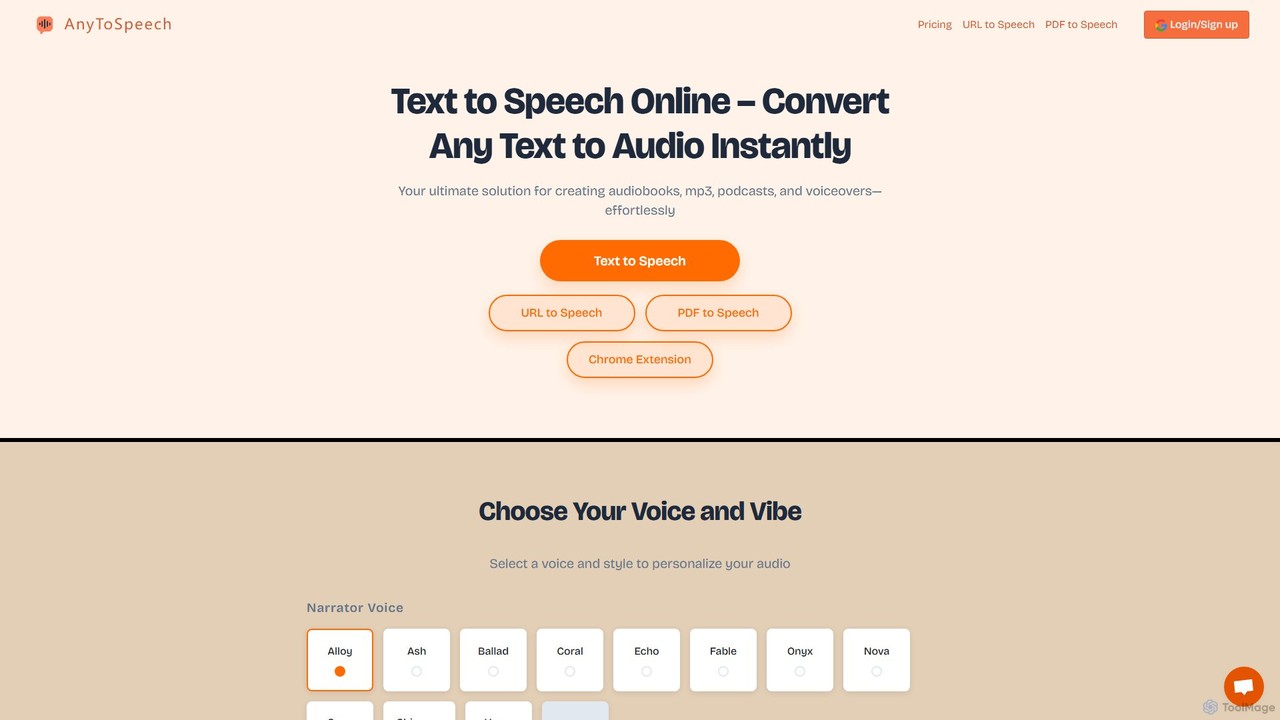
Beste Gesamtalternative
tts4free
tts4free und AnyToSpeech decken beide Text zu Sprache、Assistive Technologie ab und erfüllen gemeinsam Anforderungen wie Text-zu-Sprache、Sprachsynthese、Voiceover. Sie eignen sich für Nutzer, die zuerst ähnliche Anwendungsszenarien vergleichen möchten.
tts4free unterscheidet sich von AnyToSpeech in: Das Preismodell ist Kostenlos.
Match score: 24
Monatliche Besuche: 2.7K