Avian
Visitar sitio web



Avian Visión general
Avian es una plataforma de infraestructura de IA de vanguardia diseñada para proporcionar la inferencia de IA más rápida y fiable del mercado. Se dirige a desarrolladores, ingenieros de IA y empresas que requieren un alto rendimiento y baja latencia para sus aplicaciones de IA. Aprovechando el hardware más reciente, como las GPU NVIDIA B200 y H200, y técnicas de optimización avanzadas como la decodificación especulativa, Avian alcanza velocidades líderes en la industria, estableciendo nuevos puntos de referencia para modelos como DeepSeek R1 a 351 tokens por segundo.
La plataforma ofrece dos servicios principales para adaptarse a diversas necesidades: una API Serverless flexible y potentes Despliegues Dedicados. Este enfoque dual permite a los usuarios integrar rápidamente modelos de primer nivel en sus aplicaciones con una simple llamada a la API o tener un control total sobre su infraestructura para ejecutar modelos personalizados y ajustados para tareas especializadas. Avian está construido para escalar, operando sin límites de tasa para soportar aplicaciones a medida que crecen desde el prototipo hasta la producción completa.
Cómo usar Avian
Empezar a usar Avian es sencillo y está diseñado para la eficiencia del desarrollador. Hay dos métodos principales para aprovechar su poder:
- Usando la API Serverless de Avian: Esta es la forma más rápida de acceder a modelos de alto rendimiento. Los desarrolladores pueden simplemente registrarse, obtener una clave de API y realizar solicitudes a varios puntos finales de modelos (por ejemplo, la serie Meta Llama 3.1). El proceso implica una implementación de código simple, similar a otras API de IA, lo que permite una integración perfecta en aplicaciones existentes sin gestionar ninguna infraestructura.
- Configurando Despliegues Dedicados: Para los usuarios que necesitan ejecutar modelos personalizados de HuggingFace o requieren recursos dedicados para un alto rendimiento constante, Avian ofrece instancias de GPU dedicadas. Los usuarios pueden seleccionar el tipo de GPU deseado (por ejemplo, NVIDIA H200 SXM), configurar la duración del despliegue y desplegar su modelo en la infraestructura optimizada de Avian. Esto es ideal para cargas de trabajo de producción que exigen un rendimiento y una asignación de recursos garantizados.
Características principales de Avian
- Velocidad de Inferencia Récord: Alcanza velocidades de hasta 351 tokens por segundo, superando significativamente los promedios de la industria y permitiendo aplicaciones de IA en tiempo real.
- API Serverless: Proporciona acceso de pago por uso a una gama de modelos de alto rendimiento como Meta Llama 3.1 y DeepSeek R1, sin límites de tasa.
- Despliegues de GPU Dedicados: Ofrece instancias dedicadas con las últimas GPU de NVIDIA (B200, H200, H100) para desplegar cualquier modelo de HuggingFace, garantizando el máximo rendimiento y control.
- Seguridad de Nivel Empresarial: Cuenta con sólidas medidas de seguridad, incluyendo el cumplimiento de SOC2 Tipo 2 (en proceso), adhesión al GDPR, cifrado TLS 1.2+ y Autenticación Multifactor (MFA). Los datos no se almacenan permanentemente, garantizando la privacidad del usuario.
- Escalable y Listo para Producción: Construido para manejar cargas de trabajo de producción de alto volumen sin degradación del rendimiento, apoyando a las empresas a medida que escalan.
- Conectores de Datos: Ofrece un conjunto de conectores para plataformas como Looker Studio y Google Sheets, permitiendo la integración de datos sin problemas desde fuentes como Google Analytics, Facebook Ads y más.
Casos de uso para Avian
La infraestructura de alta velocidad de Avian es adecuada para una amplia gama de aplicaciones de IA exigentes:
- Chatbots y Asistentes de IA en Tiempo Real: Potenciando la IA conversacional que puede responder instantáneamente, proporcionando una experiencia de usuario natural y fluida.
- Generación de Contenido a Gran Escala: Permitiendo a las plataformas generar artículos, textos de marketing y código a una escala y velocidad sin precedentes.
- Análisis y Resumen de Datos Complejos: Procesando y analizando grandes cantidades de datos de texto en tiempo real para análisis financiero, investigación e inteligencia empresarial.
- Despliegue de Modelos Propietarios: Las empresas con modelos entrenados o ajustados a medida pueden desplegarlos en la infraestructura dedicada de Avian para obtener un rendimiento óptimo en entornos de producción.
Ventajas de Avian
Avian se destaca en el competitivo mercado de infraestructura de IA con varias ventajas clave:
- Rendimiento Inigualable: Ofrece velocidades de inferencia de 3 a 10 veces más rápidas en comparación con otros proveedores de nube importantes y servicios de inferencia.
- Flexibilidad: Admite tanto modelos estándar a través de una API simple como modelos personalizados en hardware dedicado, atendiendo a todos los niveles de desarrollo de IA.
- Rentabilidad: Ofrece precios competitivos tanto para su API como para sus instancias dedicadas, proporcionando un rendimiento superior por dólar.
- Fiabilidad y Escalabilidad: La ausencia de límites de tasa y el uso de infraestructura de grado de producción aseguran que las aplicaciones puedan escalar sin problemas sin encontrar cuellos de botella de rendimiento.
- Sólida Postura de Seguridad: Un claro compromiso con la seguridad y la privacidad de los datos genera confianza para los clientes empresariales que manejan información sensible.
Precios y planes
Avian ofrece una estructura de precios transparente y flexible adaptada a diferentes patrones de uso:
- API de Avian (Pago por uso): A los usuarios se les cobra por millón de tokens tanto para la entrada como para la salida. Los precios son competitivos y varían según el modelo. Por ejemplo:
- Meta Llama 3.1 8B Instruct: $0.10 por millón de tokens de entrada/salida.
- Meta Llama 3.1 70B Instruct: $0.45 por millón de tokens de entrada/salida.
- Meta Llama 3.1 405B Instruct: $1.50 por millón de tokens de entrada/salida.
- Despliegues Dedicados: Facturado por segundo para instancias de GPU reservadas. Esto es ideal para cargas de trabajo de alto rendimiento. Tarifas de ejemplo para instancias reservadas:
- NVIDIA H100 SXM (80GB HBM3): Desde $0.00139/segundo.
- NVIDIA H200 SXM (141GB HBM3): Desde $0.00208/segundo.
- Pedidos Anticipados de Nuevo Hardware: Avian también ofrece pedidos anticipados de hardware de última generación como el NVIDIA B200, permitiendo a los clientes asegurar el acceso a la última tecnología. Por ejemplo, un despliegue de 7 días de un DeepSeek R1 en una configuración de 8x NVIDIA B200 tiene un precio de $14,000.
Avian Comentarios (0)
Inicie sesión para publicar comentarios
Iniciar sesión yaAvianAnálisis de tráfico del sitio web
Estado del tráfico más reciente
Estado
Tendencia de tráfico mensual
Ubicación geográfica
Top 5 países/regiones
-
🇺🇸 United States32,46%
-
🇬🇧 United Kingdom26,65%
-
🇮🇳 India22,60%
-
🇻🇳 Vietnam18,29%
Palabras clave populares
| Palabra clave | Costo por clic |
|---|---|
|
$1,39
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$2,52
|
Avian Alternativas
Ver todo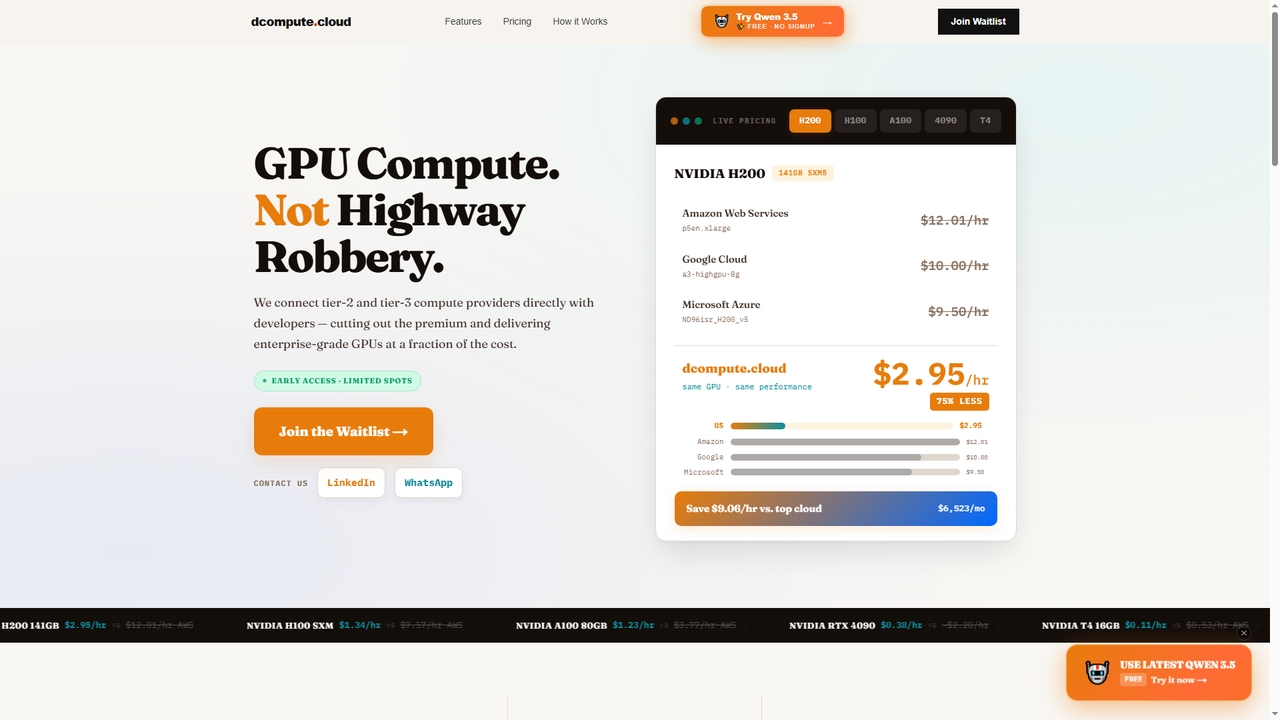
Dcompute
Dcompute es un mercado de computación GPU descentralizado que conecta directamente a los desarrolladores con proveedores de centros …
Dcompute es un mercado de computación GPU descentralizado que conecta directamente a los desarrolladores con proveedores de centros de datos de nivel 2 y 3. Ofrece GPU NVIDIA de grado empresarial (H200, H100, A100, RTX 4090, T4) por una fracción del costo de los principales proveedores de nube, prometiendo ahorros de hasta el 90%. La plataforma cuenta con implementación instantánea, API/panel unificado, orquestación completa y facturación pura por uso por segundo, sin mínimos.
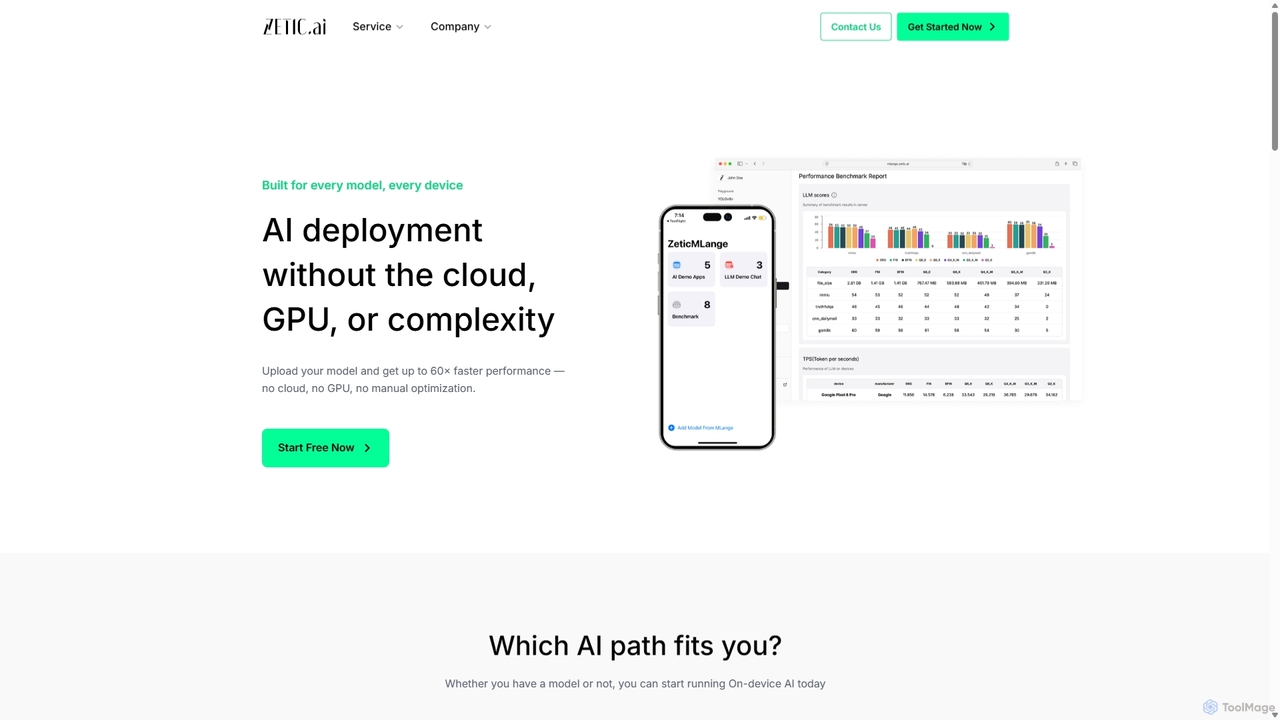
Zetic.ai
Zetic.ai es una plataforma que permite a los desarrolladores desplegar modelos de IA directamente en dispositivos de borde, …
Zetic.ai es una plataforma que permite a los desarrolladores desplegar modelos de IA directamente en dispositivos de borde, eliminando la necesidad de costosos servidores GPU. Su pipeline automatizado, ZETIC.MLange, optimiza y convierte modelos para su ejecución en el dispositivo, logrando un rendimiento hasta 60 veces más rápido con aceleración NPU, garantizando la privacidad de los datos y reduciendo la latencia.
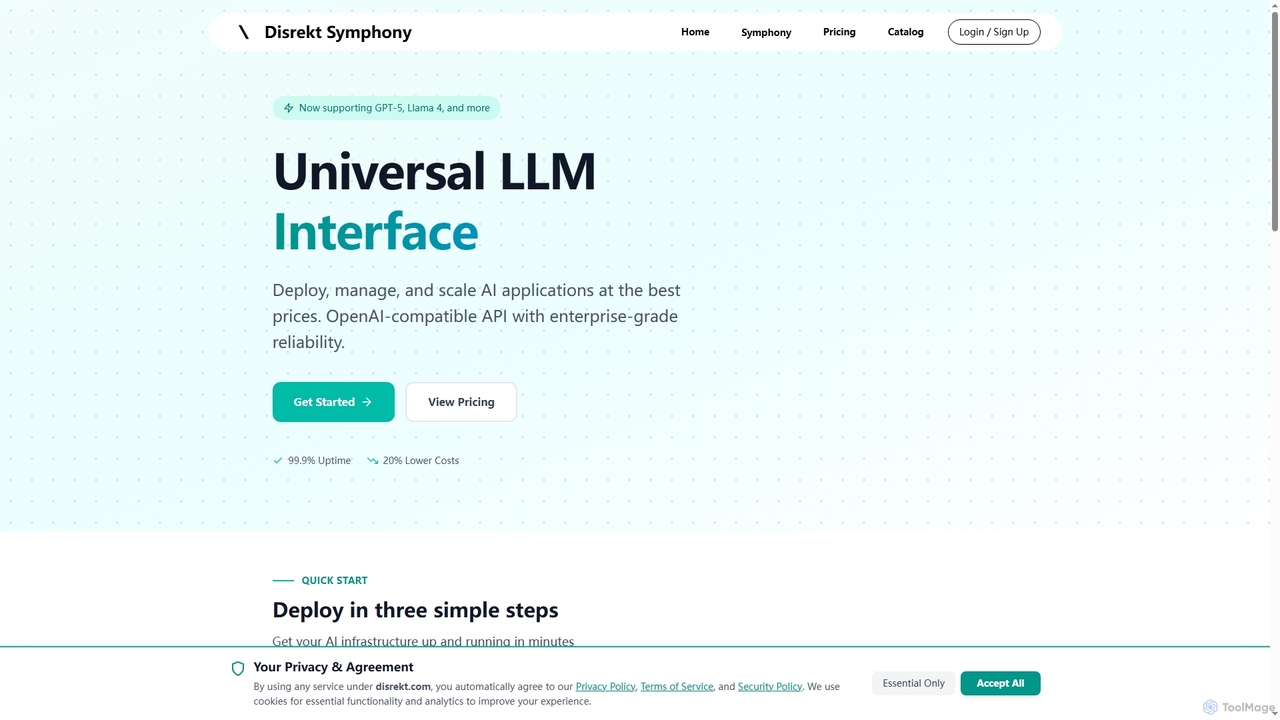
Symphony
Symphony es una interfaz LLM universal que proporciona una API compatible con OpenAI para implementar, gestionar y escalar …
Symphony es una interfaz LLM universal que proporciona una API compatible con OpenAI para implementar, gestionar y escalar aplicaciones de IA. Ofrece fiabilidad de nivel empresarial, hasta un 20% menos de costes y es compatible con más de 100 modelos de IA importantes como GPT-5 y Llama 4, lo que la convierte en la solución ideal para desarrolladores y empresas que buscan una infraestructura de IA eficiente y robusta.
SiliconFlow
SiliconFlow es una plataforma de infraestructura de IA unificada diseñada para la inferencia de alto rendimiento de Modelos …
SiliconFlow es una plataforma de infraestructura de IA unificada diseñada para la inferencia de alto rendimiento de Modelos de Lenguaje Grandes (LLMs) y modelos multimodales. Ofrece a desarrolladores y empresas opciones de despliegue escalables, rentables y flexibles, incluyendo APIs sin servidor, GPUs reservadas y capacidades de ajuste fino, todo accesible a través de una única API compatible con OpenAI.

Baseten
Baseten es una plataforma de inferencia de grado de producción para desplegar, escalar y gestionar modelos de IA. …
Baseten es una plataforma de inferencia de grado de producción para desplegar, escalar y gestionar modelos de IA. Ofrece tiempos de ejecución de alto rendimiento, flujos de trabajo de desarrollador fluidos y opciones de despliegue flexibles (nube, autohospedado, híbrido). Ideal para equipos de ingeniería y ML que construyen aplicaciones de IA de misión crítica.
Nexlayer
Nexlayer es la primera plataforma de nube nativa de agentes, diseñada para empoderar a los agentes de codificación …
Nexlayer es la primera plataforma de nube nativa de agentes, diseñada para empoderar a los agentes de codificación de IA para implementar aplicaciones listas para producción rápidamente. Automatiza infraestructuras complejas, permitiendo a desarrolladores y fundadores lanzar aplicaciones full-stack, APIs y bases de datos en minutos sin sobrecarga de DevOps.

Truefoundry
Truefoundry es una plataforma preparada para empresas para desplegar, gestionar y escalar aplicaciones de IA agéntica. Proporciona una …
Truefoundry es una plataforma preparada para empresas para desplegar, gestionar y escalar aplicaciones de IA agéntica. Proporciona una Puerta de Enlace de IA unificada para orquestar flujos de trabajo complejos de IA, gestionar modelos y garantizar la seguridad, la gobernanza y la observabilidad. Diseñada para desarrolladores y equipos de MLOps, admite despliegues en las instalaciones, en la nube e híbridos, optimizando la utilización de la GPU y acelerando el tiempo de comercialización.
Vespa.ai
Vespa.ai es una plataforma de búsqueda de IA de alto rendimiento para construir aplicaciones a gran escala. Unifica …
Vespa.ai es una plataforma de búsqueda de IA de alto rendimiento para construir aplicaciones a gran escala. Unifica la búsqueda vectorial, la búsqueda de texto y el ranking de aprendizaje automático para potenciar casos de uso avanzados como la Generación Aumentada por Recuperación (RAG), motores de recomendación y búsqueda inteligente. Diseñado para inferencia en tiempo real y escalabilidad, cuenta con la confianza de empresas líderes como Spotify y Perplexity para manejar conjuntos de datos masivos con baja latencia.

Nebius
Nebius es una plataforma en la nube de alto rendimiento diseñada específicamente para cargas de trabajo exigentes de …
Nebius es una plataforma en la nube de alto rendimiento diseñada específicamente para cargas de trabajo exigentes de IA y Machine Learning. Proporciona acceso escalable a las últimas GPUs de NVIDIA, desde instancias únicas hasta clústeres masivos, complementado con un conjunto de servicios gestionados y un AI Studio integrado para agilizar todo el ciclo de vida de ML, desde el entrenamiento hasta la inferencia.
novita.ai
Novita AI es una plataforma en la nube centrada en el desarrollador que ofrece acceso asequible y escalable …
Novita AI es una plataforma en la nube centrada en el desarrollador que ofrece acceso asequible y escalable a más de 200 modelos de IA a través de API sencillas. Proporciona GPU sin servidor, instancias de GPU dedicadas y despliegue de modelos personalizados, permitiendo a los desarrolladores construir y escalar aplicaciones de IA sin gestionar la infraestructura.
Avian Categoría
Avian Etiquetas
Avian Profesiones aplicables
Avian Herramienta de IA
Avian Función de incrustar
Simplemente copie el código de inserción de abajo y pegue la insignia en su blog, artículo o sitio web oficial para dirigir el tráfico directamente a la página de detalles de esta herramienta, ¡aumentando rápidamente la exposición y el número de usuarios!

Aún no hay comentarios, ¡sé el primero en comentar!