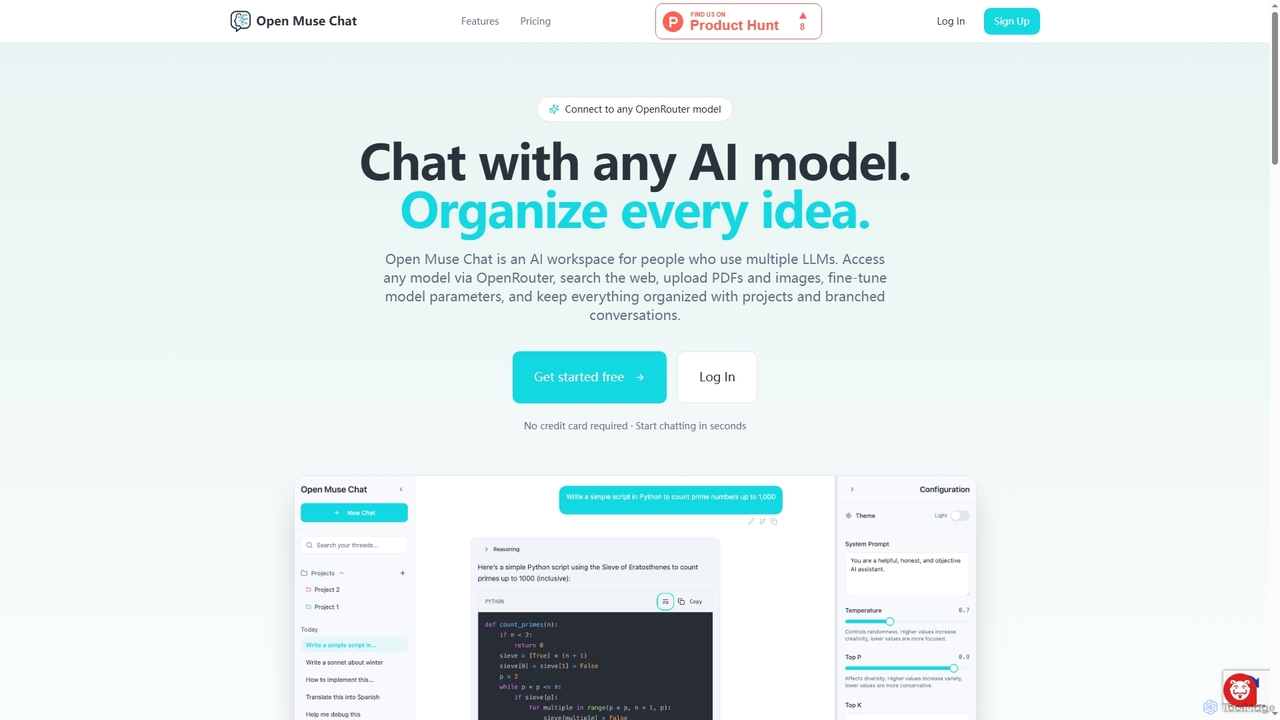
Open Muse Chat
Open Muse Chat es una interfaz de chat de IA multi-modelo avanzada diseñada para usuarios que aprovechan varios …
Open Muse Chat es una interfaz de chat de IA multi-modelo avanzada diseñada para usuarios que aprovechan varios modelos de lenguaje grandes (LLM). Se conecta a cualquier modelo de OpenRouter, ofrece búsqueda web, carga de archivos (PDF, imágenes) para contexto y proporciona un control granular sobre los parámetros del modelo, todo dentro de un espacio de trabajo organizado con proyectos y conversaciones ramificadas.
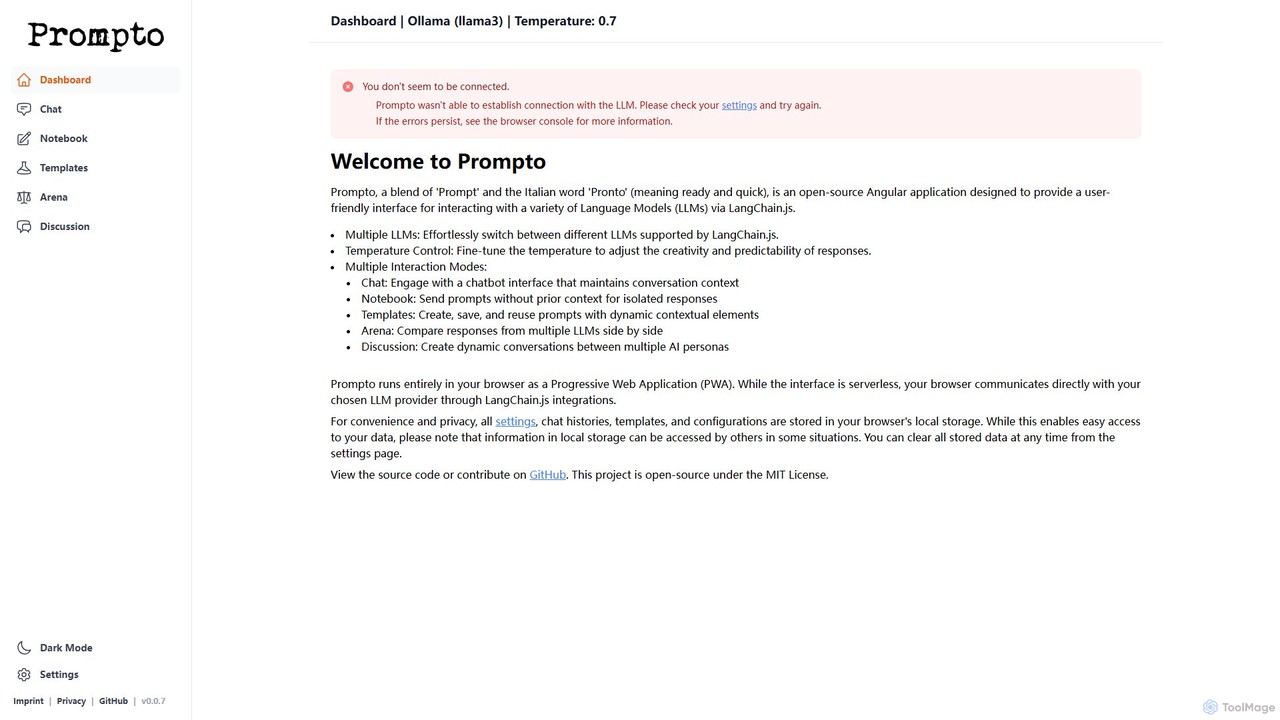
Prompto
Prompto es una interfaz gratuita, de código abierto y basada en navegador para interactuar con una amplia gama …
Prompto es una interfaz gratuita, de código abierto y basada en navegador para interactuar con una amplia gama de Grandes Modelos de Lenguaje (LLMs). Utiliza LangChain.js para conectarse directamente a proveedores como OpenAI, Anthropic y modelos locales a través de Ollama, ofreciendo funciones avanzadas como una Arena de comparación de modelos, plantillas de prompts y discusiones multi-IA, todo mientras prioriza la privacidad del usuario al almacenar los datos localmente.
Acerca de Interfaz LLM
Una Interfaz LLM es una herramienta de desarrollo especializada que actúa como una puerta de enlace unificada para acceder a múltiples Modelos de Lenguaje Grandes (LLMs). Estas herramientas proporcionan una API única y consistente, permitiendo a los desarrolladores interactuar con diferentes modelos como GPT, Claude o Llama sin escribir código específico del proveedor. Esta capa de abstracción simplifica el desarrollo, optimiza los costos y mejora la resiliencia de la aplicación al permitir el cambio de modelo y los fallbacks de manera fluida. Para los desarrolladores que construyen aplicaciones impulsadas por IA, una Interfaz LLM es un componente crucial para gestionar la complejidad y mejorar la eficiencia operativa.
Características Principales
- API Unificada: Conéctese a varios LLMs de diferentes proveedores a través de un único punto de acceso API estandarizado.
- Enrutamiento de Modelos y Fallbacks: Dirija automáticamente las solicitudes al modelo más adecuado según el costo o el rendimiento, con mecanismos de fallback incorporados.
- Seguimiento de Costos y Uso: Monitoree los gastos de API, el uso de tokens y la latencia en todos los modelos conectados en un panel centralizado.
- Gestión de Prompts: Cree, pruebe, versione e implemente plantillas de prompts de forma centralizada para un comportamiento consistente de la aplicación.
- Caché de Solicitudes: Almacene y reutilice respuestas para solicitudes idénticas para reducir la latencia y disminuir los costos de API.
Casos de Uso
Las Interfaces LLM son utilizadas principalmente por desarrolladores de software, ingenieros de IA y equipos de producto que construyen aplicaciones que requieren flexibilidad y fiabilidad. Son ideales para crear chatbots de múltiples proveedores, plataformas de generación de contenido que aprovechan las fortalezas de diferentes modelos, o agentes de IA complejos que necesitan seleccionar dinámicamente la mejor herramienta para una tarea. Las empresas también las utilizan para estandarizar y gobernar el acceso a los LLM en toda la organización.
Cómo Elegir
Al seleccionar una Interfaz LLM, considere lo siguiente: Primero, evalúe la lista de LLMs compatibles y la velocidad con la que se integran nuevos modelos. Segundo, evalúe las métricas de rendimiento como la sobrecarga de latencia y las garantías de fiabilidad. Tercero, examine las características de observabilidad, como la calidad del registro, los paneles de seguimiento de costos y los análisis. Finalmente, revise la experiencia del desarrollador, incluida la calidad de la documentación y la disponibilidad de SDKs para sus lenguajes de programación preferidos.
Interfaz LLMEscenario de uso
Construir un Chatbot de IA Resiliente con Fallbacks de Modelo
Un líder técnico de servicio al cliente necesita asegurar que su chatbot de soporte mantenga un alto tiempo de actividad. Usando una Interfaz LLM, configuran un modelo primario como GPT-4 para respuestas de alta calidad y un modelo secundario y rentable como Claude 3 Sonnet como fallback. Si la API del modelo primario experimenta una interrupción o alta latencia, la interfaz redirige automáticamente todas las solicitudes entrantes al modelo de fallback. Esto asegura que el chatbot permanezca operativo y receptivo para los usuarios, previniendo la interrupción del servicio sin requerir intervención manual del equipo de ingeniería.
Pruebas A/B de Prompts para un Generador de Textos de Marketing
Un tecnólogo de marketing busca encontrar el prompt más efectivo para generar titulares de anuncios. Usando el sistema de gestión de prompts de la Interfaz LLM, crean dos variaciones de un prompt ('Prompt A' y 'Prompt B'). La interfaz se configura para enrutar el 50% de las solicitudes de generación a cada versión del prompt. El panel de análisis integrado rastrea métricas clave como las tasas de clics y la participación del usuario para los titulares generados por cada prompt. Después de analizar los datos, el equipo puede implementar con confianza el prompt ganador al 100% del tráfico con un solo clic, optimizando el rendimiento de su campaña.
Optimización de Costos de API para un Servicio de Resumen de Contenido
La herramienta de resumen de una startup necesita gestionar los costos de la API de LLM de manera efectiva. Utilizan una Interfaz LLM para implementar un enrutamiento inteligente. Las solicitudes simples, como resumir un párrafo corto, se envían a un modelo rápido y de bajo costo. Las tareas más complejas, como resumir un documento de 20 páginas, se enrutan a un modelo potente y de alta capacidad. El panel de seguimiento de costos de la interfaz proporciona una vista en tiempo real del gasto por modelo, lo que permite al equipo ajustar sus reglas de enrutamiento y estrategia de caché para mantenerse dentro del presupuesto mientras mantienen una alta calidad de salida para todos los usuarios.
Estandarización del Acceso a LLM en una Gran Empresa
Un arquitecto de TI empresarial necesita proporcionar a los desarrolladores un acceso seguro y gobernado a varios LLMs. Despliegan una Interfaz LLM central como puerta de enlace. Esto les permite gestionar todas las claves de API en una bóveda segura, establecer límites de gasto y cuotas de uso para diferentes equipos, y hacer cumplir las políticas de privacidad de datos. La interfaz registra cada solicitud, proporcionando un rastro de auditoría completo para fines de cumplimiento. Este enfoque centralizado empodera a los equipos de desarrollo para innovar con diferentes modelos mientras asegura que la organización mantenga el control sobre la seguridad, los costos y la gobernanza.
Prototipado Rápido de una Característica Impulsada por IA
Un equipo de producto está construyendo rápidamente un prototipo para una nueva característica de IA. En lugar de escribir integraciones separadas para OpenAI, Anthropic y Google, utilizan un único SDK de Interfaz LLM. Esto les permite cambiar entre GPT-4, Claude y Gemini cambiando solo una línea de código de configuración. Pueden probar rápidamente qué modelo proporciona la mejor calidad, velocidad y rentabilidad para su caso de uso específico. Esto acelera drásticamente la fase de prototipado, permitiéndoles validar su idea y pasar a producción mucho más rápido.
Almacenamiento en Caché de Respuestas para un Sistema de Preguntas y Respuestas de Alto Tráfico
Un desarrollador está construyendo un bot de preguntas frecuentes para un sitio de comercio electrónico popular que recibe muchas preguntas repetitivas. Habilitan la función de caché en su Interfaz LLM. Cuando se hace por primera vez una pregunta como '¿Cuál es su política de devoluciones?', el LLM genera una respuesta y la interfaz almacena este par de pregunta-respuesta en una caché. Para todas las preguntas idénticas posteriores, la respuesta se sirve directamente desde la caché en milisegundos. Esta estrategia reduce significativamente las llamadas a la API del proveedor de LLM, disminuyendo los costos en más del 70% y proporcionando respuestas casi instantáneas a los usuarios para consultas comunes.