Llm Lab Three
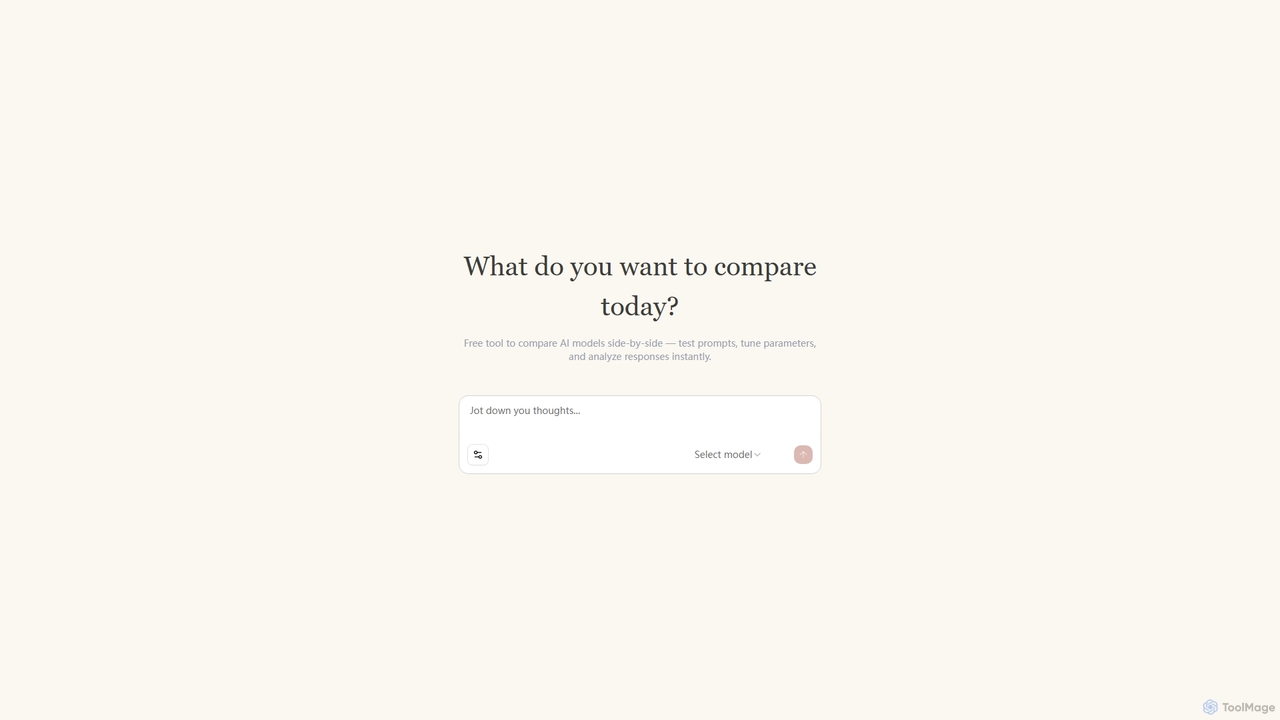
Una herramienta gratuita para que desarrolladores e investigadores comparen Grandes Modelos de Lenguaje (LLMs) lado a lado. Pruebe …
Una herramienta gratuita para que desarrolladores e investigadores comparen Grandes Modelos de Lenguaje (LLMs) lado a lado. Pruebe prompts, ajuste parámetros y analice respuestas al instante para encontrar el modelo óptimo para cualquier tarea.
Prompto
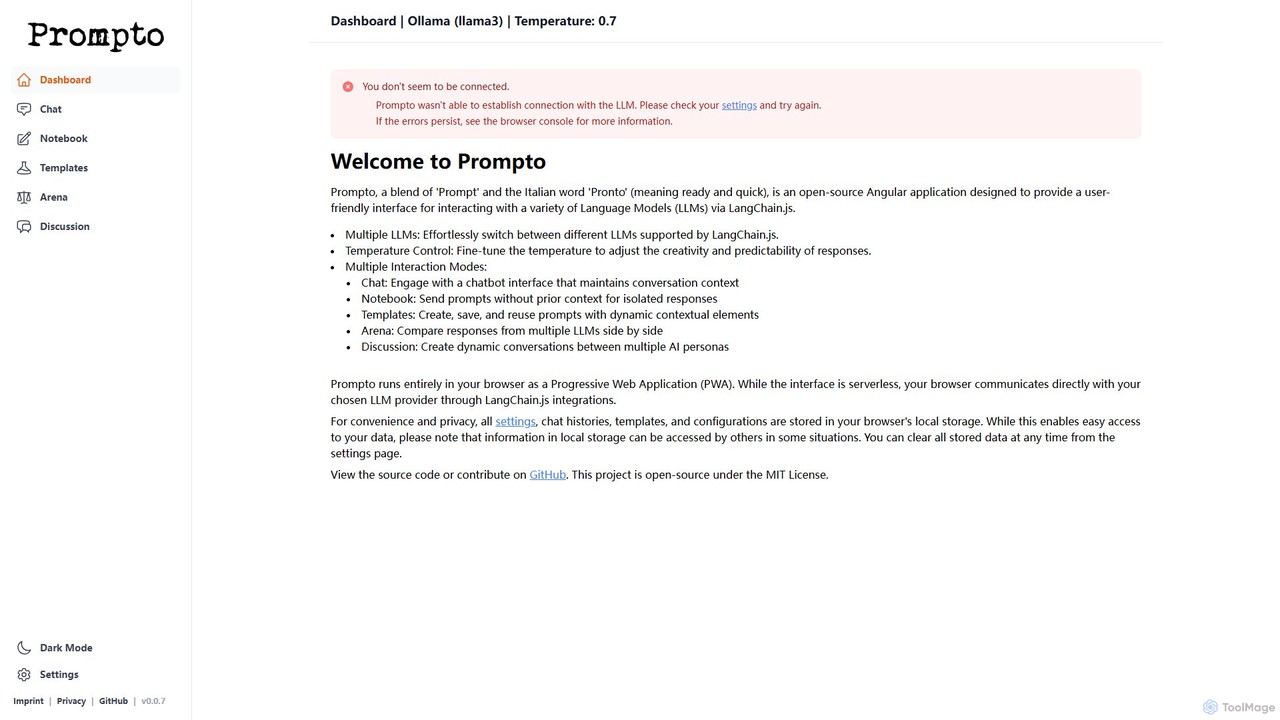
Prompto es una interfaz gratuita, de código abierto y basada en navegador para interactuar con una amplia gama …
Prompto es una interfaz gratuita, de código abierto y basada en navegador para interactuar con una amplia gama de Grandes Modelos de Lenguaje (LLMs). Utiliza LangChain.js para conectarse directamente a proveedores como OpenAI, Anthropic y modelos locales a través de Ollama, ofreciendo funciones avanzadas como una Arena de comparación de modelos, plantillas de prompts y discusiones multi-IA, todo mientras prioriza la privacidad del usuario al almacenar los datos localmente.
Choosy Chat
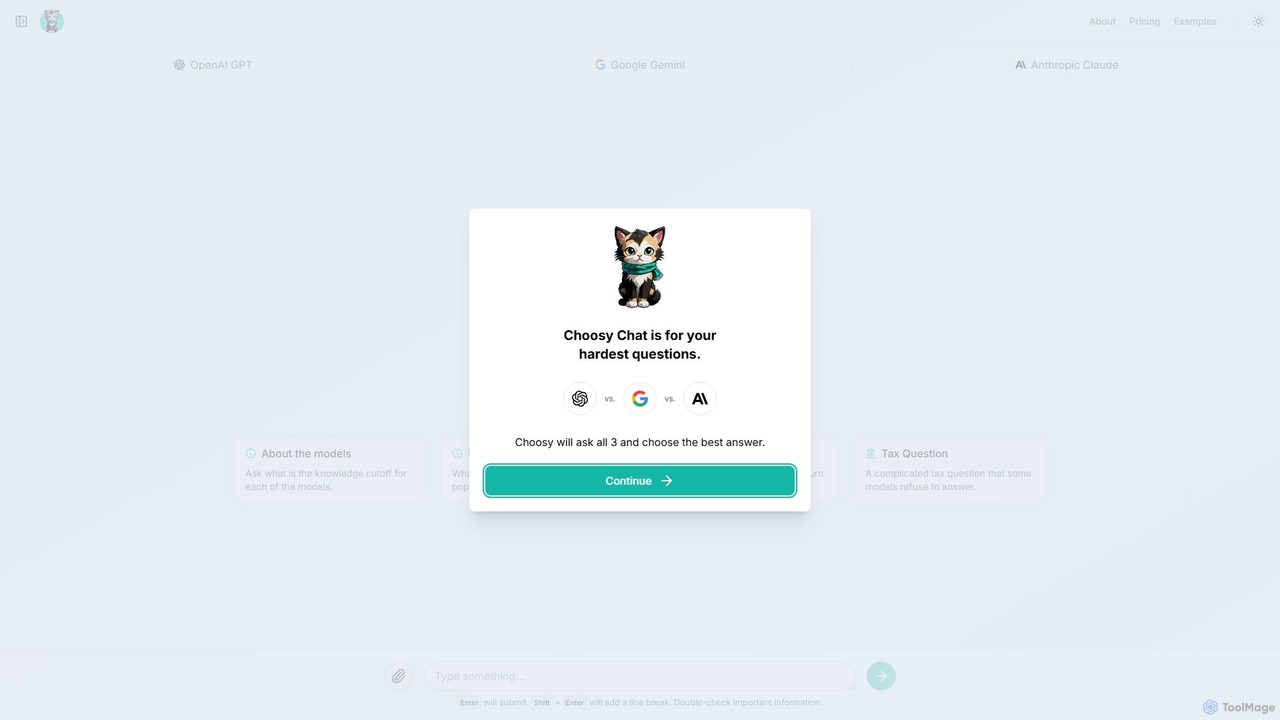
Choosy Chat es una herramienta de IA que envía simultáneamente tu prompt a GPT, Gemini y Claude, permitiéndote …
Choosy Chat es una herramienta de IA que envía simultáneamente tu prompt a GPT, Gemini y Claude, permitiéndote comparar sus respuestas lado a lado. Te ayuda a encontrar la mejor respuesta posible para cualquier consulta, desde codificación hasta escritura creativa.
Acerca de Comparación de Modelos
Las herramientas de Comparación de Modelos son plataformas especializadas para evaluar y comparar el rendimiento de diferentes modelos de IA de forma paralela. Estas herramientas proporcionan un entorno estructurado para probar modelos utilizando conjuntos de datos estandarizados, prompts personalizados e indicadores clave de rendimiento como precisión, velocidad y costo. Son esenciales para que desarrolladores, investigadores y empresas tomen decisiones basadas en datos al seleccionar el modelo de IA más adecuado para una aplicación específica. Esto permite un análisis objetivo más allá de las afirmaciones de marketing, garantizando un rendimiento y una rentabilidad óptimos.
Funciones Clave
- Interfaz de Comparación Paralela: Compare directamente los resultados de los modelos para el mismo prompt en una vista unificada.
- Benchmarking Automatizado: Ejecute pruebas estandarizadas (p. ej., MMLU, HellaSwag) para medir el rendimiento objetivo.
- Análisis de Costo y Latencia: Rastree los costos de API y los tiempos de respuesta para evaluar la eficiencia de diferentes modelos.
- Clasificaciones Cualitativas: Acceda a rankings generados por la comunidad o por expertos basados en la preferencia y calidad humana.
- Suites de Pruebas Personalizadas: Suba sus propios conjuntos de datos y prompts para evaluar modelos en tareas específicas de su dominio.
Casos de Uso
Estas herramientas son ampliamente utilizadas por desarrolladores de IA que seleccionan un modelo base para una nueva aplicación, equipos de MLOps que monitorean la degradación del modelo y gerentes de producto que comparan la relación costo-rendimiento de proveedores como OpenAI, Anthropic y Google. Los investigadores también las usan para validar el rendimiento de nuevos modelos frente a benchmarks establecidos.
Cómo Elegir
Al seleccionar una herramienta, considere la gama de modelos compatibles (código abierto vs. propietario), las métricas de evaluación y benchmarks disponibles, la capacidad de usar datos personalizados para las pruebas y si necesita una interfaz de usuario amigable, una API para automatización o ambas. Además, evalúe el modelo de precios para asegurarse de que se alinee con su volumen de pruebas.
Comparación de ModelosEscenario de uso
Selección de un LLM para un Chatbot de Servicio al Cliente
Un gerente de producto de una empresa de comercio electrónico necesita elegir un Modelo de Lenguaje Grande (LLM) para su nuevo chatbot de IA. Usando una herramienta de comparación de modelos, crea una suite de pruebas con 100 consultas comunes de clientes. Ejecuta esta suite en modelos como GPT-4, Claude 3 y Llama 3, comparándolos en precisión de respuesta, cortesía, latencia y costo por cada 1,000 consultas. La vista paralela de la plataforma revela que Claude 3 proporciona el mejor equilibrio entre calidad y costo para su caso de uso específico, permitiendo una decisión respaldada por datos en horas en lugar de semanas de pruebas manuales.
Benchmarking de un Modelo de Código Abierto Afin_x0002_ado
Un equipo de ingeniería de ML ha afinado un modelo Llama 3 con la base de conocimientos interna de su empresa. Para validar su efectividad, utilizan una plataforma de comparación de modelos para compararlo con el modelo base Llama 3 y GPT-4. Ejecutan pruebas estándar de la industria como MMLU para conocimientos generales y un conjunto de pruebas personalizado de 50 pares de preguntas y respuestas internas. Los resultados muestran que su modelo afinado supera al modelo base en un 30% en preguntas internas, justificando los recursos invertidos en el afinamiento.
Optimización de Costos para una Función de Contenido con IA
Una startup ofrece una función de IA que resume artículos para los usuarios. A medida que el crecimiento de usuarios se acelera, el costo de su actual API de modelo de gama alta se convierte en una preocupación. El equipo de desarrollo utiliza una herramienta de comparación de modelos para probar modelos más baratos y pequeños en su tarea de resumen. Comparan los resultados en cuanto a calidad, coherencia y longitud, mientras monitorean el panel de análisis de costos. Descubren un modelo más pequeño y destilado que ofrece el 95% de la calidad a solo el 40% del costo, mejorando significativamente sus márgenes de beneficio.
Pruebas A/B de Modelos de Generación de Imágenes para Marketing
Un equipo de marketing necesita generar visuales para una nueva campaña publicitaria. No están seguros de si usar Midjourney, Stable Diffusion o DALL-E 3 para la estética deseada. Usan una herramienta de comparación de modelos para introducir el mismo conjunto de prompts creativos en los tres modelos. La plataforma organiza los resultados, permitiendo al equipo votar y clasificar las imágenes generadas según la alineación con la marca, el atractivo visual y la creatividad. Este proceso estructurado les ayuda a identificar rápidamente que Stable Diffusion es el más adecuado para el estilo de su campaña.
Investigación Académica sobre Capacidades de Modelos
Un investigador universitario está estudiando las capacidades de razonamiento de los últimos modelos de IA. Utiliza la API de una plataforma de comparación de modelos para ejecutar programáticamente miles de acertijos lógicos y problemas matemáticos en una docena de modelos diferentes. La herramienta automatiza las pruebas, recopila los resultados y proporciona puntuaciones de precisión agregadas. Esto le ahorra al investigador cientos de horas de scripting y ejecución manual, permitiéndole centrarse en analizar los datos y publicar sus hallazgos sobre las tendencias de rendimiento de los modelos.
Elección de un Modelo de Generación de Código para Herramientas de Desarrollo
Una empresa que construye un plugin para IDE quiere añadir una función de autocompletado de código con IA. El líder de ingeniería necesita decidir entre modelos como GitHub Copilot (basado en GPT), Code Llama y otros modelos de codificación especializados. Utilizan una herramienta de comparación de modelos con una suite de benchmarks como HumanEval. Esto les permite medir objetivamente la capacidad de cada modelo para generar fragmentos de código correctos y eficientes en varios lenguajes de programación, asegurando que integran la opción más fiable y de mayor rendimiento para sus usuarios.