Trismik
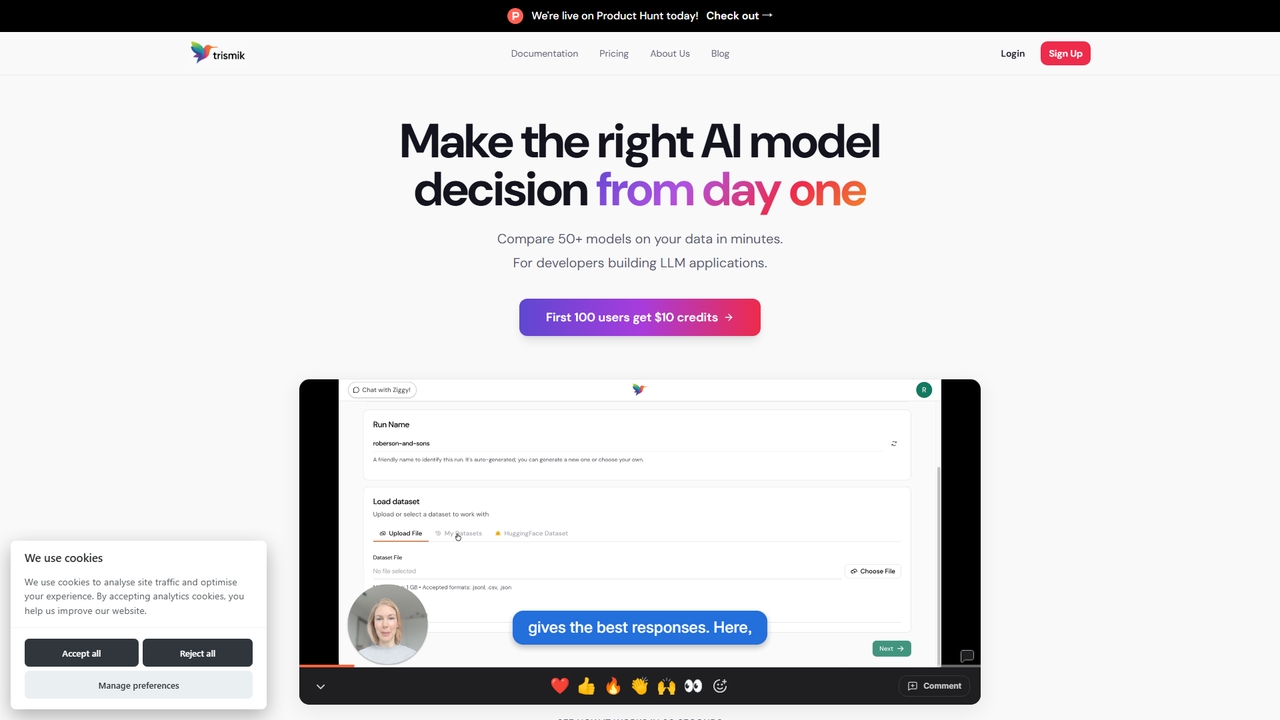
Compare más de 50 LLMs con sus propios datos en minutos. Tome decisiones de modelo basadas en evidencia …
Compare más de 50 LLMs con sus propios datos en minutos. Tome decisiones de modelo basadas en evidencia sobre calidad, costo y velocidad.
Compare AI Models
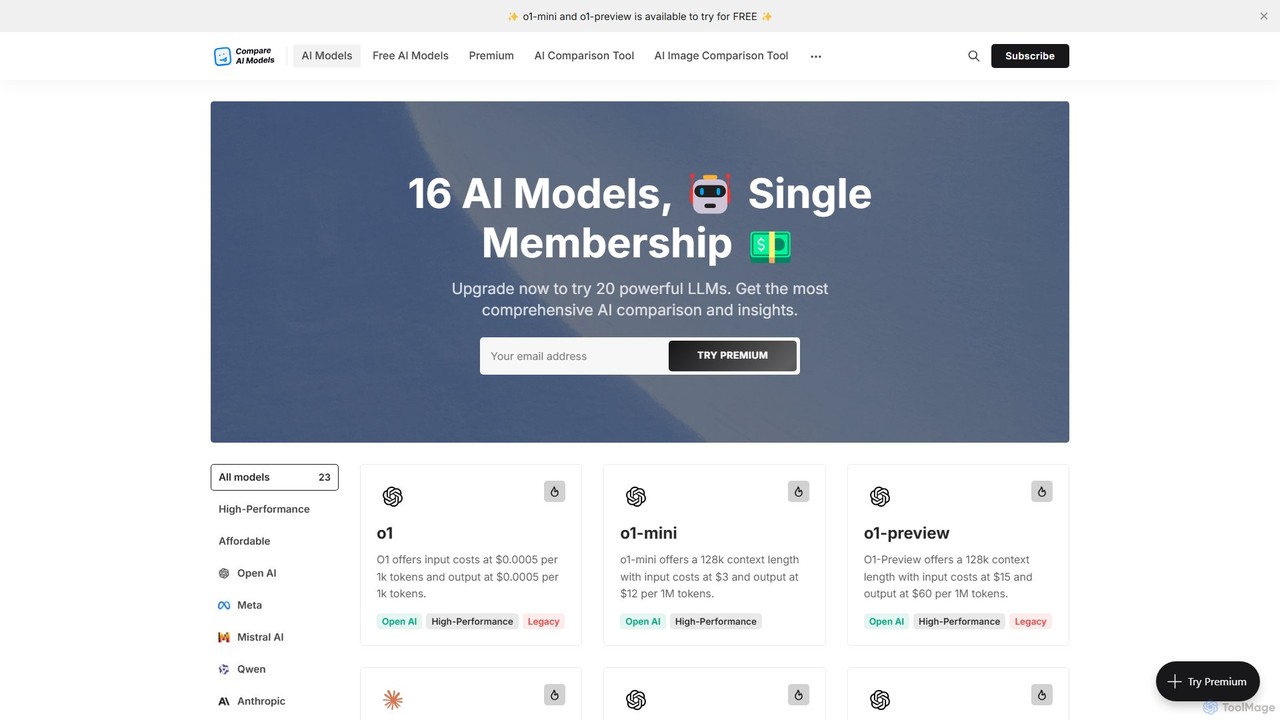
Una plataforma completa para comparar más de 20 de los principales Modelos de Lenguaje Grandes (LLMs). Ofrece métricas …
Una plataforma completa para comparar más de 20 de los principales Modelos de Lenguaje Grandes (LLMs). Ofrece métricas detalladas sobre rendimiento, precios de API, ventanas de contexto y características, junto con un chat gratuito para probar modelos directamente. Una herramienta esencial para desarrolladores, investigadores y empresas para encontrar la IA perfecta para sus necesidades.
Joythee AI
Joythee AI es una plataforma avanzada de IA conversacional que te permite chatear con múltiples agentes de IA …
Joythee AI es una plataforma avanzada de IA conversacional que te permite chatear con múltiples agentes de IA simultáneamente. Compara respuestas de varios LLM en una única interfaz, disfruta de conversaciones personalizadas y protege tu privacidad con un modo de incógnito. Ideal para individuos, equipos y empresas que buscan mejorar la productividad y la creatividad.
Acerca de Comparación de Modelos
Las herramientas de Comparación de Modelos son plataformas especializadas dentro del conjunto de herramientas para desarrolladores, diseñadas para evaluar, referenciar y comparar sistemáticamente el rendimiento de diferentes modelos de IA. Estas herramientas proporcionan un entorno estructurado para ejecutar modelos como LLMs o generadores de imágenes contra las mismas entradas y conjuntos de datos para medir sus resultados de manera objetiva. Son esenciales para tomar decisiones basadas en datos, permitiendo a desarrolladores e investigadores seleccionar el modelo más preciso, rentable y eficiente para una aplicación específica. Al ofrecer análisis comparativos y métricas cuantitativas, agilizan el proceso de selección de modelos, que de otro modo sería complejo y lento.
Características Principales
- Playground Comparativo: Compara instantáneamente los resultados de múltiples modelos para el mismo prompt en una interfaz unificada.
- Benchmarking Automatizado: Ejecuta benchmarks estándar de la industria (p. ej., MMLU, HumanEval) para puntuar los modelos en diversas capacidades.
- Análisis de Costo y Latencia: Rastrea y compara el costo financiero y el tiempo de respuesta para la inferencia de cada modelo.
- Evaluación Cualitativa: Facilita la retroalimentación humana y la puntuación en criterios subjetivos como coherencia, estilo o seguridad.
- Control de Versiones e Historial: Registra y sigue los experimentos de evaluación a lo largo del tiempo para monitorear cambios de rendimiento y regresiones.
Casos de Uso
Estas herramientas son críticas para desarrolladores de IA, ingenieros de MLOps y gerentes de producto durante el ciclo de vida de desarrollo y mantenimiento. Se utilizan al seleccionar un modelo fundacional para una nueva función, evaluar el impacto del ajuste fino o realizar pruebas de regresión después de una actualización del modelo. Por ejemplo, un equipo que construye un chatbot de servicio al cliente usaría estas herramientas para comparar las habilidades conversacionales y los costos de los modelos de OpenAI, Anthropic y Google antes de comprometerse con uno.
Cómo Elegir
Al seleccionar una herramienta de Comparación de Modelos, considere la amplitud de los modelos compatibles, incluyendo tanto APIs propietarias como opciones de código abierto. Evalúe los conjuntos de benchmarks disponibles y la flexibilidad para crear conjuntos de datos de evaluación personalizados. Analice sus capacidades de integración con su flujo de trabajo de MLOps y sus pipelines de CI/CD existentes. Finalmente, considere las características de colaboración que permiten a los miembros del equipo revisar los resultados y los modelos de precios que escalan con sus necesidades de evaluación.
Comparación de ModelosEscenario de uso
Selección del LLM Óptimo para un Nuevo Chatbot
Un equipo de producto está desarrollando un nuevo chatbot de soporte al cliente impulsado por IA. Utilizan una herramienta de comparación de modelos para evaluar GPT-4, Claude 3 Sonnet y Llama 3 70B. Crean un 'conjunto de datos dorado' de 100 consultas comunes de clientes y ejecutan los tres modelos con él. La plataforma proporciona una vista comparativa de las respuestas, junto con métricas automatizadas de utilidad y tono. También calcula el costo promedio por cada 1,000 conversaciones para cada modelo. Basándose en los resultados, eligen Claude 3 Sonnet, ya que ofrece el mejor equilibrio entre calidad conversacional y costo operativo para su caso de uso específico.
Evaluación del Rendimiento de un Modelo Afinado
Un ingeniero de ML ha afinado un modelo de código abierto Mistral 7B con documentos internos de la empresa para una tarea de respuesta a preguntas. Para justificar la implementación, utiliza una herramienta de comparación para referenciar el modelo afinado contra el modelo base Mistral 7B y un modelo propietario como GPT-4. Sube un conjunto de prueba de 50 preguntas técnicas. La herramienta mide la precisión factual y la relevancia. Los resultados muestran que su modelo afinado supera al modelo base en un 30% en precisión y es 10 veces más barato que GPT-4, proporcionando una evidencia clara para proceder con la implementación.
Pruebas de Regresión para Actualizaciones de API de Modelos
Un equipo de MLOps gestiona una función de resumen que depende de una API de modelo externa. El proveedor de la API anuncia una nueva versión. Antes de cambiar, el equipo utiliza una plataforma de comparación de modelos para ejecutar su conjunto de 500 documentos de prueba a través de las versiones antigua y nueva de la API. La plataforma marca automáticamente cualquier resumen de la nueva versión que sea significativamente más corto, menos coherente o fácticamente incorrecto en comparación con el resultado de la versión anterior. Esta prueba de regresión automatizada previene una degradación en la calidad del servicio y asegura una transición suave al modelo actualizado.
Comparación de Modelos de Generación de Imágenes para Marketing
Una agencia de marketing necesita seleccionar un modelo de generación de imágenes para crear creatividades publicitarias. Utilizan una herramienta de comparación para probar DALL-E 3, Midjourney y Stable Diffusion con 20 prompts diferentes relacionados con los productos de su cliente. La herramienta permite a su equipo creativo calificar cada imagen generada en una escala de 1 a 5 por su adherencia al prompt, calidad estética y alineación con la marca. Las puntuaciones agregadas revelan que, aunque Midjourney produce las imágenes más estéticas, DALL-E 3 es superior en la incorporación precisa de detalles específicos del producto mencionados en los prompts, lo que lo convierte en la mejor opción para sus necesidades.
Optimización de Costo-Rendimiento para una API de Resumen
Un servicio de agregación de noticias utiliza un LLM para resumir artículos. Para reducir costos, quieren encontrar el modelo más barato que mantenga la calidad. Usando una herramienta de comparación, prueban cinco modelos diferentes, desde el GPT-4 de gama alta hasta alternativas de código abierto más pequeñas. Pasan 1,000 artículos por cada uno y usan puntuaciones ROUGE automatizadas para medir la calidad del resumen, mientras la herramienta rastrea el costo de cada modelo. Descubren que una versión cuantizada de un modelo Llama 3 8B proporciona el 95% de la calidad de GPT-4 a solo el 10% del costo, lo que conduce a ahorros mensuales significativos.
Pruebas A/B de Prompts en Múltiples Modelos
Un ingeniero de prompts tiene la tarea de crear el prompt más efectivo para una función de generación de código. En lugar de probar los prompts uno por uno, utiliza una herramienta de comparación de modelos para configurar un experimento matricial. Introduce tres variaciones de prompts diferentes y las prueba en cuatro modelos (p. ej., GPT-4, Claude 3 Opus, Gemini Pro y un modelo de código especializado). La plataforma ejecuta las 12 combinaciones y presenta los resultados en un mapa de calor, mostrando qué par de prompt-modelo produce el código más preciso y eficiente. Esto acelera el proceso de optimización de prompts diez veces.