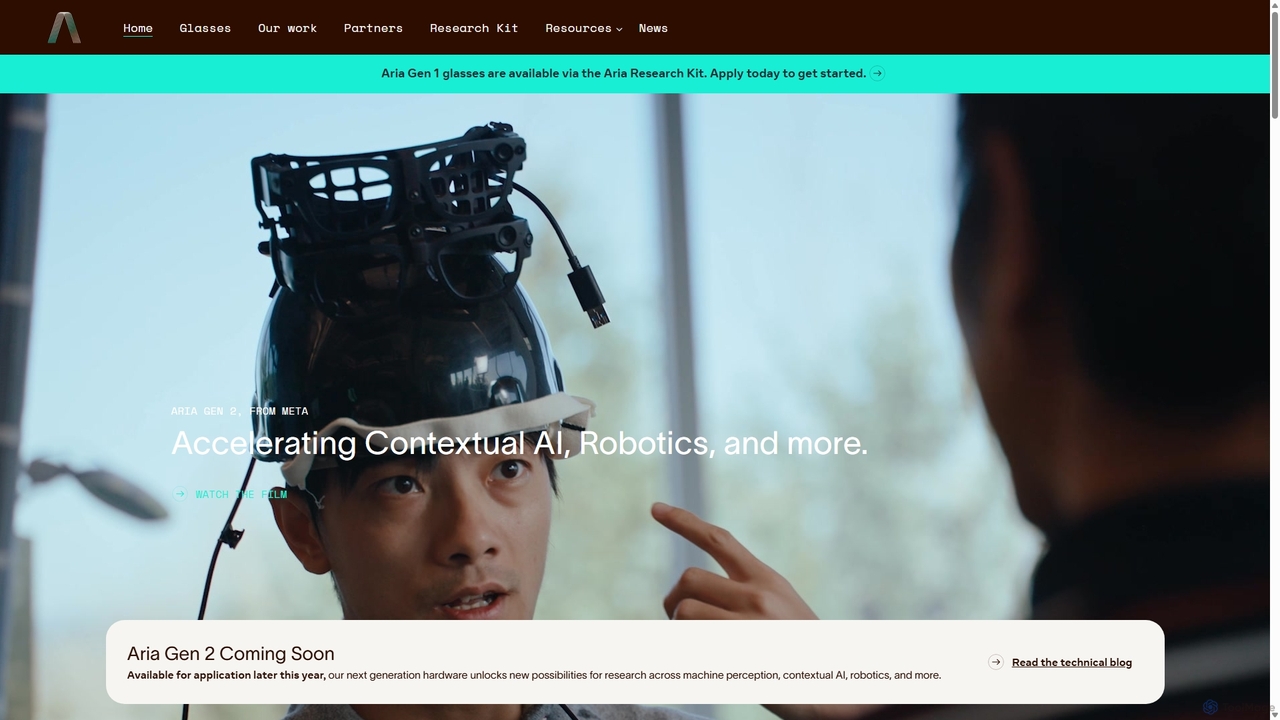
Project Aria
Project Aria es una iniciativa de investigación de Meta diseñada para acelerar el desarrollo de la IA contextual, …
Project Aria es una iniciativa de investigación de Meta diseñada para acelerar el desarrollo de la IA contextual, la realidad aumentada (RA) y la robótica. Utiliza gafas de investigación avanzadas, como las Aria Gen 2, para capturar datos desde una perspectiva en primera persona, proporcionando a los investigadores una plataforma integral que incluye hardware, conjuntos de datos de código abierto y herramientas de desarrollo para construir el futuro de la percepción artificial.

Allen Institute for AI (AI2)
El Allen Institute for AI (AI2) es un instituto de investigación sin fines de lucro dedicado a construir …
El Allen Institute for AI (AI2) es un instituto de investigación sin fines de lucro dedicado a construir IA revolucionaria para el bien común. Se enfoca en crear modelos de lenguaje grandes verdaderamente de código abierto como OLMo, conjuntos de datos completos y herramientas de IA especializadas para avanzar en la investigación científica y abordar los principales desafíos globales en áreas como la ciencia climática, la conservación y la medicina.
Acerca de Conjuntos de datos
Los conjuntos de datos son colecciones curadas de datos utilizadas para entrenar, validar y probar modelos de inteligencia artificial. Estas colecciones, que pueden incluir imágenes, texto, audio o datos numéricos, proporcionan el conocimiento fundamental para que los algoritmos de aprendizaje automático aprendan patrones y realicen predicciones. Acceder a conjuntos de datos relevantes y de alta calidad es un primer paso crítico en el desarrollo de aplicaciones de IA efectivas, desde sistemas de visión por computadora hasta procesadores de lenguaje natural. Sirven como los 'libros de texto' de los que aprende la IA, influyendo directamente en la precisión y el rendimiento del modelo final.
Características Principales
- Datos Estructurados y Etiquetados: Los datos a menudo están organizados y anotados con etiquetas (p. ej., 'gato' o 'perro' para imágenes) para facilitar el aprendizaje supervisado.
- Diversos Tipos de Datos: Incluye una amplia gama de formatos como imágenes, documentos de texto, clips de audio y datos tabulares para admitir diversas tareas de IA.
- División de Datos: Típicamente pre-divididos en conjuntos de entrenamiento, validación y prueba para asegurar una evaluación adecuada del modelo y prevenir el sobreajuste.
- Metadatos Completos: Acompañados de documentación detallada que explica las fuentes de datos, los métodos de recopilación y la información de licencia.
Casos de Uso
Los conjuntos de datos son fundamentales en la investigación académica y el desarrollo comercial de IA. Son utilizados por científicos de datos para entrenar modelos de aprendizaje automático personalizados, por investigadores para comparar el rendimiento de algoritmos con estándares establecidos, y por desarrolladores para ajustar modelos pre-entrenados para tareas específicas como el análisis de sentimientos o la detección de objetos.
Cómo Elegir
Al seleccionar un conjunto de datos, considere su relevancia para su problema específico y su calidad general, incluida la precisión de las etiquetas y la ausencia de sesgos. Además, evalúe el tamaño del conjunto de datos: debe ser lo suficientemente grande para que su modelo aprenda de manera efectiva. Finalmente, verifique los términos de la licencia para asegurarse de que permitan su uso previsto, ya sea para fines comerciales o académicos.
Conjuntos de datosEscenario de uso
Entrenar un Modelo de Reconocimiento de Imágenes Personalizado
Un ingeniero de visión por computadora necesita construir un modelo para identificar defectos de fabricación específicos. Utiliza un conjunto de datos etiquetado y de alta calidad de imágenes de productos, donde cada imagen está anotada como 'aprobada' o 'rechazada' junto con el tipo de defecto. Al entrenar su red neuronal convolucional (CNN) con este conjunto de datos, el modelo aprende a distinguir entre productos impecables y diversos defectos, automatizando el proceso de control de calidad y aumentando la precisión de la detección.
Ajustar un Modelo de Lenguaje para Soporte al Cliente
Una startup quiere crear un chatbot especializado para su industria. Un especialista en aprendizaje automático toma un modelo de lenguaje grande y pre-entrenado y lo ajusta utilizando un conjunto de datos curado de consultas de clientes específicas de la industria y las respuestas de expertos correspondientes. Este proceso adapta el modelo general para que entienda la terminología de nicho y proporcione respuestas relevantes y precisas, mejorando significativamente la experiencia de soporte al cliente.
Evaluar un Nuevo Algoritmo de Recomendación
Un equipo de ciencia de datos ha desarrollado un nuevo algoritmo para un motor de recomendación de películas. Para demostrar su eficacia, lo prueban con un conjunto de datos público y estándar de la industria como MovieLens. Comparan la precisión de predicción de su algoritmo (p. ej., qué tan bien predice las calificaciones de los usuarios) con benchmarks establecidos. Esto permite una evaluación y validación objetiva del rendimiento antes de implementar el nuevo sistema.
Desarrollar un Dispositivo Doméstico Inteligente Controlado por Voz
Un desarrollador de IoT está creando un dispositivo que responde a comandos de voz. Utiliza un gran conjunto de datos de audio que contiene miles de horas de comandos hablados por diversos hablantes con diferentes acentos y en diversos entornos acústicos. Este conjunto de datos se utiliza para entrenar un modelo de voz a texto, asegurando que el dispositivo pueda entender de manera fiable los comandos del usuario como 'enciende las luces' o 'pon un temporizador' en condiciones del mundo real.
Construir un Asistente de IA para Diagnóstico Médico
Una institución de investigación médica tiene como objetivo crear una herramienta de IA para ayudar a los radiólogos a detectar tumores en resonancias magnéticas. Utilizan un conjunto de datos especializado y anonimizado de imágenes médicas, donde cada escaneo está etiquetado por radiólogos expertos. Entrenar un modelo con este conjunto de datos ayuda a crear un sistema que puede resaltar áreas potenciales de preocupación, sirviendo como una segunda opinión y mejorando potencialmente la velocidad y precisión del diagnóstico.
Realizar Análisis de Sentimientos para Investigación de Mercado
Un analista de marketing quiere medir la opinión pública sobre el lanzamiento de un nuevo producto. Utiliza un conjunto de datos de publicaciones en redes sociales y reseñas de productos, cada una etiquetada con un sentimiento (positivo, negativo, neutral). Al entrenar un modelo de procesamiento de lenguaje natural (NLP) con estos datos, puede analizar automáticamente miles de nuevos comentarios, proporcionando información en tiempo real sobre la satisfacción del cliente e identificando áreas de mejora.