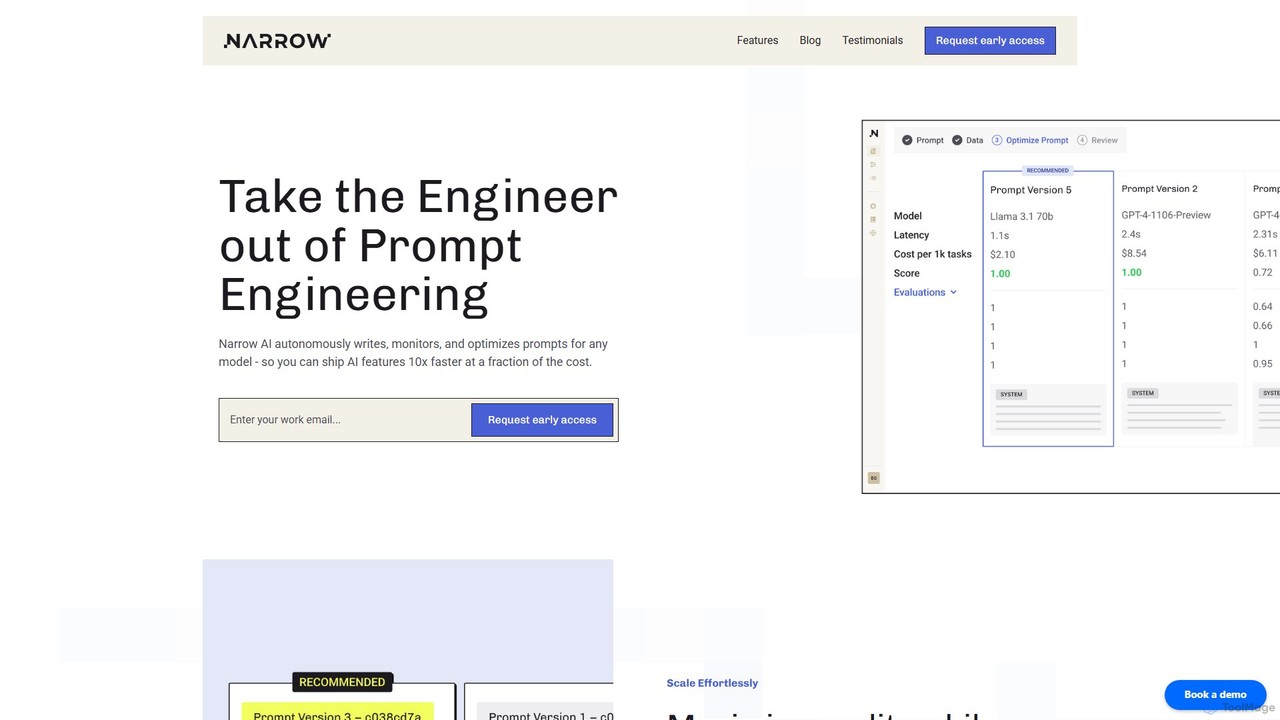
Narrow AI
Narrow AI es una plataforma de optimización de LLM para desarrolladores que automatiza la ingeniería de prompts y …
Narrow AI es una plataforma de optimización de LLM para desarrolladores que automatiza la ingeniería de prompts y la selección de modelos para reducir drásticamente los costos operativos de IA hasta en un 95%. Simplifica los flujos de trabajo, mejora la precisión y acelera el despliegue de funciones de IA de alta calidad y baja latencia.
Acerca de Optimización de Modelo
Las herramientas de optimización de modelos son una categoría especializada de software de infraestructura de IA diseñadas para hacer que los modelos de aprendizaje automático entrenados sean más pequeños, rápidos y eficientes energéticamente. Estas herramientas aplican técnicas como la cuantización, la poda y la destilación de conocimiento para reducir la huella computacional y de memoria de un modelo sin una pérdida significativa de precisión. Este proceso es crítico para desplegar IA compleja en hardware con recursos limitados, como teléfonos móviles o dispositivos IoT, y para reducir los costos operativos de los servicios de IA a gran escala en la nube. Cierran la brecha entre un modelo entrenado y su aplicación práctica en el mundo real.
Características Clave
- Cuantización: Reduce la precisión de los pesos del modelo (p. ej., de flotante de 32 bits a entero de 8 bits) para disminuir el tamaño y acelerar el cálculo.
- Poda (Pruning): Elimina sistemáticamente los pesos o conexiones menos importantes de la red neuronal para crear un modelo más pequeño y disperso.
- Destilación de Conocimiento: Entrena un modelo "estudiante" más pequeño y compacto para imitar el comportamiento de un modelo "profesor" más grande y complejo.
- Compilación de Modelos: Convierte un modelo en un formato ejecutable altamente optimizado y específico para el hardware de destino, como GPUs, TPUs o CPUs.
- Perfilado de Rendimiento: Analiza la ejecución de un modelo para identificar y resolver cuellos de botella de rendimiento relacionados con la velocidad, la memoria o el consumo de energía.
Casos de Uso
La optimización de modelos es esencial para ingenieros de MLOps, desarrolladores de IA e ingenieros de sistemas embebidos. Se utiliza ampliamente en industrias como la electrónica de consumo para la IA en el dispositivo, la automotriz para sistemas de percepción en tiempo real y la computación en la nube para gestionar los costos de inferencia de grandes modelos de lenguaje (LLM) y motores de recomendación. Cualquier aplicación que requiera una inferencia de IA eficiente se beneficia de estas herramientas.
Cómo Elegir
Al seleccionar una herramienta de optimización de modelos, considere su compatibilidad con sus frameworks de IA (p. ej., TensorFlow, PyTorch, ONNX). Evalúe su soporte para su hardware de destino, desde GPUs de servidor hasta NPUs móviles. Analice la gama de técnicas de optimización que ofrece y el grado de automatización frente al control manual proporcionado. Finalmente, analice su capacidad para gestionar el equilibrio entre las ganancias de rendimiento y la posible degradación de la precisión.
Optimización de ModeloEscenario de uso
Despliegue de modelos de IA en dispositivos de borde (Edge)
Un desarrollador de aplicaciones móviles necesita integrar una función de detección de objetos en tiempo real en su aplicación. El modelo original es demasiado grande y lento para funcionar sin problemas en un smartphone, lo que provoca un consumo excesivo de batería y una mala experiencia de usuario. Al utilizar una herramienta de optimización de modelos, el desarrollador aplica cuantización de 8 bits y poda al modelo. Esto reduce su tamaño en un 75% y triplica la velocidad de inferencia, permitiendo que la función se ejecute eficientemente en el dispositivo con un impacto mínimo en la duración de la batería, lo que posibilita una experiencia de usuario potente y receptiva.
Reducción de costos de inferencia en la nube para LLMs
Una startup tecnológica opera un popular servicio de chatbot impulsado por un gran modelo de lenguaje (LLM). El alto costo de los servidores GPU para la inferencia está afectando su rentabilidad. El equipo de MLOps utiliza un conjunto de herramientas de optimización de modelos para aplicar destilación de conocimiento y poda estructurada. Crean un modelo más pequeño y especializado que retiene el 98% del rendimiento del original en sus tareas específicas. Este modelo optimizado puede manejar 2.5 veces más usuarios concurrentes en el mismo hardware, reduciendo directamente su factura de infraestructura en la nube en más del 50% y mejorando la escalabilidad del servicio.
Habilitación de IA en tiempo real en sistemas automotrices
Un ingeniero automotriz está desarrollando un Sistema Avanzado de Asistencia al Conductor (ADAS) que utiliza una red neuronal para la detección de peatones. El sistema tiene requisitos de latencia estrictos: la decisión debe tomarse en milisegundos. El ingeniero utiliza una herramienta de compilación de modelos para convertir su modelo de PyTorch en un motor altamente optimizado para la GPU embebida específica del automóvil. El proceso de compilación fusiona capas y optimiza el acceso a la memoria, reduciendo la latencia de inferencia en un 60% y asegurando que el sistema cumpla con sus objetivos críticos de rendimiento en tiempo real para la seguridad.
Ajuste de modelos en microcontroladores de baja potencia
Un ingeniero de sistemas embebidos está diseñando un dispositivo doméstico inteligente con una función de detección de palabras clave. El hardware de destino es un microcontrolador diminuto con solo 256KB de RAM. El modelo inicial de TensorFlow Lite es demasiado grande para caber. Usando un kit de herramientas de optimización avanzada, el ingeniero aplica una poda de pesos agresiva y cuantización de enteros de 8 bits. Esto reduce el tamaño del modelo de 1MB a solo 180KB, permitiendo que se despliegue con éxito en el microcontrolador mientras mantiene más del 95% de precisión para las palabras clave objetivo, haciendo viable la función inteligente.
Aceleración de motores de recomendación de comercio electrónico
Un equipo de MLOps en una gran empresa de comercio electrónico gestiona un modelo de recomendación de aprendizaje profundo. Para proporcionar sugerencias en tiempo real, la latencia de inferencia debe ser extremadamente baja. Utilizan una herramienta de perfilado de rendimiento para identificar que capas específicas de su modelo son cuellos de botella computacionales en sus GPU de servidor. La herramienta de optimización sugiere optimizaciones específicas, incluida la compilación de estas capas con una precisión diferente (precisión mixta). Después de aplicar estos cambios, la latencia de extremo a extremo del servicio de recomendación se reduce en un 40%, lo que conduce a cargas de página más rápidas y un aumento medible en la participación del usuario y las ventas.
Optimización de modelos NLP para respuestas de API más rápidas
Una empresa de SaaS ofrece una API de resumen de texto. Los clientes se quejan de los lentos tiempos de respuesta para documentos grandes. El equipo de backend identifica el modelo de NLP como el cuello de botella. En lugar de reentrenar un nuevo modelo desde cero, utilizan la destilación de conocimiento. Entrenan un modelo Transformer más pequeño y rápido (el 'estudiante') para replicar la salida de su modelo grande y preciso (el 'profesor'). El nuevo modelo estudiante es 4 veces más rápido y se despliega en producción, reduciendo el tiempo de respuesta promedio de la API de 3 segundos a menos de 700 milisegundos, mejorando significativamente la satisfacción del cliente.