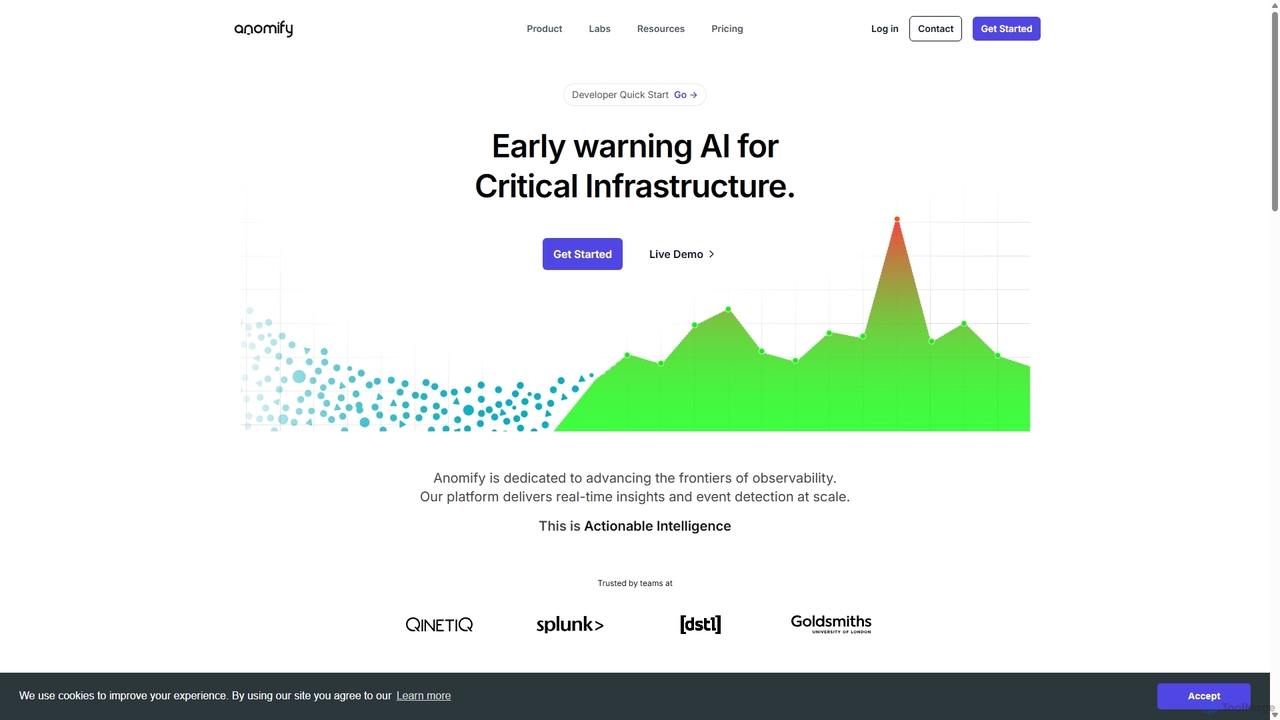
Anomify
Anomify es una plataforma de alerta temprana impulsada por IA para infraestructuras críticas, que ofrece detección de anomalías …
Anomify es una plataforma de alerta temprana impulsada por IA para infraestructuras críticas, que ofrece detección de anomalías en tiempo real y observabilidad a escala. Aprovecha el aprendizaje automático multietapa para analizar datos de series temporales, reducir significativamente los falsos positivos y acelerar el análisis de causa raíz. Diseñado para equipos de DevOps, SRE e IT, Anomify transforma el monitoreo de reactivo a proactivo, garantizando el rendimiento y la fiabilidad del sistema.
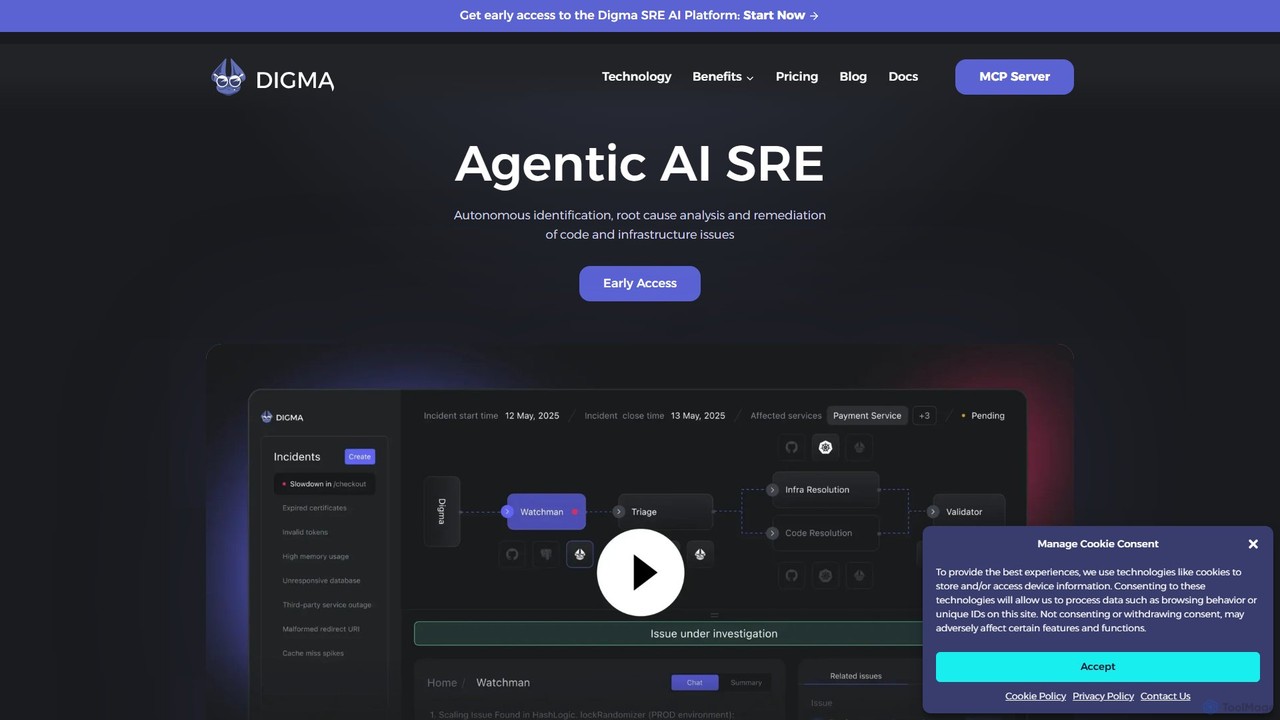
Digma
Digma es una plataforma SRE de IA agéntica que utiliza Análisis Dinámico de Código (DCA) para identificar, analizar …
Digma es una plataforma SRE de IA agéntica que utiliza Análisis Dinámico de Código (DCA) para identificar, analizar y remediar de forma autónoma problemas de código e infraestructura antes de que lleguen a producción. Se integra con tu pila de observabilidad para proporcionar información en tiempo real, prevenir cambios disruptivos y optimizar el rendimiento de la aplicación, reduciendo significativamente el tiempo de resolución y el esfuerzo de ingeniería.
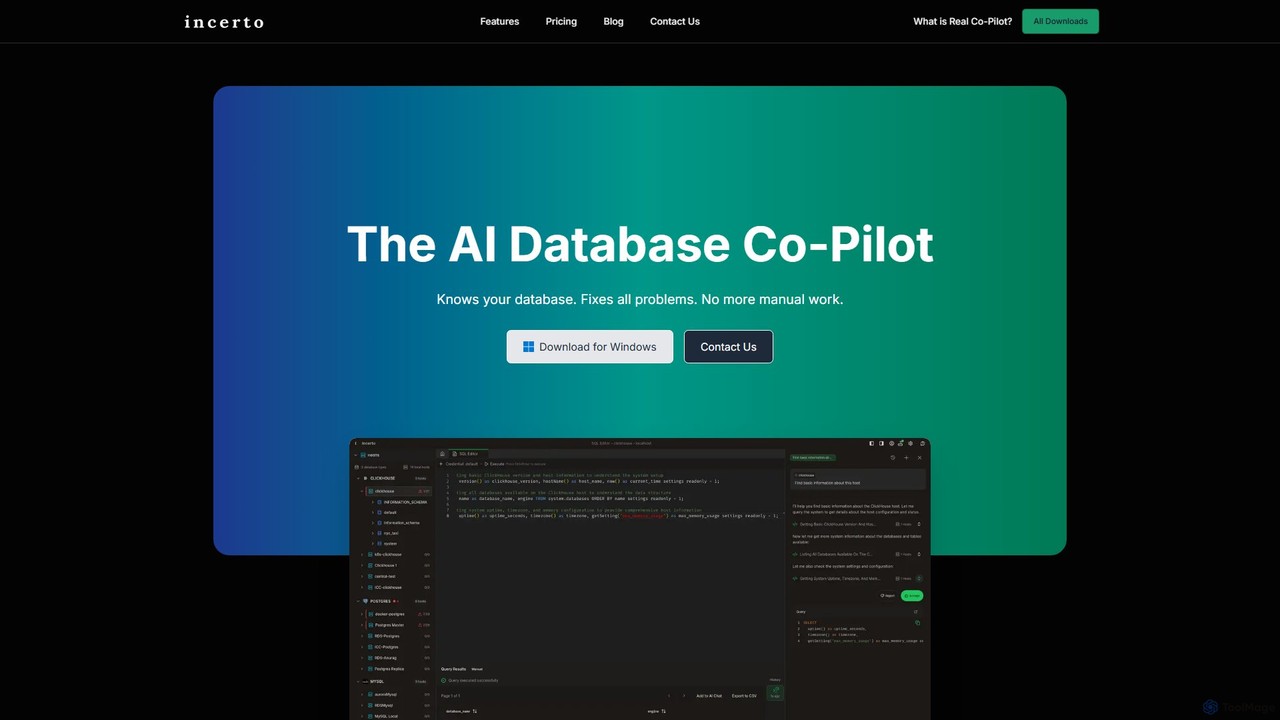
Incerto
Incerto es un copiloto de IA agéntico diseñado para resolver todos los problemas de bases de datos. Detecta …
Incerto es un copiloto de IA agéntico diseñado para resolver todos los problemas de bases de datos. Detecta y resuelve proactivamente problemas de producción, optimiza el rendimiento de las consultas y automatiza tareas complejas de gestión de bases de datos. Al aprovechar un rico motor de contexto y agentes de IA especializados, Incerto reduce significativamente el trabajo manual, minimiza el tiempo de inactividad y mejora la eficiencia y seguridad general de las bases de datos para desarrolladores y DBAs.
Resolve.ai
Resolve.ai es una plataforma de SRE con IA Agéntica que automatiza la respuesta a incidentes y el análisis …
Resolve.ai es una plataforma de SRE con IA Agéntica que automatiza la respuesta a incidentes y el análisis de causa raíz. Actúa como un miembro virtual del equipo de guardia, investigando alertas, probando hipótesis e identificando problemas en minutos para reducir el MTTR, disminuir el agotamiento de los ingenieros y aumentar el tiempo de actividad del sistema.
Acerca de Observabilidad
Las herramientas de Observabilidad son plataformas avanzadas diseñadas para proporcionar información profunda y consultable sobre el estado interno de sistemas de TI complejos. Funcionan recopilando, correlacionando y analizando datos de telemetría de alta cardinalidad, principalmente registros (logs), métricas y trazas. Esto permite a los equipos de ingeniería ir más allá de la simple monitorización para explorar y comprender activamente el comportamiento del sistema, lo que hace posible depurar problemas novedosos en entornos distribuidos. Estas herramientas son cruciales para mantener la fiabilidad y el rendimiento de las aplicaciones nativas de la nube modernas.
Funciones Clave
- Datos de Telemetría Unificados: Ingiere y correlaciona los tres pilares de la observabilidad: registros, métricas y trazas distribuidas en una única plataforma.
- Trazado Distribuido: Visualiza el recorrido de extremo a extremo de las solicitudes a medida que viajan a través de múltiples microservicios y componentes.
- Análisis de Alta Cardinalidad: Permite consultar y filtrar datos basados en atributos arbitrarios, esencial para depurar sesiones de usuario o solicitudes específicas.
- Detección de Anomalías con IA: Identifica automáticamente patrones inusuales o desviaciones del rendimiento base sin reglas preconfiguradas.
- Mapeo de Dependencias de Servicios: Genera mapas en tiempo real de cómo interactúan los diferentes servicios y componentes de la infraestructura.
Casos de Uso
Las herramientas de observabilidad son utilizadas principalmente por ingenieros de DevOps, Ingenieros de Fiabilidad de Sitios (SRE) y desarrolladores de software que trabajan en sistemas complejos y distribuidos. Son esenciales para solucionar incidentes de producción en arquitecturas de microservicios, optimizar el rendimiento de las aplicaciones identificando cuellos de botella y comprender el impacto de las nuevas implementaciones de código en tiempo real. Estas plataformas también son valiosas para la gestión de infraestructuras en la nube y el análisis de seguridad.
Cómo Elegir
Al seleccionar una herramienta de Observabilidad, considere la compatibilidad de sus fuentes de datos y la amplitud de sus integraciones. Evalúe la potencia y la usabilidad de su lenguaje de consulta para explorar datos. Analice su escalabilidad para manejar su volumen de datos y su modelo de precios (por ejemplo, por host, por GB ingerido). Finalmente, considere la efectividad de sus herramientas de visualización, paneles y capacidades de alerta impulsadas por IA para el flujo de trabajo de su equipo.
ObservabilidadEscenario de uso
Depurar fallos de microservicios en producción
Un Ingeniero de Fiabilidad de Sitios (SRE) recibe una alerta por altas tasas de error en el servicio de pago. Usando una plataforma de observabilidad, accede a la traza distribuida de una transacción fallida. La traza visualiza la ruta de la solicitud a través de los microservicios de autenticación, inventario y pago. Identifican rápidamente que el servicio de pago está agotando el tiempo de espera al llamar a una API de terceros. Al inspeccionar los registros asociados con ese ID de traza específico, encuentran el mensaje de error exacto, lo que les permite resolver el problema en minutos en lugar de horas.
Optimizar proactivamente el rendimiento de la aplicación
Un equipo de DevOps nota un aumento gradual en los tiempos de respuesta de la API. Utilizan una herramienta de observabilidad para analizar métricas de sus servidores de aplicaciones, bases de datos y cachés. Al crear un panel que correlaciona el uso de la CPU, la latencia de las consultas a la base de datos y las tasas de acierto de la caché, descubren una consulta de base de datos específica que se ha vuelto ineficiente a medida que los datos han crecido. La función de trazado distribuido confirma que esta consulta es el principal cuello de botella. El equipo optimiza la consulta y despliega la solución, reduciendo con éxito el tiempo de respuesta promedio de la API en un 40% antes de que afecte a los usuarios finales.
Comprender el impacto de las nuevas implementaciones de código
Un desarrollador de software implementa una nueva función que refactoriza una parte central de la aplicación. Inmediatamente después de la implementación, utiliza una plataforma de observabilidad para comparar métricas de negocio clave (como registros de usuarios) y métricas de rendimiento (como latencia y tasas de error) antes y después del cambio. Los paneles de la plataforma muestran un ligero aumento en la latencia pero una caída significativa en el uso de memoria. Este enfoque basado en datos permite al equipo validar que la refactorización fue exitosa y tuvo el impacto positivo previsto en el consumo de recursos sin afectar negativamente la experiencia del usuario.
Monitorear el uso y los costos de los recursos en la nube
Un ingeniero de la nube tiene la tarea de optimizar los costos de infraestructura. Utiliza una herramienta de observabilidad para recopilar métricas detalladas de su clúster de Kubernetes, incluido el uso de CPU/memoria por pod, el tráfico de red y las reclamaciones de volúmenes persistentes. Al visualizar estos datos, identifican varios servicios sobreaprovisionados que utilizan constantemente menos del 20% de sus recursos asignados. También detectan una fuga de memoria en un contenedor de aplicación específico. Basándose en estos conocimientos, ajustan las solicitudes y los límites de recursos para los servicios y corrigen la fuga, lo que resulta en una reducción del 25% en su factura mensual de la nube.
Correlacionar la salud del sistema con los KPI de negocio
Un gerente de producto de un sitio de comercio electrónico quiere entender por qué las tasas de abandono de carritos son altas. Usando una herramienta de observabilidad que se integra con análisis de negocio, crea un panel que superpone métricas técnicas (tiempo de carga de la página, errores de API) con métricas de negocio (artículos agregados al carrito, finalizaciones de compra). Descubre una fuerte correlación: cada vez que la latencia de la API de 'procesamiento de pagos' supera los 2 segundos, la tasa de abandono de carritos aumenta en un 50%. Este vínculo directo entre el rendimiento técnico y los resultados de negocio proporciona una justificación clara para priorizar los recursos de ingeniería para optimizar la API de pago.
Mejorar la seguridad con detección de anomalías
Un equipo de operaciones de seguridad (SecOps) utiliza una plataforma de observabilidad para ingerir registros de autenticación de todos los servicios. Configuran un monitor impulsado por IA para detectar anomalías en los patrones de inicio de sesión. El sistema marca automáticamente un aumento repentino en los intentos de inicio de sesión fallidos desde un rango de IP nunca antes visto, seguido de un inicio de sesión exitoso. Esto activa una alerta inmediata. El analista de seguridad investiga las trazas y los registros asociados, confirma que es un ataque de relleno de credenciales y bloquea rápidamente el rango de IP malicioso y fuerza un restablecimiento de contraseña para la cuenta comprometida, evitando una brecha mayor.