf über 200 KI-Modelle über einfache APIs bietet. Sie stellt serverlose GPUs, dedizierte GPU-Instanzen und die Bereitstellung benutzerdefinierter Modelle zur Verfügung, sodass Entwickler KI-Anwendungen erstellen und skalieren können, ohne die Infrastruktur verwalten zu müssen.
Über GPU
Eine GPU (Graphics Processing Unit) ist ein spezialisierter Prozessor, der entscheidend zur Beschleunigung rechenintensiver Aufgaben beiträgt, insbesondere in den Bereichen künstliche Intelligenz und maschinelles Lernen. Im Gegensatz zu Allzweck-CPUs verfügen GPUs über eine massiv parallele Architektur, die es ihnen ermöglicht, mehrere Datenpunkte gleichzeitig zu verarbeiten. Dies macht sie unverzichtbar für das Training komplexer KI-Modelle, das Rendern hochauflösender Grafiken und die Durchführung groß angelegter Datenanalysen in Cloud-Computing-Umgebungen. Ihre Fähigkeit, parallele Workloads zu bewältigen, reduziert die Verarbeitungszeiten erheblich und verbessert die Leistung fortschrittlicher KI-Anwendungen.
Kernfunktionen
- Massiv parallele Architektur: Ermöglicht die gleichzeitige Verarbeitung von Tausenden von Threads für datenintensive Aufgaben.
- Hohe Speicherbandbreite: Bietet schnellen Datenzugriff, entscheidend für große Datensätze und komplexe Modelle.
- Spezialisierte Kerne (Tensor/CUDA): Optimiert für spezifische KI-Operationen wie Matrixmultiplikation und Deep Learning.
- Gleitkomma-Leistung: Liefert überlegene Geschwindigkeit für wissenschaftliche Berechnungen und das Training von KI-Modellen.
Anwendungsszenarien
GPUs werden häufig im Training von Deep-Learning-Modellen, in wissenschaftlichen Simulationen und bei der Echtzeit-Datenverarbeitung eingesetzt. Sie treiben KI-gesteuerte Anwendungen wie die Verarbeitung natürlicher Sprache, Computer Vision und Empfehlungssysteme an. Im Cloud Computing werden GPUs als Dienste angeboten, um skalierbare, bedarfsgerechte Rechenleistung für verschiedene Hochleistungs-Workloads bereitzustellen.
Auswahlkriterien
Bei der Auswahl einer GPU müssen die Anzahl der CUDA/Tensor-Kerne für KI-Aufgaben, die Speicherkapazität (VRAM) für große Modelle und die Speicherbandbreite für den Datendurchsatz berücksichtigt werden. Die Kompatibilität mit bestehenden Software-Frameworks (z. B. TensorFlow, PyTorch) und die Energieeffizienz für Cloud-Bereitstellungen sind ebenfalls kritische Faktoren. Bewerten Sie das Kosten-Leistungs-Verhältnis basierend auf Ihren spezifischen Workload-Anforderungen.
GPUAnwendungsfälle
Beschleunigung des Deep-Learning-Modelltrainings
Datenwissenschaftler nutzen cloudbasierte GPUs, um das Training komplexer neuronaler Netze für Aufgaben wie Bilderkennung oder natürliche Sprachverarbeitung erheblich zu beschleunigen. Durch die Verteilung von Workloads auf mehrere GPU-Instanzen können sie Modelle schneller iterieren, die Trainingszeiten von Tagen auf Stunden reduzieren und eine schnellere Entwicklung von KI-Lösungen ermöglichen.
Antrieb wissenschaftlicher Simulationen und HPC
Forscher und Ingenieure nutzen GPU-Cluster in der Cloud für Hochleistungsrechenaufgaben wie molekulardynamische Simulationen, Wettervorhersage und numerische Strömungsmechanik. Die parallelen Verarbeitungsfähigkeiten von GPUs ermöglichen es ihnen, komplexe Simulationen mit größerer Präzision und Geschwindigkeit durchzuführen, was zu Durchbrüchen in verschiedenen wissenschaftlichen Bereichen führt.
Ermöglichung von Echtzeit-KI-Inferenz und -Analyse
Unternehmen setzen GPU-beschleunigte Instanzen für die Echtzeit-KI-Inferenz in Anwendungen wie Betrugserkennung, personalisierten Empfehlungen oder autonomem Fahren ein. GPUs bieten die geringe Latenzverarbeitung, die erforderlich ist, um trainierte KI-Modelle sofort auszuführen und sofortige Erkenntnisse und Reaktionen zu liefern, die für zeitkritische Operationen entscheidend sind.
Verbesserung von Videorendering und 3D-Inhaltserstellung
Content-Ersteller und Animationsstudios nutzen Cloud-GPUs für anspruchsvolle Aufgaben wie 3D-Rendering, Videobearbeitung und visuelle Effekte. Die immense Rechenleistung von GPUs reduziert die Rendering-Zeiten drastisch, sodass Künstler qualitativ hochwertige visuelle Inhalte effizienter produzieren und enge Produktionsfristen einhalten können.
Beschleunigung der groß angelegten Datenanalyse
Datenanalysten und Unternehmen setzen GPUs ein, um die Verarbeitung und Analyse massiver Datensätze zu beschleunigen, insbesondere in Bereichen wie Finanzmodellierung, Genomik und Markttrendvorhersage. GPUs können parallele Datentransformationen und komplexe Abfragen viel schneller als CPUs verarbeiten, was schnellere Erkenntnisse aus Big Data ermöglicht.
Bereitstellung von KI-Modellen am Edge
Entwickler nutzen spezialisierte, kleinere GPUs für die Bereitstellung von KI-Modellen auf Edge-Geräten wie intelligenten Kameras, IoT-Sensoren oder Industrierobotern. Diese GPUs ermöglichen eine lokale Echtzeit-Inferenz ohne ständige Cloud-Konnektivität, verbessern den Datenschutz, reduzieren die Latenz und optimieren die Bandbreitennutzung für Edge-KI-Anwendungen.