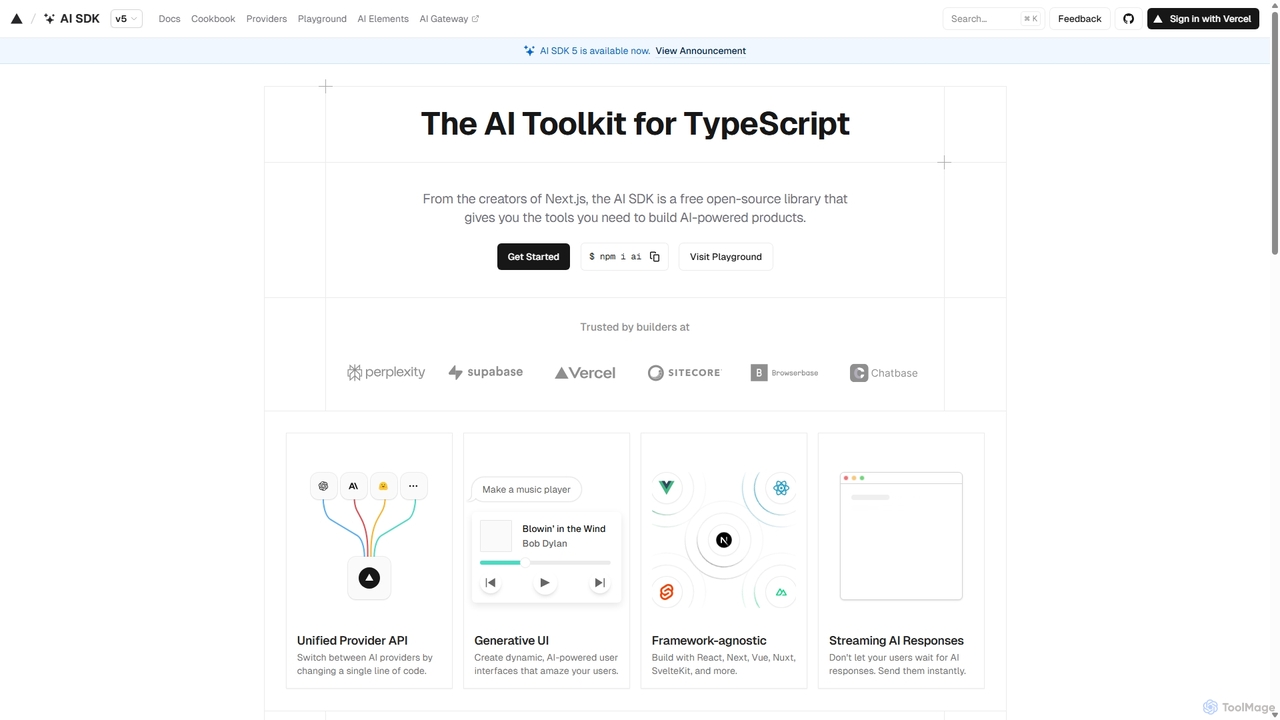
AI SDK
AI SDK de Vercel es un kit de herramientas TypeScript gratuito y de código abierto diseñado para ayudar …
AI SDK de Vercel es un kit de herramientas TypeScript gratuito y de código abierto diseñado para ayudar a los desarrolladores a crear aplicaciones impulsadas por IA. Proporciona una API unificada para integrarse sin problemas con varios modelos de lenguaje grandes como OpenAI, Anthropic y Google Gemini. El SDK es independiente del framework, compatible con React, Next.js, Vue, Svelte y más, lo que permite la creación de funciones como respuestas en streaming e interfaces de usuario generativas con un esfuerzo mínimo.

EasyFunctionCall
Una plataforma centrada en el desarrollador diseñada para simplificar la integración de llamadas a funciones y conexiones API …
Una plataforma centrada en el desarrollador diseñada para simplificar la integración de llamadas a funciones y conexiones API para Modelos de Lenguaje Grandes (LLMs). Abstrae la complejidad de construir agentes de IA y aplicaciones que pueden interactuar con herramientas y fuentes de datos externas, permitiendo un desarrollo más rápido y un rendimiento más robusto. Soporta los principales LLMs como GPT, Gemini y Claude.

TUGADOT
TUGADOT es una agencia de desarrollo de software a medida e integración de IA. Se asocian con empresas …
TUGADOT es una agencia de desarrollo de software a medida e integración de IA. Se asocian con empresas para transformar ideas en soluciones tecnológicas potentes y personalizadas, incluyendo aplicaciones web/móviles, desarrollo de MVP y sistemas avanzados de IA.
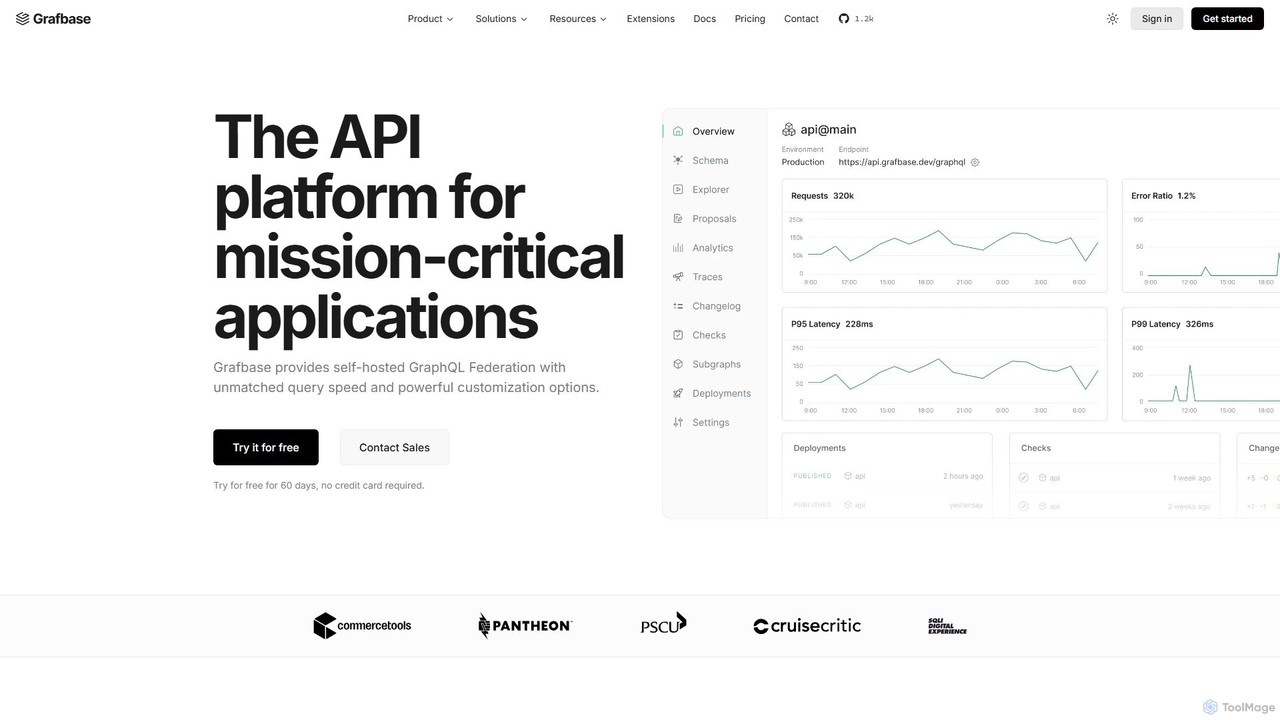
Grafbase
Grafbase es una plataforma de API de nivel empresarial para escalar la Federación GraphQL. Proporciona una puerta de …
Grafbase es una plataforma de API de nivel empresarial para escalar la Federación GraphQL. Proporciona una puerta de enlace autoalojada de alto rendimiento construida con Rust, que ofrece una velocidad y seguridad inigualables. Una característica clave es su soporte nativo para el Protocolo de Contexto de Modelo (MCP), que permite a los agentes de IA consultar sus API utilizando lenguaje natural, convirtiéndola en una solución preparada para el futuro para construir aplicaciones impulsadas por IA.
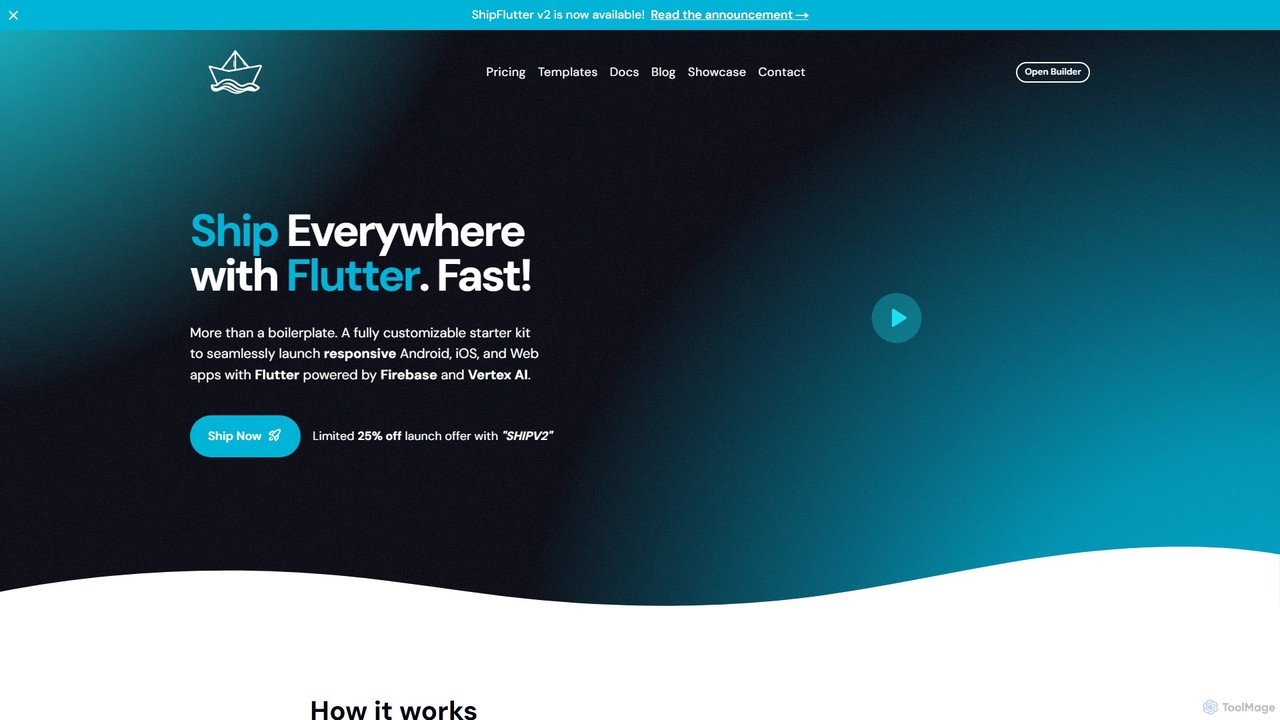
shipflutter
ShipFlutter es un kit de inicio impulsado por IA para que los desarrolladores construyan y lancen rápidamente aplicaciones …
ShipFlutter es un kit de inicio impulsado por IA para que los desarrolladores construyan y lancen rápidamente aplicaciones multiplataforma. Usando Flutter, Firebase y Vertex AI de Google, proporciona un boilerplate totalmente personalizable con módulos preconstruidos para autenticación, pagos, notificaciones y más. El constructor de IA ayuda a generar y configurar el código del proyecto, reduciendo significativamente el tiempo de desarrollo de meses a días. Está diseñado para crear aplicaciones responsivas para Android, iOS y web con características listas para producción.
Acerca de Integración de Modelos
Las herramientas de Integración de Modelos son plataformas que proporcionan una API unificada para acceder y gestionar diversos modelos de IA de diferentes proveedores. Estas herramientas actúan como una capa de middleware, abstrayendo las complejidades de las API de modelos individuales como las de OpenAI, Anthropic o alternativas de código abierto. Su valor principal es simplificar el desarrollo de aplicaciones impulsadas por IA, permitiendo un cambio de modelo sin interrupciones, optimizando costos y mejorando la fiabilidad de la aplicación. Al usar una única interfaz, los desarrolladores pueden evitar la dependencia de un solo proveedor y centrarse en construir funcionalidades en lugar de gestionar múltiples integraciones.
Características Clave
- API Unificada: Acceda a una amplia gama de LLMs y otros modelos de IA de múltiples proveedores a través de un único y consistente punto de acceso API.
- Enrutamiento Inteligente y Fallbacks: Dirija automáticamente las solicitudes al modelo más adecuado según el costo, la latencia o el rendimiento, con conmutación por error incorporada a un modelo de respaldo.
- Observabilidad y Gestión de Costos: Supervise el uso, rastree los gastos, analice métricas de rendimiento y establezca presupuestos para todos los modelos integrados en un panel centralizado.
- E/S Estandarizada: Normalice las entradas y salidas entre diferentes modelos, asegurando estructuras de datos consistentes para la lógica de su aplicación.
- Almacenamiento en Caché: Almacene y reutilice respuestas para solicitudes frecuentes para reducir la latencia y disminuir los costos de API.
Casos de Uso
Estas herramientas son esenciales para desarrolladores y equipos de producto que construyen aplicaciones que dependen de uno o más modelos de IA. Son particularmente valiosas en entornos de producción donde el rendimiento, el costo y la fiabilidad son críticos. Los escenarios comunes incluyen la construcción de chatbots multiproveedor, la realización de pruebas A/B con diferentes modelos para tareas específicas como resúmenes o generación de contenido, y la creación de sistemas resilientes que puedan soportar interrupciones de un solo proveedor.
Cómo Elegir
Al seleccionar una herramienta de Integración de Modelos, considere la amplitud de los modelos y proveedores compatibles. Evalúe la sofisticación de su lógica de enrutamiento y fallback. Valore la calidad de sus funciones de análisis y seguimiento de costos. Finalmente, examine la experiencia del desarrollador, incluida la calidad de la documentación, los SDK disponibles y la simplicidad del proceso de integración.
Integración de ModelosEscenario de uso
Construir un Chatbot de IA Independiente del Proveedor
Un desarrollador de una startup tiene la tarea de crear un chatbot de servicio al cliente que debe permanecer en línea 24/7 y ser rentable. En lugar de integrarse directamente con un único proveedor como OpenAI y arriesgarse a la dependencia del proveedor o a tiempos de inactividad, utiliza una herramienta de integración de modelos. Esto le permite configurar un modelo principal (p. ej., GPT-4) y un modelo secundario más económico (p. ej., un modelo de código abierto afinado) como respaldo. Si la API principal experimenta una interrupción o alta latencia, la herramienta redirige automáticamente el tráfico al modelo secundario, asegurando un servicio ininterrumpido y optimizando los costos durante las horas de menor actividad.
Pruebas A/B de Modelos para una Función de Resumen
Un gerente de producto en una empresa de EdTech quiere introducir una nueva función de resumen de texto. No está seguro de si usar un modelo premium de alto rendimiento o uno más económico. Usando una plataforma de integración de modelos, configura una prueba para enrutar el 50% de las solicitudes de los usuarios al Modelo A (premium) y el 50% al Modelo B (económico). El panel de observabilidad de la plataforma le permite comparar métricas clave lado a lado, incluyendo la latencia promedio, el costo por resumen y las tasas de error. Este enfoque basado en datos le ayuda a tomar una decisión informada sobre qué modelo proporciona el mejor equilibrio entre calidad y costo para sus usuarios.
Centralización del Acceso y Control de Costos de Modelos de IA
Una empresa tiene múltiples equipos de desarrollo que utilizan varios modelos de IA para diferentes proyectos, lo que lleva a una gestión descentralizada de claves API y costos impredecibles. El Jefe de Infraestructura de IA implementa una plataforma de integración de modelos como una puerta de enlace central. Todas las solicitudes de los desarrolladores ahora se enrutan a través de esta plataforma. Esto proporciona una vista unificada del uso de IA en toda la empresa, permite establecer límites de gasto globales y alertas, y simplifica la seguridad al gestionar todas las claves API en una ubicación segura. Estandariza la forma en que los equipos acceden a la IA, reduciendo el esfuerzo de ingeniería redundante y proporcionando una atribución de costos clara para cada proyecto.
Optimización de la Latencia con Enrutamiento Inteligente de Modelos
Un servicio de noticias financieras utiliza un modelo de IA para generar resúmenes de mercado en tiempo real. La baja latencia es crítica para sus usuarios. Utilizan una herramienta de integración de modelos con capacidades de enrutamiento inteligente. La herramienta sondea continuamente múltiples puntos finales de modelos (p. ej., diferentes proveedores o el mismo proveedor en diferentes regiones geográficas) para verificar la latencia más baja. Cuando un usuario solicita un resumen, la solicitud se envía automáticamente al modelo más rápido disponible en ese preciso momento. Este enrutamiento dinámico asegura que la aplicación siempre entregue la información lo más rápido posible, mejorando la experiencia del usuario sin requerir una lógica de red compleja y personalizada.
Simplificación del Desarrollo con E/S Estandarizada
Un equipo de software está construyendo una herramienta que permite a los usuarios generar contenido utilizando el modelo de IA de su elección. Cada proveedor de modelos (OpenAI, Anthropic, Google) tiene un formato de solicitud y respuesta de API ligeramente diferente. En lugar de escribir y mantener rutas de código separadas para cada modelo, el equipo utiliza una herramienta de integración de modelos. La herramienta proporciona un formato estandarizado tanto para enviar solicitudes (p. ej., un array universal de `messages`) como para recibir respuestas. Esta capa de abstracción reduce significativamente la complejidad del código y la sobrecarga de mantenimiento, permitiendo a los desarrolladores agregar soporte para nuevos modelos en minutos en lugar de días.
Reducción de Costos de API con Almacenamiento en Caché de Respuestas
Un popular sitio web de preguntas y respuestas utiliza un LLM para responder a las preguntas comunes de los usuarios. Notan que muchas preguntas son repetitivas, lo que resulta en llamadas a la API redundantes y costosas al proveedor del LLM. Para solucionar esto, integran una plataforma de integración de modelos que ofrece una capa de caché. La configuran para almacenar en caché las respuestas a preguntas idénticas por un período de 24 horas. Cuando un usuario hace una pregunta que ha sido respondida recientemente, la plataforma sirve la respuesta en caché al instante en lugar de llamar al LLM. Esta estrategia reduce drásticamente su factura mensual de API y mejora significativamente los tiempos de respuesta para las preguntas frecuentes.