WhisperUI
Website besuchen
WhisperUI Übersicht
WhisperUI ist eine umfassende und flexible Plattform, die die leistungsstarken Whisper- und Text-to-Speech-Modelle von OpenAI nutzt, um hochwertige Audio-Transkriptions- und Stimmgenerierungsdienste anzubieten. Sie richtet sich mit ihrem dualen Angebot an eine breite Palette von Nutzern: eine benutzerfreundliche Weboberfläche und eine leistungsstarke eigenständige Desktop-Anwendung. Dieser duale Ansatz ermöglicht es den Nutzern, zwischen dem Komfort eines Cloud-basierten Dienstes und der Privatsphäre und unbegrenzten Nutzung der lokalen Verarbeitung zu wählen.
Die Webversion von WhisperUI bietet sowohl Speech-to-Text (S2T)- als auch Text-to-Speech (T2S)-Funktionen. Sie funktioniert nach dem "Bring Your Own Key" (BYOK)-Modell, bei dem die Nutzer ihren OpenAI-API-Schlüssel verbinden und direkt an OpenAI für ihre Nutzung bezahlen, was sie zu einer sehr kostengünstigen Lösung macht. Die kostenlose Stufe unterstützt die grundlegende Transkription, während Premium-Funktionen wie der Stapel-Upload von Dateien und die Erstellung von SRT-Untertiteldateien freigeschaltet werden. Der T2S-Dienst ermöglicht es den Nutzern, Text in lebensechte Sprache umzuwandeln und bietet eine Auswahl an Stimmen und Qualitätsmodellen.
Für Nutzer, die Datenschutz priorisieren, große Dateien bearbeiten oder unbegrenzte Transkriptionen benötigen, ist die WhisperUI Desktop-Anwendung die ideale Lösung. Diese abonnementbasierte Software läuft lokal auf Windows- und macOS-Geräten und stellt sicher, dass alle Audiodaten auf dem Computer des Nutzers bleiben. Sie hebt die Beschränkungen für Dateigröße und -dauer auf, bietet unbegrenzte Transkriptionen zu einer festen monatlichen Gebühr und unterstützt sogar die GPU-Beschleunigung (NVIDIA und AMD) für deutlich schnellere Verarbeitungsgeschwindigkeiten.
Wie man WhisperUI verwendet
Die Verwendung von WhisperUI ist unkompliziert, mit unterschiedlichen Schritten für die Web- und Desktop-Versionen:
Für webbasiertes Speech-to-Text:
- Navigieren Sie zur WhisperUI-Website.
- Geben Sie Ihren OpenAI-API-Schlüssel an. Ihr Schlüssel wird aus Sicherheitsgründen lokal in Ihrem Browser gespeichert.
- Ziehen Sie Ihre Audiodatei (z. B. mp3, wav, m4a) per Drag & Drop in den dafür vorgesehenen Bereich oder durchsuchen Sie sie, um sie auszuwählen.
- Das Tool verarbeitet das Audio mit OpenAI Whisper und zeigt den transkribierten Text an.
- Premium-Nutzer können mehrere Dateien auf einmal hochladen und die Transkription als Text- oder SRT-Datei exportieren.
Für webbasiertes Text-to-Speech:
- Gehen Sie zum Text-to-Speech-Bereich auf der Website.
- Geben Sie Ihren OpenAI-API-Schlüssel ein.
- Wählen Sie Ihre gewünschte Stimme (z. B. Alloy, Echo, Nova) und das Qualitätsmodell (TTS-1 oder TTS-1-HD).
- Geben oder fügen Sie den Text, den Sie umwandeln möchten, in das Textfeld ein.
- Klicken Sie auf "Sprache generieren", um die Audiodatei zu erstellen und herunterzuladen.
Für die Desktop-App:
- Abonnieren Sie den WhisperUI Desktop-Plan auf der Website.
- Laden Sie die Anwendung herunter und installieren Sie sie auf Ihrem Windows- oder macOS-Computer.
- Kopieren Sie Ihren Lizenzschlüssel aus Ihren Kontoeinstellungen und fügen Sie ihn in die Desktop-App ein.
- Sie können nun eine beliebige Anzahl von Audiodateien beliebiger Größe per Drag & Drop für die lokale Transkription ziehen, wobei die Ausgabe direkt auf Ihrem Gerät generiert wird.
Kernfunktionen von WhisperUI
- Hochpräzise Transkription: Angetrieben durch das Whisper-Modell von OpenAI, das für seine Robustheit gegenüber Akzenten, Hintergrundgeräuschen und Fachsprache bekannt ist.
- Text-to-Speech-Generierung: Wandelt Text in natürlich klingendes Audio mit einer Vielzahl von Stimmen und zwei Qualitätsstufen (TTS-1 und TTS-1-HD) um.
- Duale Plattform: Bietet sowohl eine flexible Weboberfläche als auch eine private, leistungsstarke Desktop-Anwendung.
- Lokale Verarbeitung: Die Desktop-App verarbeitet alle Daten lokal und gewährleistet maximale Datensicherheit und -privatsphäre.
- Unbegrenzte Nutzung (Desktop): Die Desktop-Version hat keine Beschränkungen hinsichtlich Dateigröße, Sprachdauer oder Anzahl der Transkriptionen.
- GPU-Beschleunigung: Experimentelle Unterstützung für NVIDIA- und AMD-GPUs in der Desktop-App für schnellere Leistung.
- Export von SRT-Dateien: Premium-Webfunktion zur direkten Erstellung von Untertiteldateien aus Audio.
- Stapelverarbeitung: Die Premium-Webversion ermöglicht das gleichzeitige Hochladen und Transkribieren mehrerer Dateien.
- Breite Dateiformatunterstützung: Kompatibel mit gängigen Audio- und Videoformaten wie mp3, mp4, mpeg, m4a, wav, ogg und webm.
Anwendungsfälle für WhisperUI
Content-Ersteller: Transkribieren von Podcasts, Interviews und Videoinhalten zur Erstellung von Untertiteln, Shownotes und Blogartikeln, um die Zugänglichkeit und SEO zu verbessern.
Journalisten und Forscher: Schnelles Umwandeln von aufgezeichneten Interviews, Vorlesungen und Feldnotizen in Text zur Analyse, Zitation und Berichterstattung.
Studenten und Lehrende: Transkribieren von Vorlesungen für Studiennotizen oder Erstellen von Audioversionen von schriftlichen Materialien für unterschiedliche Lernstile.
Geschäftsleute: Erstellen genauer Protokolle von Meetings, Telefonkonferenzen und Sprachnotizen zur Dokumentation und für Folgemaßnahmen.
Entwickler: Nutzung der Text-to-Speech-Funktion zur Erstellung von Voiceovers für Anwendungen, Videos oder E-Learning-Module.
Vorteile von WhisperUI
- Flexibilität: Nutzer können zwischen Pay-as-you-go-Cloud-Verarbeitung oder einem Abonnement mit Pauschalgebühr für unbegrenzte lokale Verarbeitung wählen.
- Kosteneffizienz: Das BYOK-Modell der Webversion vermeidet Aufschläge und ermöglicht es den Nutzern, die Basistarife von OpenAI zu bezahlen. Die Desktop-App bietet vorhersehbare, erschwingliche Preise für Vielnutzer.
- Erhöhte Privatsphäre: Die Desktop-Anwendung ist ein großer Vorteil für Nutzer, die mit sensiblen oder vertraulichen Informationen umgehen, da keine Daten in die Cloud gesendet werden.
- Leistung und Kontrolle: Durch die Nutzung der fortschrittlichen Modelle von OpenAI und die Bereitstellung lokaler GPU-Beschleunigung gibt WhisperUI den Nutzern leistungsstarke Werkzeuge mit einem hohen Maß an Kontrolle über ihren Arbeitsablauf und ihre Daten.
- Benutzerfreundliche Oberfläche: Die einfache Drag-and-Drop-Funktionalität macht es für Nutzer aller technischen Niveaus zugänglich.
Preise und Pläne
WhisperUI bietet mehrere unterschiedliche Preisstrukturen:
- Web Speech-to-Text (Freemium/BYOK): Der grundlegende Web-Transkriptionsdienst ist kostenlos. Nutzer müssen ihren eigenen OpenAI-API-Schlüssel bereitstellen und werden direkt von OpenAI für die Transkriptionsnutzung abgerechnet. Premium-Funktionen wie Stapel-Uploads und SRT-Export erfordern möglicherweise einen zusätzlichen Kauf oder ein Abonnement.
- Web Text-to-Speech (Pay-as-you-go/BYOK): Dieser Dienst erfordert ebenfalls den OpenAI-API-Schlüssel des Nutzers. Die Abrechnung erfolgt direkt von OpenAI basierend auf der Anzahl der Zeichen: 0,015 $ pro 1.000 Zeichen für das TTS-1-Modell und 0,030 $ pro 1.000 Zeichen für das TTS-1-HD-Modell.
- WhisperUI Desktop (Abonnement): Dies ist ein kostenpflichtiges Abonnement zum Preis von 8 $/Monat (Aktionspreis). Die Lizenz gewährt den Zugriff auf die Desktop-App für ein Gerät und bietet unbegrenzte lokale Transkriptionen, erhöhte Privatsphäre, keine Dateigrößenbeschränkungen und GPU-Unterstützung.
WhisperUI Kommentare (0)
Melden Sie sich an, um einen Kommentar zu hinterlassen
Jetzt anmeldenWhisperUIWebsite-Traffic-Analyse
Aktueller Traffic-Status
Status
Monatlicher Traffic-Trend
Standort
Top 5 Länder/Regionen
-
🇺🇸 United States24,17%
-
🇻🇳 Vietnam24,01%
-
🇮🇹 Italy18,42%
-
🇷🇺 Russia17,35%
-
🇫🇷 France16,05%
Beliebte Keywords
| Keyword | Kosten pro Klick |
|---|---|
|
$0,00
|
|
|
$0,00
|
|
|
$2,84
|
|
|
$0,00
|
|
|
$0,00
|
WhisperUI Alternativen
Alle anzeigen
Speech Studio
Speech Studio ist eine umfassende Suite von KI-gestützten Tools von Microsoft Azure, die es Entwicklern ermöglicht, Anwendungen mit …
Speech Studio ist eine umfassende Suite von KI-gestützten Tools von Microsoft Azure, die es Entwicklern ermöglicht, Anwendungen mit fortschrittlichen Sprachfunktionen zu erstellen. Es bietet hochpräzise Sprache-zu-Text-Umwandlung, natürlich klingende Text-zu-Sprache-Synthese, Echtzeit-Sprachübersetzung und Sprechererkennung. Benutzer können benutzerdefinierte Sprachmodelle und Konversationsschnittstellen erstellen, was es zu einer vielseitigen Plattform für eine breite Palette von sprachgesteuerten Lösungen macht.
AIFreeforever
AIFreeforever ist eine umfassende Plattform, die über 700 kostenlose KI-Tools für Bildgenerierung, Chatbots, Text-to-Speech, Transkription, Schreiben und mehr …
AIFreeforever ist eine umfassende Plattform, die über 700 kostenlose KI-Tools für Bildgenerierung, Chatbots, Text-to-Speech, Transkription, Schreiben und mehr bietet. Es erfordert keine Anmeldung, Registrierung oder Kreditkarte und bietet unbegrenzten Zugang zu fortschrittlichen KI-Funktionen für Content-Ersteller, Studenten und Fachleute.
FreeTTS
FreeTTS ist ein vielseitiges KI-gestütztes Audio-Toolkit, das eine Reihe von kostenlosen und Premium-Diensten anbietet. Es zeichnet sich durch …
FreeTTS ist ein vielseitiges KI-gestütztes Audio-Toolkit, das eine Reihe von kostenlosen und Premium-Diensten anbietet. Es zeichnet sich durch die Umwandlung von Text in natürlich klingende Sprache mit einer breiten Palette von menschenähnlichen Stimmen aus. Neben TTS bietet es hochpräzise Sprache-zu-Text-Transkription, einen KI-Vokal-Entferner, einen Stimmverbesserer und verschiedene Audio-Bearbeitungswerkzeuge wie einen Konverter, Cutter und Joiner. Es ist eine All-in-One-Lösung für Content-Ersteller, Musiker und alle, die eine hochwertige Audioverarbeitung benötigen.
freesubtitles.ai
Ein KI-gestütztes Tool, das kostenlose und kostenpflichtige Dienste zur hochpräzisen Transkription von Audio und Video in Text anbietet. …
Ein KI-gestütztes Tool, das kostenlose und kostenpflichtige Dienste zur hochpräzisen Transkription von Audio und Video in Text anbietet. Es unterstützt über 111 Sprachen für die Transkription und 91 für die Übersetzung und nutzt Modelle wie Whisper von OpenAI. Bezahlte Funktionen umfassen höhere Limits, API-Zugang und schnellere Verarbeitung.

askeygeek
askeygeek ist eine All-in-One-KI-Produktivitätsplattform, die über ein einziges, erschwingliches Konto Zugriff auf über 1000 Top-KI-Modelle (von OpenAI, Claude, …
askeygeek ist eine All-in-One-KI-Produktivitätsplattform, die über ein einziges, erschwingliches Konto Zugriff auf über 1000 Top-KI-Modelle (von OpenAI, Claude, Stability usw.) und über 1500 kostenlose Web-Tools bietet. Es integriert Text-to-Speech, Transkription, Inhaltserstellung und verschiedene Entwickler-Dienstprogramme, um die Arbeitsabläufe für Kreative, Vermarkter und Entwickler zu optimieren.
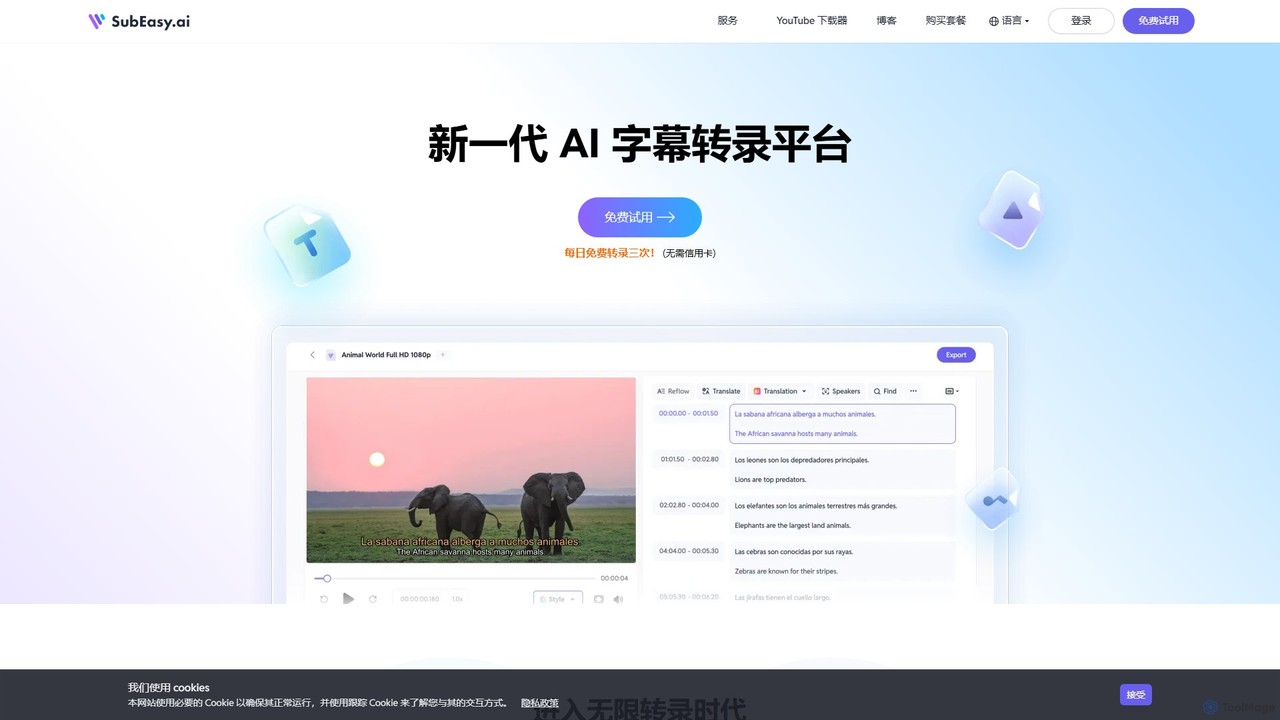
SubEasy
SubEasy ist eine KI-Plattform der nächsten Generation für die Transkription von Video und Audio, die Erstellung von Untertiteln …
SubEasy ist eine KI-Plattform der nächsten Generation für die Transkription von Video und Audio, die Erstellung von Untertiteln und die Übersetzung. Angetrieben von OpenAIs Whisper liefert es eine Genauigkeit von bis zu 99 %. Es unterstützt über 100 Sprachen, bietet eine einzigartige AI-Reflow-Funktion für perfekt getimte Untertitel und eine All-in-One-Lösung von der Transkription bis zum Videoexport, ideal für Content-Ersteller, Pädagogen und Unternehmen.
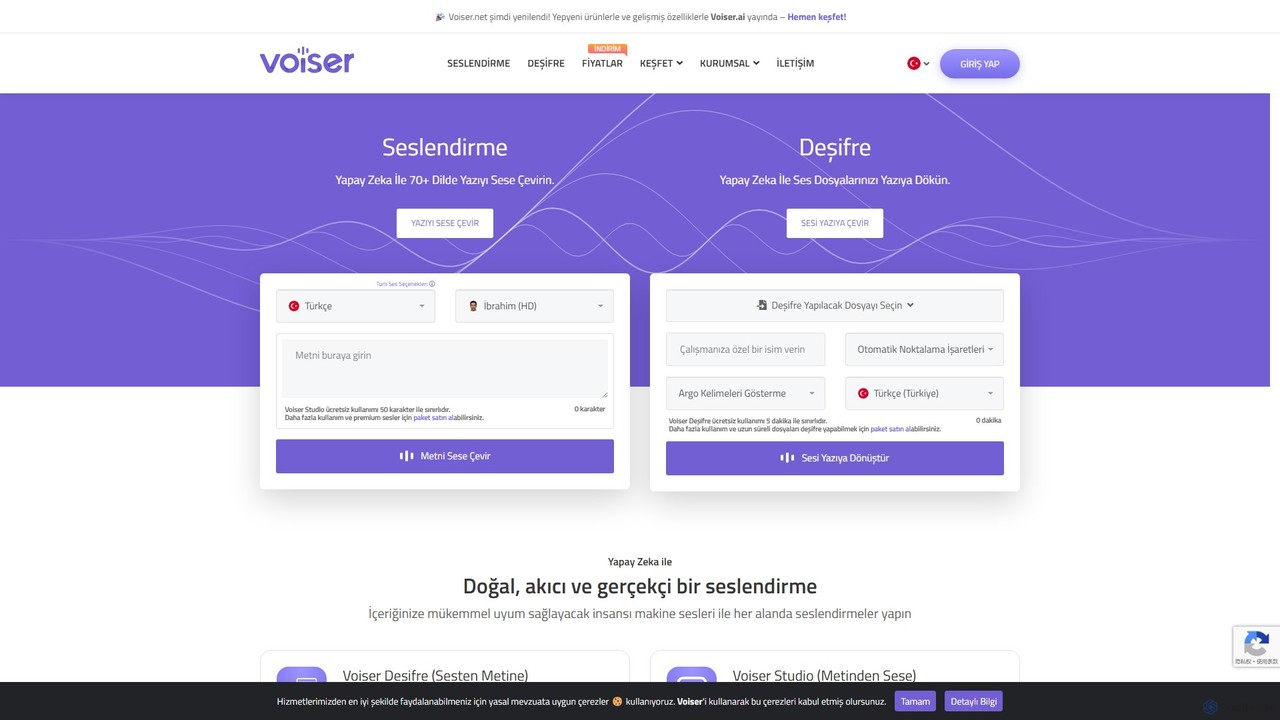
Voiser
Voiser ist eine fortschrittliche KI-Plattform, die hochwertige Text-to-Speech (TTS), präzise Speech-to-Text (Transkription) und innovative Stimmklon-Dienste anbietet. Mit Unterstützung …
Voiser ist eine fortschrittliche KI-Plattform, die hochwertige Text-to-Speech (TTS), präzise Speech-to-Text (Transkription) und innovative Stimmklon-Dienste anbietet. Mit Unterstützung für über 75 Sprachen und mehr als 550 Stimmen bietet es eine umfassende Suite von Werkzeugen für Content-Ersteller, Unternehmen und Entwickler, einschließlich sprechender Avatare, YouTube-Synchronisation und API-Integration.
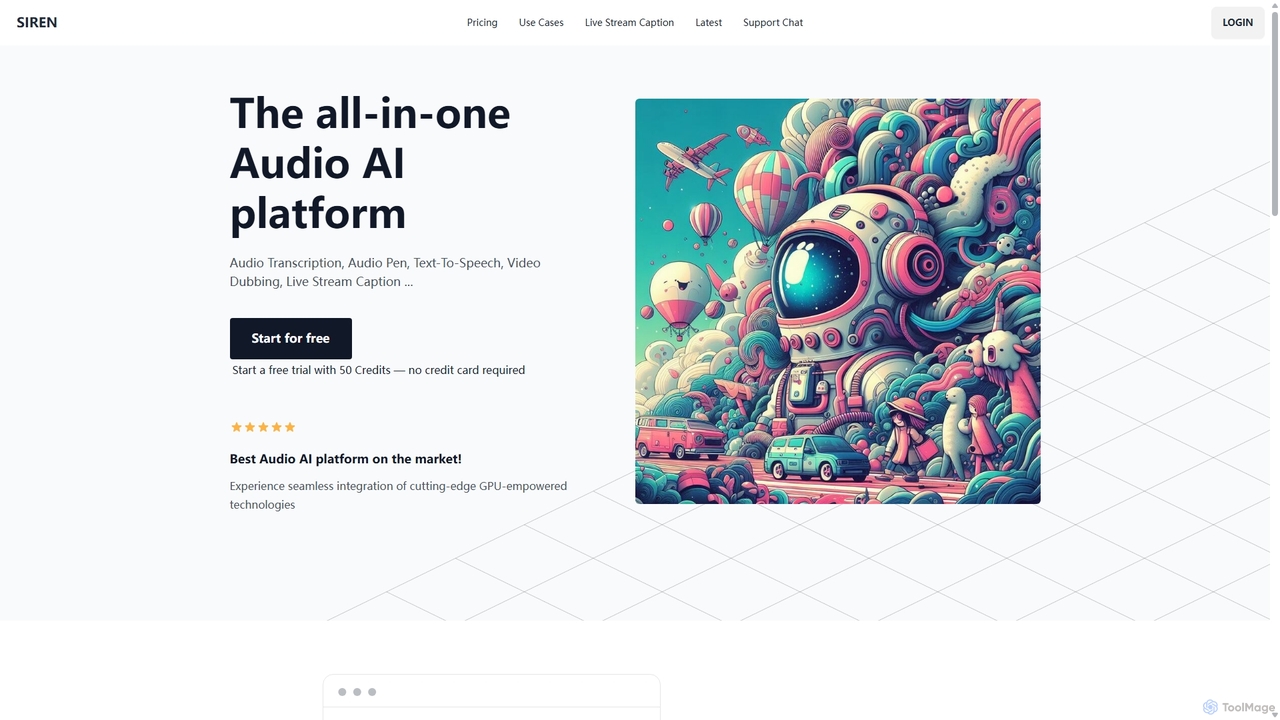
SIREN
SIREN ist eine All-in-One, GPU-beschleunigte KI-Audio-Plattform. Sie bietet hochpräzise Audiotranskription, natürliche Text-to-Speech-Funktion mit über 420 Stimmen, nahtlose Videovertonung …
SIREN ist eine All-in-One, GPU-beschleunigte KI-Audio-Plattform. Sie bietet hochpräzise Audiotranskription, natürliche Text-to-Speech-Funktion mit über 420 Stimmen, nahtlose Videovertonung in über 100 Sprachen und Echtzeit-Untertitelung für Live-Streams. Entwickelt für Kreative, Marketer und Unternehmen, vereinfacht SIREN komplexe Audioaufgaben in einem einzigen, effizienten Workflow.
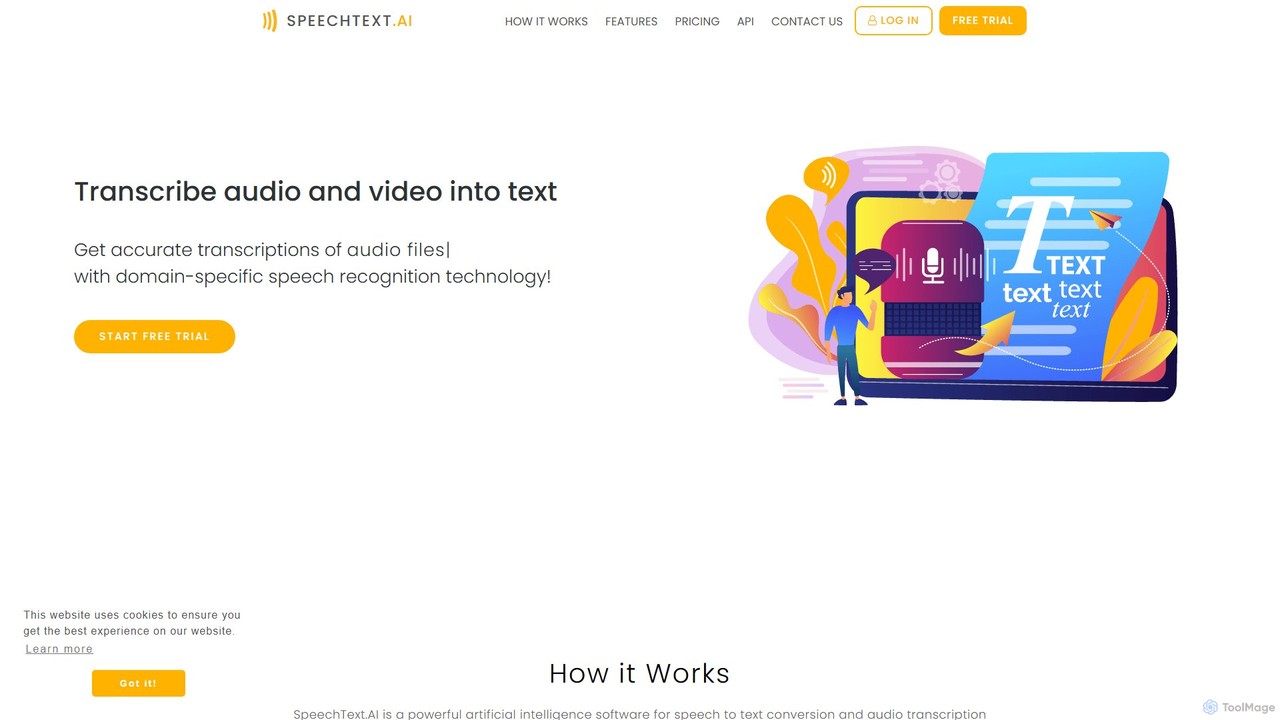
SpeechText.AI
SpeechText.AI ist ein fortschrittlicher KI-gestützter Transkriptionsdienst, der Audio- und Videodateien automatisch in präzisen Text umwandelt. Er unterstützt über …
SpeechText.AI ist ein fortschrittlicher KI-gestützter Transkriptionsdienst, der Audio- und Videodateien automatisch in präzisen Text umwandelt. Er unterstützt über 30 Sprachen, bietet Sprechererkennung und generiert Untertitel (SRT-Dateien). Ideal für Content-Ersteller, Pädagogen und Unternehmen, die die Zugänglichkeit und Workflow-Effizienz verbessern möchten.
SpeechGen
SpeechGen ist ein leistungsstarkes KI-Tool zur Erstellung realistischer Text-to-Speech (TTS)-Voiceovers und zur Transkription von Video-/Audiodateien in Text. Es …
SpeechGen ist ein leistungsstarkes KI-Tool zur Erstellung realistischer Text-to-Speech (TTS)-Voiceovers und zur Transkription von Video-/Audiodateien in Text. Es bietet über 1000 natürlich klingende Stimmen in über 150 Sprachen, umfangreiche Anpassungsoptionen und ein einzigartiges Pay-as-you-go-Preismodell. Ideal für Content-Ersteller, Vermarkter und Entwickler, unterstützt es die kommerzielle Nutzung und lässt sich nahtlos in verschiedene Plattformen integrieren.
WhisperUI Kategorie
WhisperUI Tags
WhisperUI KI-Tool
WhisperUI Einbettungsfunktion
Kopieren Sie einfach den Einbettungscode unten und fügen Sie das ansprechende Abzeichen in Ihren Blog, Artikel oder auf die offizielle Website Ihrer App ein, um den Traffic direkt auf die Detailseite dieses Tools zu leiten und so schnell die Sichtbarkeit und Nutzerzahlen zu steigern!

Noch keine Kommentare, seien Sie der Erste!