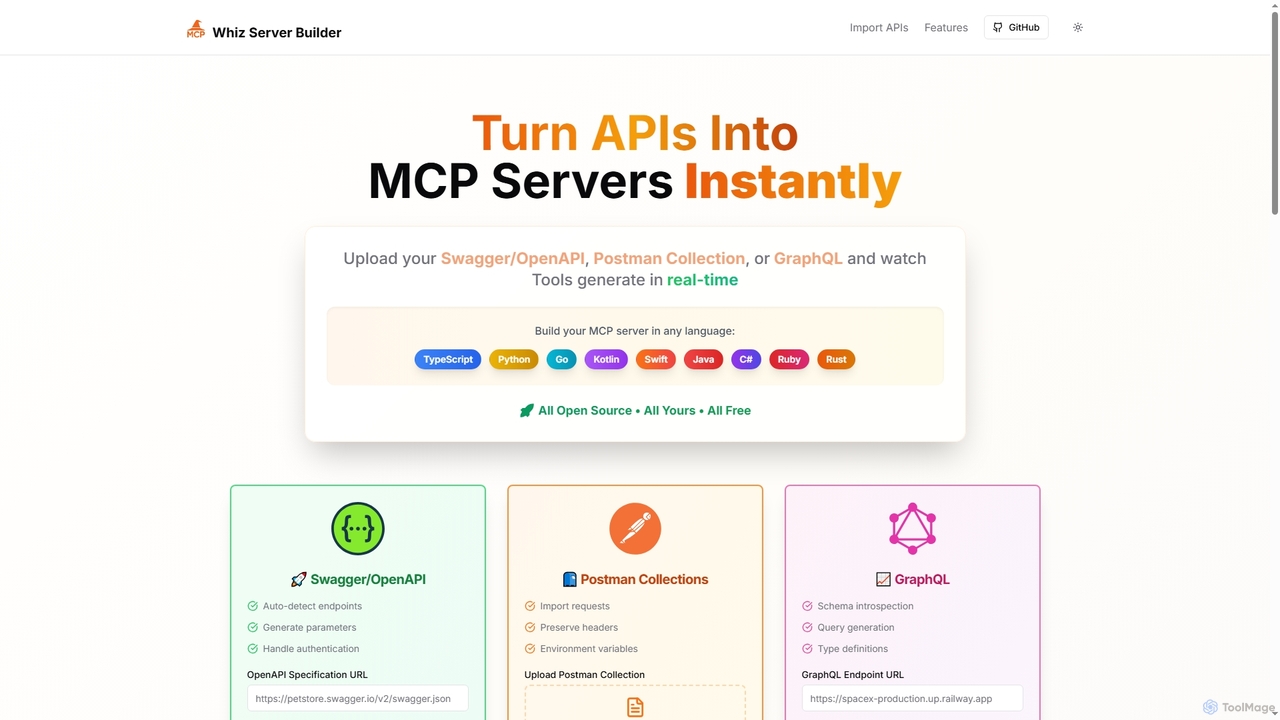
Mcpwhiz
Mcpwhiz es una herramienta de desarrollo gratuita y de código abierto que convierte instantáneamente especificaciones de API como …
Mcpwhiz es una herramienta de desarrollo gratuita y de código abierto que convierte instantáneamente especificaciones de API como Swagger/OpenAPI, Colecciones de Postman y GraphQL en servidores de Protocolo de Contexto de Modelo (MCP) listos para producción. Automatiza la generación de código en múltiples lenguajes, incluyendo TypeScript y Python, permitiendo a los desarrolladores construir aplicaciones conscientes del contexto con facilidad.
Acerca de Administración de Servidores
Las herramientas de administración de servidores con IA son una categoría especializada de software de infraestructura de IA que utiliza el aprendizaje automático para automatizar y optimizar el monitoreo, el mantenimiento y el rendimiento de los entornos de servidores. Estas herramientas analizan grandes cantidades de datos de telemetría, como registros, métricas y trazas, para identificar patrones, predecir fallos y automatizar tareas administrativas complejas. Su valor principal radica en transformar las operaciones del servidor de un modelo reactivo a uno proactivo, aumentando significativamente el tiempo de actividad, la seguridad y la eficiencia de los recursos. Al aprovechar el análisis predictivo, ayudan a prevenir problemas antes de que afecten a los usuarios y a optimizar la asignación de recursos para cargas de trabajo exigentes como el entrenamiento de modelos de IA.
Funciones Clave
- Análisis Predictivo de Fallos: Utiliza modelos de aprendizaje automático para analizar métricas y registros de hardware para pronosticar posibles fallos de componentes del servidor.
- Escalado Automatizado de Recursos: Ajusta de forma inteligente los recursos de cómputo, memoria y almacenamiento según las demandas de la carga de trabajo en tiempo real para optimizar el rendimiento y el costo.
- Detección de Anomalías con IA: Identifica patrones inusuales en los datos de rendimiento o seguridad que se desvían de las líneas de base normales, señalando posibles problemas o amenazas.
- Análisis de Causa Raíz (RCA) Automatizado: Correlaciona eventos en toda la pila de infraestructura para identificar automáticamente el origen de un problema, reduciendo el tiempo de solución.
- Optimización del Consumo de Energía: Analiza la utilización del servidor para gestionar los estados de energía y la distribución de la carga de trabajo, minimizando los costos de electricidad en los centros de datos.
Escenarios de Aplicación
Estas herramientas son esenciales para ingenieros de DevOps, equipos de MLOps, Ingenieros de Fiabilidad de Sitios (SRE) y administradores de TI que gestionan flotas de servidores a gran escala o de misión crítica. Son particularmente valiosas en entornos con clústeres de computación de alto rendimiento (HPC), aplicaciones nativas de la nube e infraestructura dedicada al entrenamiento y despliegue de modelos de IA, donde el rendimiento y la fiabilidad son primordiales.
Criterios de Selección
Al elegir una herramienta de administración de servidores con IA, considere sus capacidades de integración con su pila de monitoreo existente (por ejemplo, Prometheus, Datadog). Evalúe la sofisticación de sus modelos de IA para la predicción y detección de anomalías. Además, evalúe su compatibilidad con su infraestructura, ya sea local, en la nube o híbrida, y su soporte para hardware específico como las GPU.
Administración de ServidoresEscenario de uso
Mantenimiento Proactivo de Hardware en Centros de Datos
Un administrador de TI de una gran plataforma de comercio electrónico es responsable del mantenimiento de cientos de servidores físicos. Usando una herramienta de administración de servidores con IA, pueden ir más allá de las revisiones rutinarias programadas. La herramienta analiza continuamente datos de sensores de vibración, métricas de temperatura y tasas de error de E/S de disco. Predice que tres discos duros específicos en un clúster de base de datos crítico tienen una probabilidad del 85% de fallar en los próximos 30 días. Esto permite al administrador programar una ventana de mantenimiento para reemplazar los discos de forma proactiva, evitando una interrupción catastrófica durante un período de ventas pico y ahorrando horas de trabajo de recuperación de emergencia.
Asignación Dinámica de Recursos de GPU para MLOps
Un equipo de MLOps en un instituto de investigación gestiona un clúster compartido de costosos servidores GPU para múltiples experimentos de aprendizaje automático simultáneos. Una herramienta de administración de servidores con IA monitorea las solicitudes de recursos y la utilización real de cada trabajo de entrenamiento. Cuando detecta que un trabajo de alta prioridad está subutilizando sus GPU asignadas mientras otro está en cola, reasigna automáticamente los recursos de GPU inactivos. Esta programación dinámica asegura que el hardware de alto costo se utilice siempre de manera eficiente, reduciendo los tiempos de finalización de los experimentos hasta en un 30% y maximizando el retorno de la inversión en hardware.
Detección Automatizada de Amenazas de Seguridad
Una empresa de servicios financieros utiliza una herramienta de administración de servidores con IA para mejorar su postura de seguridad. La herramienta establece una línea de base del tráfico de red normal y la actividad del usuario para sus servidores críticos. Una noche, detecta una serie de intentos de inicio de sesión inusuales desde una dirección IP extranjera, seguidos de transferencias de datos inesperadas a un servidor externo. Este patrón se desvía significativamente de la norma establecida. El sistema marca automáticamente esto como una anomalía de alto riesgo, aísla el servidor afectado de la red y alerta al equipo de operaciones de seguridad, previniendo una posible brecha de datos antes de que ocurra un daño significativo.
Optimización de Costos de Cómputo en la Nube
Una startup que ejecuta toda su aplicación en un proveedor de nube pública quiere controlar sus crecientes costos de cómputo. Su equipo de DevOps implementa una herramienta de administración de servidores con IA que analiza los patrones de uso históricos de sus instancias de máquinas virtuales. La herramienta identifica que varias instancias grandes utilizadas para el procesamiento de datos están inactivas durante más de 18 horas al día. Recomienda un horario automatizado para apagar estas instancias durante las horas de menor actividad y reiniciarlas antes de que comience la jornada laboral. La implementación de esta única recomendación reduce su factura mensual de servidores en la nube en un 25% sin afectar el rendimiento de la aplicación.
Aceleración de la Respuesta a Incidentes con Análisis de Causa Raíz
Un Ingeniero de Fiabilidad de Sitios (SRE) recibe una alerta de que una API orientada al cliente está experimentando una alta latencia. En lugar de revisar manualmente los registros y paneles de docenas de microservicios, consulta su herramienta de administración de servidores con IA. La herramienta ya ha correlacionado el pico de latencia con un aumento anormal en el uso de memoria en un servidor de base de datos específico y una serie de consultas de ejecución lenta de un servicio recién implementado. Presenta una cadena causal clara, identificando las consultas defectuosas como la causa raíz. Esto reduce el tiempo medio de resolución (MTTR) de más de una hora a solo diez minutos.
Gestión de Flotas de Computación en el Borde Distribuidas
Una cadena minorista opera miles de pequeños nodos de servidor en sus tiendas para el punto de venta y la gestión de inventario. Monitorear manualmente esta flota distribuida es imposible. Utilizan una plataforma de administración de servidores con IA para supervisar centralmente la salud y el rendimiento de todos los dispositivos de borde. La IA puede detectar patrones indicativos de problemas específicos de la ubicación, como problemas de conectividad de red que afectan a un grupo de tiendas en una región. También puede automatizar la gestión de parches, implementando actualizaciones de seguridad de manera inteligente según la carga de trabajo del dispositivo para evitar interrumpir las operaciones de la tienda, asegurando que toda la flota de borde permanezca segura y operativa.