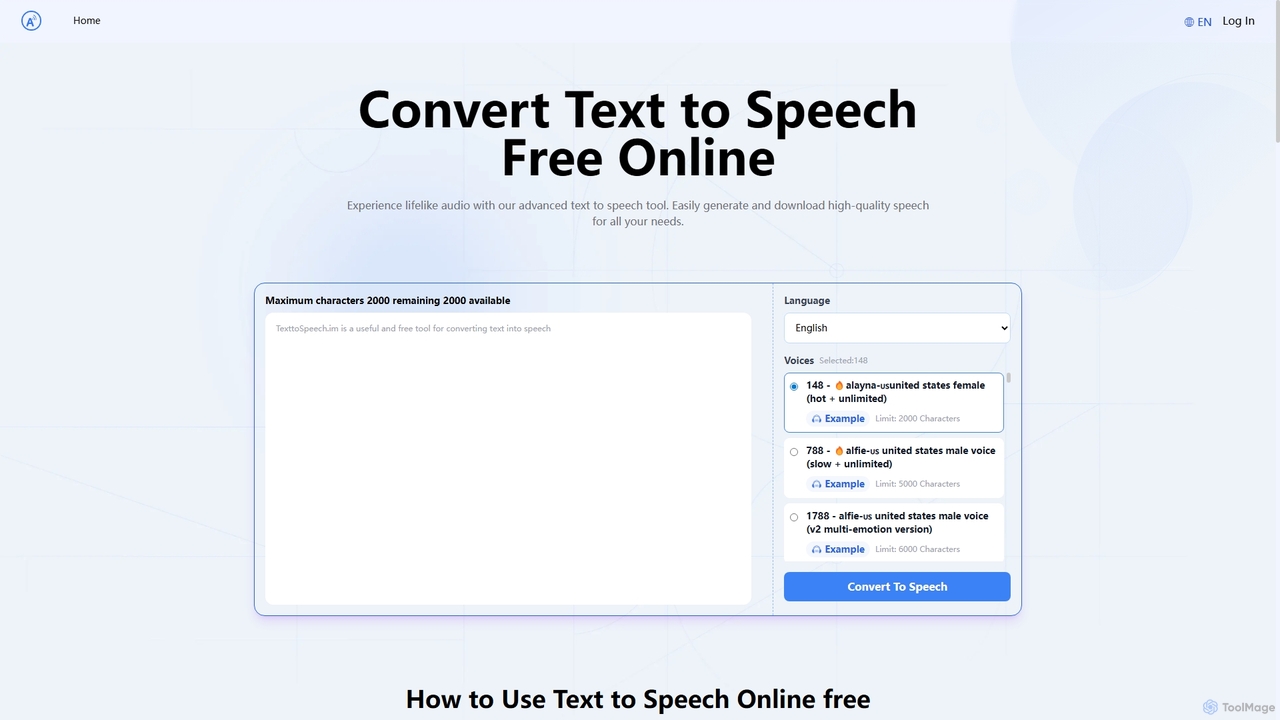
Text to Speech.im
Text to Speech.im es una herramienta de IA en línea gratuita que convierte texto en voz de sonido …
Text to Speech.im es una herramienta de IA en línea gratuita que convierte texto en voz de sonido natural. Admite una amplia gama de idiomas y voces, permitiendo a los usuarios generar audio de alta calidad para videos, e-learning, accesibilidad y más. Personaliza la velocidad y el volumen de la voz, y luego descarga fácilmente el audio generado como un archivo MP3.

Voice Isolator
Voice Isolator es una completa suite de audio impulsada por IA diseñada para una calidad de sonido impecable. …
Voice Isolator es una completa suite de audio impulsada por IA diseñada para una calidad de sonido impecable. Destaca en la eliminación de ruido de fondo, el aislamiento de voces e instrumentos de cualquier pista, la limpieza de grabaciones de voz para mayor claridad y la generación de voz con sonido natural a partir de texto. Ideal para podcasters, músicos y creadores de contenido que buscan un procesamiento de audio de nivel profesional con una interfaz web simple, rápida e intuitiva.
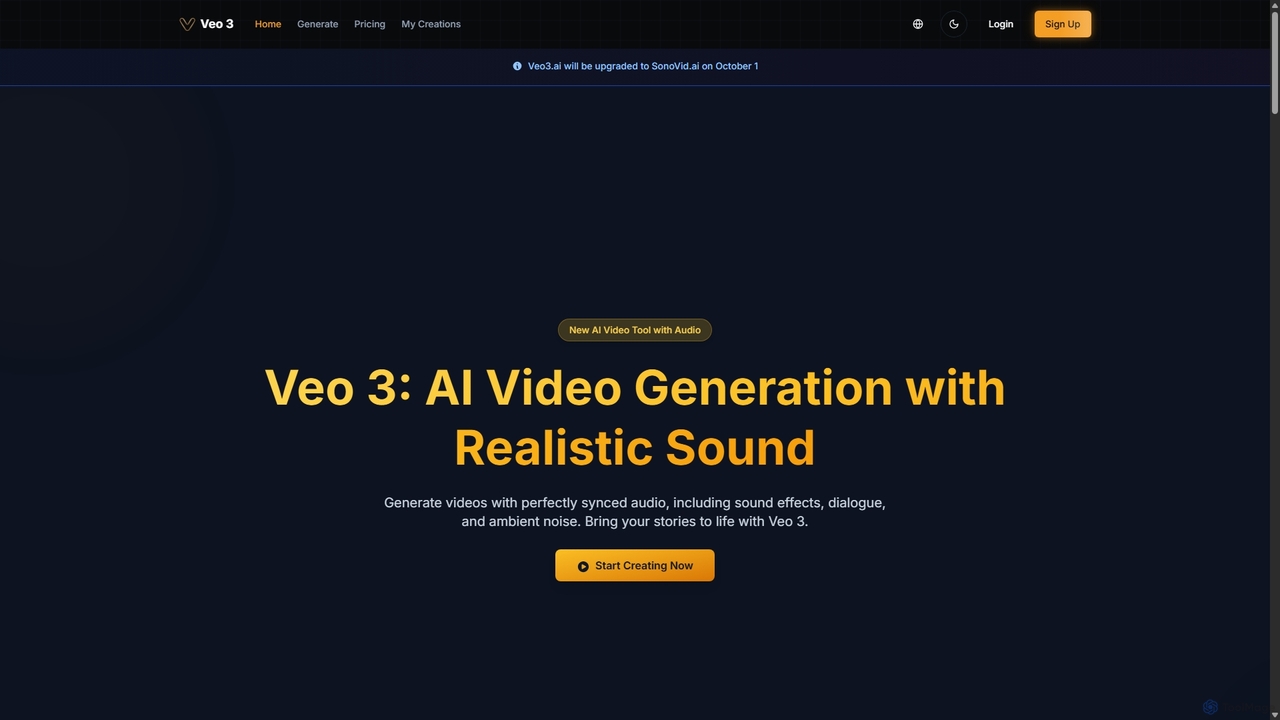
Veo 3
Veo 3 es un generador de video por IA avanzado, impulsado por el modelo Veo 3 de Google. …
Veo 3 es un generador de video por IA avanzado, impulsado por el modelo Veo 3 de Google. Se especializa en crear videos de alta calidad en 1080p de hasta 8 segundos con audio perfectamente sincronizado y generado de forma nativa. Los usuarios pueden generar contenido a partir de texto o imágenes, con diálogos realistas, efectos de sonido, ruido ambiental y sincronización de labios precisa, ideal para creadores y especialistas en marketing.
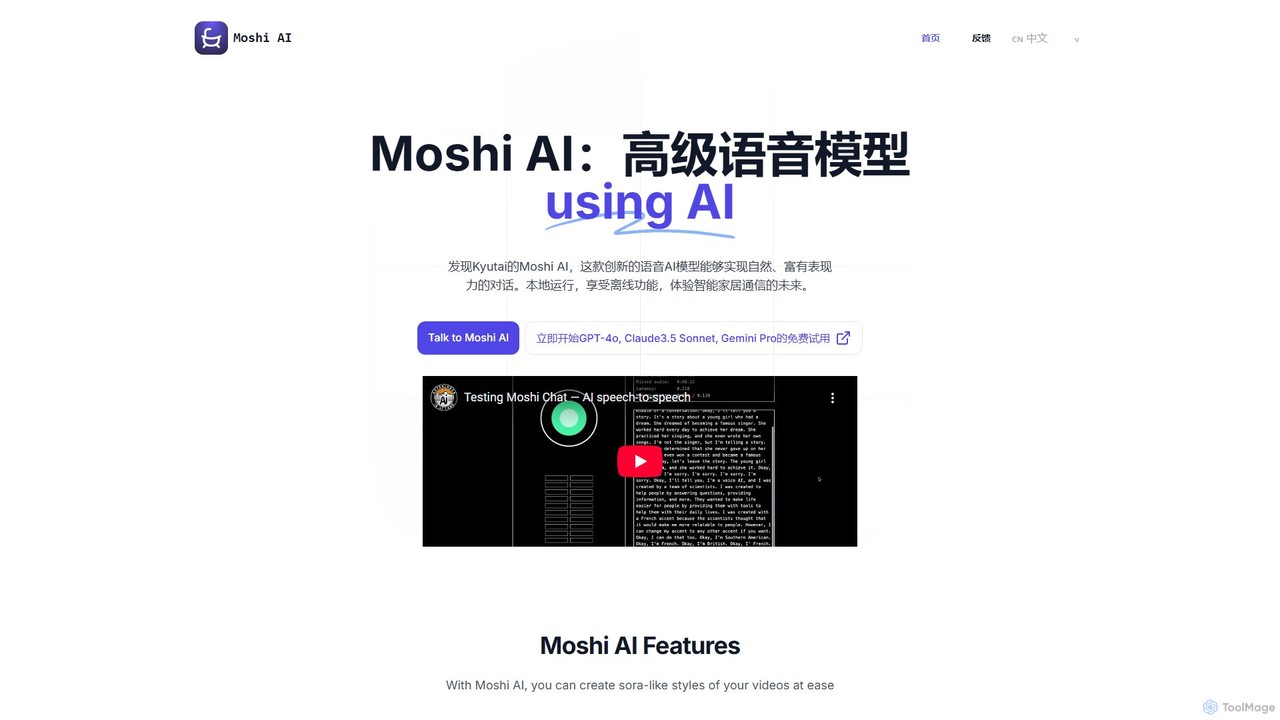
Moshi AI
Moshi AI es un modelo avanzado de IA de voz conversacional de baja latencia desarrollado por Kyutai. Permite …
Moshi AI es un modelo avanzado de IA de voz conversacional de baja latencia desarrollado por Kyutai. Permite diálogos naturales, expresivos e interrumpibles, diseñado para ejecutarse localmente en diverso hardware para uso sin conexión. Esto lo hace ideal para aplicaciones centradas en la privacidad como dispositivos domésticos inteligentes y sistemas en vehículos.
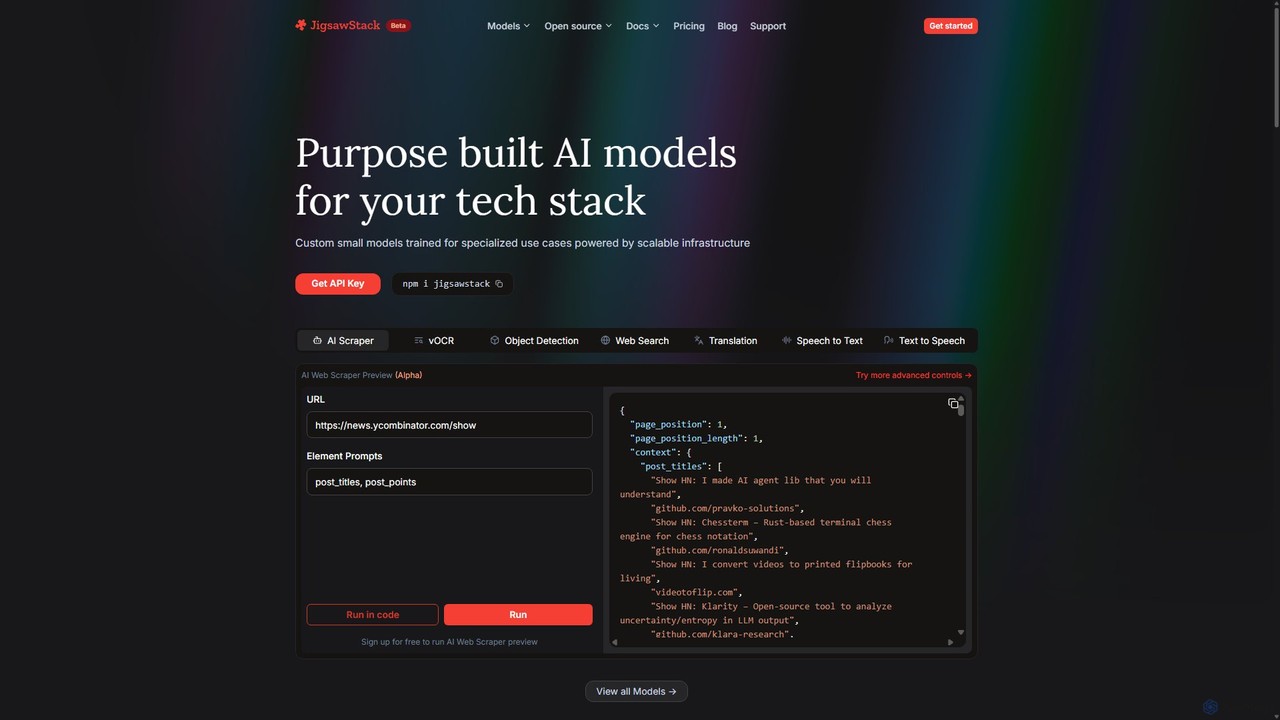
JigsawStack
JigsawStack ofrece un conjunto de modelos de IA pequeños y de propósito específico para desarrolladores, accesibles a través …
JigsawStack ofrece un conjunto de modelos de IA pequeños y de propósito específico para desarrolladores, accesibles a través de una única API. Simplifica tareas complejas de backend como el web scraping, OCR, traducción y conversión de voz a texto con una infraestructura rápida, fiable y escalable. Diseñado para una integración perfecta, proporciona una experiencia centrada en el desarrollador, con salida de datos estructurados y soporte global, permitiendo a los equipos construir y lanzar funcionalidades más rápido.
Speechllect
Speechllect es una avanzada plataforma de conversión de voz a texto (STT) y de texto a voz (TTS) …
Speechllect es una avanzada plataforma de conversión de voz a texto (STT) y de texto a voz (TTS) impulsada por IA. Utiliza una "Teoría del Sentido" única para no solo transcribir y sintetizar el habla, sino también para comprender y generar tono y entonación emocional. Esto lo hace ideal para crear interacciones de voz similares a las humanas para empresas, desarrolladores y creadores de contenido.
TextSynth
TextSynth ofrece a los desarrolladores un acceso potente y rentable a un conjunto de modelos de IA, incluidos …
TextSynth ofrece a los desarrolladores un acceso potente y rentable a un conjunto de modelos de IA, incluidos grandes modelos de lenguaje (LLM), texto a imagen, texto a voz y voz a texto, a través de una API REST flexible y un playground interactivo. Cuenta con modelos como Llama, Mistral, Stable Diffusion y Whisper, optimizados para velocidad y asequibilidad.
WaveSpeedAI
WaveSpeedAI es una plataforma de API unificada y de alto rendimiento diseñada para acelerar la generación de imágenes, …
WaveSpeedAI es una plataforma de API unificada y de alto rendimiento diseñada para acelerar la generación de imágenes, vídeos y audio por IA. Proporciona a desarrolladores y creadores un único punto de acceso a una vasta biblioteca de modelos de última generación de proveedores como Google, ByteDance y Kuaishou, permitiendo construir, crear y escalar aplicaciones de IA multimodal más rápidamente.
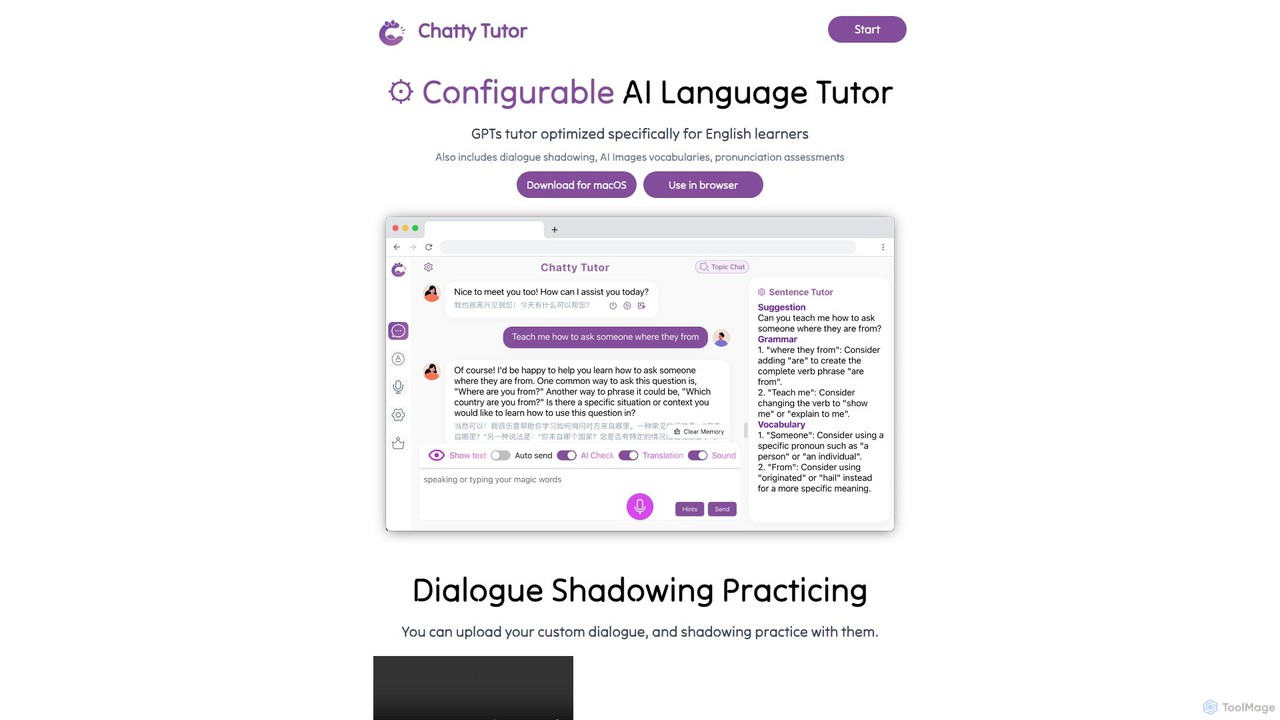
ChattyTutor
ChattyTutor es un tutor de idiomas de IA altamente configurable, impulsado por GPT y optimizado específicamente para estudiantes …
ChattyTutor es un tutor de idiomas de IA altamente configurable, impulsado por GPT y optimizado específicamente para estudiantes de inglés. Ofrece funciones interactivas como "dialogue shadowing", evaluación de pronunciación y construcción de vocabulario con imágenes generadas por IA, disponible en macOS y navegadores web.
Kippy
Kippy es un tutor de idiomas con IA diseñado para ayudarte a dominar el habla y la pronunciación. …
Kippy es un tutor de idiomas con IA diseñado para ayudarte a dominar el habla y la pronunciación. Practica conversaciones del mundo real en 10 idiomas con retroalimentación instantánea, corrección gramatical y respuestas guiadas para desarrollar fluidez y confianza. Es el complemento perfecto para estudiantes que quieren ir más allá de los libros de texto y empezar a hablar con naturalidad.
Text Generator
Text Generator es una plataforma de IA versátil y muy asequible que ofrece generación ilimitada de texto, código …
Text Generator es una plataforma de IA versátil y muy asequible que ofrece generación ilimitada de texto, código y voz. Proporciona una potente API, que incluye un punto de conexión compatible con OpenAI para una fácil migración, lo que la convierte en una solución rentable para desarrolladores, especialistas en marketing y creadores de contenido.

MiniMax
MiniMax es una empresa de investigación de IA que proporciona una plataforma completa de modelos fundacionales impulsados por …
MiniMax es una empresa de investigación de IA que proporciona una plataforma completa de modelos fundacionales impulsados por AGI. Ofrece API de vanguardia para texto (MiniMax-M1 con 1M de contexto), video (Hailuo 02) y voz (Speech 02), junto con un conjunto de aplicaciones nativas de IA gratuitas como MiniMax Chat, Agent y herramientas creativas. Se centra en el alto rendimiento, la eficiencia computacional y la rentabilidad tanto para desarrolladores como para usuarios finales.
Acerca de Síntesis de voz
Las herramientas de Síntesis de Voz son tecnologías impulsadas por IA que convierten texto escrito en habla humana de sonido natural. Estos sistemas utilizan modelos avanzados de aprendizaje profundo y redes neuronales para generar salida de audio con voces, emociones e idiomas personalizables. Se utilizan ampliamente para automatizar locuciones, mejorar las funciones de accesibilidad y crear experiencias de usuario interactivas en diversas plataformas digitales.
Características Principales
- Texto a Voz (TTS): Convierte el texto de entrada en audio hablado, a menudo con opciones para diferentes voces y estilos de habla.
- Personalización de Voz: Permite a los usuarios seleccionar entre una gama de voces predefinidas o incluso crear perfiles de voz personalizados para que coincidan con identidades de marca específicas.
- Soporte Multilingüe: Genera voz en numerosos idiomas y dialectos, atendiendo a audiencias globales y diversas necesidades de contenido.
- Expresión Emocional: Incorpora matices emocionales como felicidad, tristeza o enojo en el habla sintetizada, haciendo las interacciones más realistas.
- Soporte SSML (Lenguaje de Marcado de Síntesis de Voz): Proporciona un control preciso sobre la pronunciación, el énfasis, las pausas y la velocidad del habla para una salida de audio altamente personalizada.
Escenarios de Aplicación
Las herramientas de Síntesis de Voz son invaluables para creadores de contenido, desarrolladores y empresas. Permiten la producción rápida de contenido de audio para módulos de e-learning, podcasts y narraciones de video. Los desarrolladores integran estas herramientas para construir aplicaciones accesibles para usuarios con discapacidad visual o para crear interfaces de voz más atractivas para dispositivos inteligentes y chatbots.
Cómo Elegir
Al seleccionar una herramienta de Síntesis de Voz, considere la naturalidad y calidad de las voces generadas, la amplitud del soporte de idiomas y acentos, y la disponibilidad de expresión emocional. Evalúe la facilidad de integración a través de APIs, la flexibilidad de las opciones de personalización de voz y el modelo de precios basado en su volumen de uso y requisitos de características específicas.
Síntesis de vozEscenario de uso
Automatización de Narración de Audiolibros y Podcasts
Creadores de contenido y editores pueden usar herramientas de síntesis de voz para convertir rápidamente manuscritos escritos en audiolibros o episodios de podcast de alta calidad. Al seleccionar una voz adecuada y ajustar parámetros como el ritmo y el tono, pueden producir contenido de audio atractivo sin necesidad de actores de voz humanos, reduciendo significativamente el tiempo y los costos de producción mientras amplían su alcance de audiencia.
Mejora de la Accesibilidad para Usuarios con Discapacidad Visual
Los desarrolladores integran APIs de síntesis de voz en aplicaciones, sitios web y sistemas operativos para proporcionar capacidades de lectura de pantalla. Esto permite que los usuarios con discapacidad visual escuchen el contenido de texto digital, como artículos, correos electrónicos o instrucciones de navegación, leído en voz alta. Esta aplicación mejora significativamente la accesibilidad digital y la inclusión, permitiendo que una audiencia más amplia interactúe con la información de forma independiente.
Creación de Voces en Off para Contenido de Video y E-learning
Productores de video y creadores de cursos de e-learning utilizan la síntesis de voz para generar voces en off con sonido profesional para sus proyectos multimedia. En lugar de contratar talentos de voz o grabarse a sí mismos, pueden introducir guiones y recibir archivos de audio en varios idiomas y voces. Esto agiliza el proceso de localización para contenido global y asegura una calidad de voz consistente en todos los módulos de aprendizaje o segmentos de video.
Desarrollo de Sistemas de Respuesta de Voz Interactiva (IVR)
Las empresas aprovechan la síntesis de voz para potenciar sus sistemas de Respuesta de Voz Interactiva (IVR), proporcionando servicio y soporte al cliente automatizado. En lugar de pregrabar cada frase posible, las empresas pueden generar respuestas dinámicamente basadas en las consultas de los clientes. Esto asegura una voz de marca consistente, reduce la necesidad de extensas bibliotecas de talentos de voz y permite actualizaciones rápidas de los guiones de IVR, mejorando la experiencia del cliente y la eficiencia operativa.
Creación de Alertas y Notificaciones de Voz Dinámicas
Las aplicaciones y dispositivos inteligentes pueden usar la síntesis de voz para generar alertas y notificaciones de voz en tiempo real para los usuarios. Por ejemplo, un sistema de hogar inteligente puede anunciar la apertura de una puerta, o una aplicación de navegación puede proporcionar indicaciones paso a paso. Esto ofrece una forma manos libres y sin necesidad de mirar para que los usuarios reciban información crítica, mejorando la comodidad y la seguridad en diversos contextos, desde la conducción hasta las tareas domésticas diarias.
Personalización de Asistentes Digitales y Chatbots
Los desarrolladores y gerentes de producto utilizan la síntesis de voz para dar a los asistentes digitales (como Siri o Alexa) y chatbots voces y personalidades únicas y reconocibles. Al personalizar la voz, el tono e incluso las inflexiones emocionales, pueden crear una experiencia de interacción más atractiva y humana. Esta personalización ayuda a generar confianza en el usuario y hace que la tecnología se sienta más intuitiva y menos robótica, mejorando la satisfacción general del usuario.