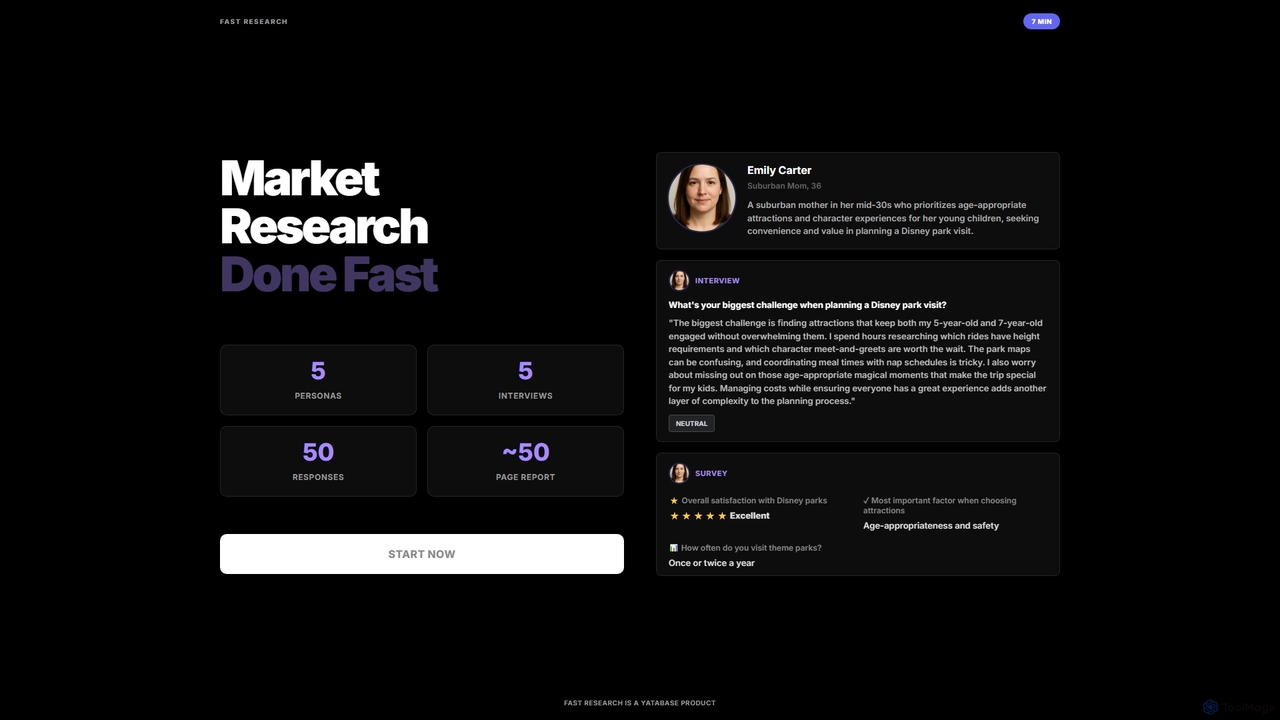
Fast Research
Fast Research es una herramienta de investigación de mercado impulsada por IA que genera rápidamente datos sintéticos, incluyendo …
Fast Research es una herramienta de investigación de mercado impulsada por IA que genera rápidamente datos sintéticos, incluyendo personas detalladas, entrevistas simuladas y respuestas a encuestas. Ofrece informes completos, permitiendo a las empresas obtener información rápida y accionable para la toma de decisiones estratégicas sin las complejidades de la recopilación de datos tradicional.
Acerca de Datos Sintéticos
Los Datos Sintéticos se refieren a conjuntos de datos generados artificialmente que imitan las propiedades estadísticas y los patrones de los datos del mundo real sin contener ninguna información personal o sensible real. Estas herramientas impulsadas por IA aprovechan algoritmos avanzados para crear datos realistas, abordando desafíos críticos como la privacidad de los datos, la escasez y el sesgo. Proporcionan una alternativa segura y flexible para diversos fines analíticos y de desarrollo, especialmente en la investigación de mercados.
Características Principales
- Preservación de la Privacidad: Genera datos que mantienen la integridad estadística al tiempo que garantiza que no se expongan datos individuales reales.
- Aumento de Datos: Crea puntos de datos adicionales para expandir los conjuntos de datos existentes, mejorando el entrenamiento y la robustez del modelo.
- Mitigación de Sesgos: Permite la generación de conjuntos de datos equilibrados para reducir los sesgos inherentes encontrados en los datos del mundo real.
- Simulación Realista: Produce datos que reflejan con precisión las distribuciones, correlaciones y estructuras de los datos originales.
- Escalabilidad: Permite la generación de grandes volúmenes de datos bajo demanda, superando las limitaciones de la recopilación de datos reales.
Casos de Uso
Las empresas utilizan datos sintéticos para probar nuevas características de productos, simular escenarios de mercado o entrenar modelos de IA sin comprometer la privacidad del cliente. Los investigadores pueden analizar tendencias y patrones en dominios sensibles como la atención médica o las finanzas, asegurando un manejo ético de los datos.
Cómo Elegir
Al seleccionar una herramienta de datos sintéticos, considere la fidelidad requerida (qué tan cerca imita los datos reales), los tipos de datos que puede generar (tabulares, imágenes, texto), sus garantías de privacidad y las capacidades de integración con los pipelines de datos existentes. Evalúe la facilidad de uso y el nivel de control ofrecido sobre las características de los datos.
Datos SintéticosEscenario de uso
Desarrollo de Modelos de IA que Preservan la Privacidad
Los científicos de datos utilizan datos sintéticos para entrenar modelos de aprendizaje automático para aplicaciones sensibles (por ejemplo, diagnósticos de atención médica, detección de fraude financiero) sin acceder ni exponer información real de pacientes o clientes. Esto garantiza el cumplimiento de estrictas regulaciones de privacidad como GDPR y HIPAA, permitiendo un desarrollo robusto de modelos en industrias altamente reguladas.
Simulación del Comportamiento del Mercado para Pruebas de Productos
Los investigadores de mercado generan conjuntos de datos de clientes sintéticos para simular diversas condiciones de mercado y respuestas de los consumidores a nuevos lanzamientos de productos o campañas de marketing. Esto permite realizar pruebas A/B sin riesgos, planificación de escenarios y pronóstico de la demanda antes de la implementación en el mundo real, ahorrando costos y mitigando posibles impactos negativos.
Superar la Escasez de Datos en Mercados Nicho
Las startups o empresas en industrias nicho a menudo carecen de datos reales suficientes para análisis robustos o entrenamiento de modelos de IA. Las herramientas de datos sintéticos ayudan a crear conjuntos de datos extensos y representativos para llenar estas brechas, permitiendo un análisis integral, desarrollo de productos e inteligencia competitiva incluso con fuentes de datos originales limitadas.
Mejora de las Pruebas y el Desarrollo de Software
Los desarrolladores de software utilizan datos sintéticos para poblar entornos de prueba, asegurando que las aplicaciones puedan manejar diversas entradas de datos y casos extremos sin depender de datos de producción sensibles. Esto acelera los ciclos de prueba, mejora la calidad del software y permite una validación más exhaustiva de nuevas características y actualizaciones en un entorno controlado y seguro.
Mitigación de Sesgos en Conjuntos de Datos de Entrenamiento de IA
Los investigadores y desarrolladores de ética de IA emplean la generación de datos sintéticos para crear conjuntos de datos equilibrados que corrijan los sesgos presentes en los datos del mundo real (por ejemplo, la subrepresentación de ciertos grupos demográficos). Esto conduce a sistemas de IA más justos y equitativos, reduciendo los resultados discriminatorios y mejorando la confiabilidad general de las aplicaciones de IA.
Facilitación del Intercambio y la Colaboración de Datos
Las organizaciones pueden compartir versiones sintéticas de sus conjuntos de datos propietarios o sensibles con socios externos, investigadores u organismos reguladores. Esto permite la innovación y la investigación colaborativas, al tiempo que se adhiere estrictamente a los acuerdos de gobernanza y confidencialidad de datos, fomentando un entorno seguro para obtener información basada en datos en todos los ecosistemas.