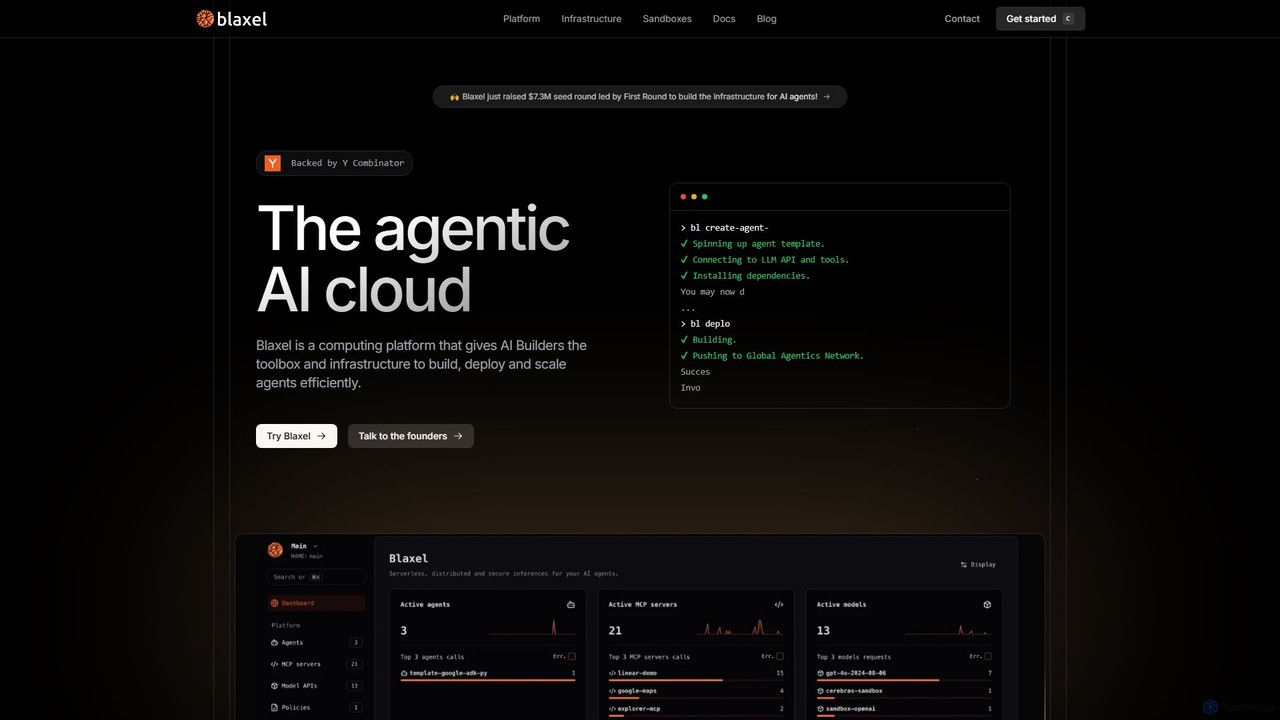
Blaxel
Blaxel est une plateforme de calcul sans serveur conçue pour les développeurs d'IA, fournissant l'infrastructure et les outils …
Blaxel est une plateforme de calcul sans serveur conçue pour les développeurs d'IA, fournissant l'infrastructure et les outils pour construire, déployer et faire évoluer efficacement des applications d'IA agentiques. Elle offre des VM en bac à sable, une passerelle LLM unifiée et une observabilité approfondie.
À propos de Cloud computing
Les plateformes de Cloud Computing fournissent un accès à la demande à des ressources de calcul évolutives, essentielles pour le développement et le déploiement d'applications d'IA. Ces plateformes offrent du matériel virtualisé, tel que de puissants GPU et TPU, ainsi que de vastes capacités de stockage et de réseau, éliminant le besoin d'un investissement initial important dans une infrastructure physique. Cela permet aux équipes d'entraîner des modèles complexes, de traiter des ensembles de données massifs et d'héberger des services d'IA avec une haute disponibilité et une grande flexibilité. Le modèle de paiement à l'usage rend le développement d'IA de pointe accessible à tous, des chercheurs individuels aux grandes entreprises.
Fonctionnalités Clés
- Accélération GPU/TPU : Fournit un accès à des processeurs spécialisés conçus pour accélérer les tâches d'entraînement et d'inférence des modèles de machine learning.
- Stockage de données évolutif : Offre des solutions de stockage d'objets (comme Amazon S3 ou Google Cloud Storage) capables de contenir des pétaoctets de données pour les ensembles d'entraînement.
- Plateformes d'IA/ML gérées : Propose des environnements intégrés (par ex., SageMaker, Azure ML) qui rationalisent l'ensemble du cycle de vie du machine learning, de la préparation des données au déploiement du modèle.
- Informatique sans serveur (Serverless) : Permet le déploiement de modèles d'IA en tant que points de terminaison qui s'adaptent automatiquement à la demande, optimisant les coûts et les performances pour l'inférence.
- Calcul haute performance (HPC) : Offre des grappes d'ordinateurs interconnectés pour exécuter des simulations à grande échelle et des tâches de calcul complexes requises pour la recherche avancée en IA.
Cas d'Usage
Le Cloud Computing est fondamental pour les data scientists, les ingénieurs en machine learning et les startups axées sur l'IA. Il est utilisé pour entraîner de grands modèles de langage (LLM) qui nécessitent une immense puissance de calcul, pour déployer des API de vision par ordinateur en temps réel pour des applications comme la conduite autonome, et pour exécuter des pipelines d'analyse de big data afin d'extraire des informations pour la construction de modèles.
Comment Choisir
Lors de la sélection d'un fournisseur de Cloud Computing pour l'IA, tenez compte de la disponibilité et des performances des modèles spécifiques de GPU/TPU. Évaluez la maturité et l'ensemble des fonctionnalités de leurs plateformes d'IA/ML gérées. Analysez les modèles de tarification pour les tâches d'entraînement de longue durée et les charges de travail d'inférence sporadiques. Évaluez également la sécurité des données, les certifications de conformité et l'intégration avec les outils MLOps existants.
Cloud computingCas d'utilisation
Entraînement d'un modèle de deep learning à grande échelle
Une équipe de data science d'une entreprise technologique doit entraîner un nouveau modèle de vision par ordinateur sur un jeu de données de plus de 10 millions d'images. L'utilisation d'un serveur sur site prendrait des semaines. À la place, ils utilisent une plateforme de cloud computing pour lancer un cluster de 16 instances GPU haute performance. Ils utilisent le stockage de données géré de la plateforme pour héberger le jeu de données et un environnement de deep learning préconfiguré pour gérer les dépendances. Cette capacité de traitement parallèle réduit le temps d'entraînement de plusieurs semaines à seulement 48 heures, permettant une itération et une amélioration plus rapides du modèle.
Déploiement d'une API d'inférence IA évolutive
Une startup a développé un outil de correction grammaticale basé sur l'IA et doit le servir à des milliers d'utilisateurs simultanés. Construire et maintenir l'infrastructure pour gérer un trafic fluctuant est complexe et coûteux. Ils optent pour un service de calcul sans serveur d'un grand fournisseur de cloud. Ils empaquettent leur modèle dans un conteneur et le déploient en tant que fonction sans serveur. La plateforme gère automatiquement la mise à l'échelle, l'approvisionnement et la maintenance. Cette approche leur permet de ne payer que pour le temps de calcul réellement utilisé, réduisant considérablement les coûts opérationnels et garantissant une expérience réactive pour tous les utilisateurs, même pendant les pics de demande.
Exécution du traitement Big Data pour l'ingénierie des fonctionnalités
Un ingénieur ML doit traiter des téraoctets de données de logs utilisateurs brutes pour créer des fonctionnalités pour un moteur de recommandation. Une seule machine ne peut pas gérer ce volume. L'ingénieur utilise un service de big data géré sur le cloud, comme Apache Spark sur EMR ou Dataproc. Il écrit un script pour nettoyer, transformer et agréger les données, puis l'exécute sur un cluster de dizaines de machines provisionné dynamiquement. Le service cloud gère la gestion du cluster, et la tâche se termine en quelques heures au lieu de jours. L'ensemble de fonctionnalités résultant est ensuite stocké dans le stockage cloud, prêt pour l'entraînement du modèle.
Construction d'un pipeline MLOps de bout en bout
Une équipe d'IA d'entreprise souhaite automatiser l'ensemble de son flux de travail de machine learning pour garantir la reproductibilité et accélérer le déploiement. Ils utilisent une plateforme d'IA gérée d'un fournisseur de cloud. Cette plateforme intègre des outils pour le versionnage des données, le suivi des expériences, l'entraînement automatisé de modèles (AutoML), un registre de modèles et le CI/CD pour le déploiement. Un ingénieur ML définit l'ensemble du pipeline, de l'ingestion des données à la surveillance du modèle en production. Lorsque de nouvelles données sont disponibles, le pipeline se déclenche automatiquement, réentraîne le modèle, exécute des tests et déploie la nouvelle version si elle répond aux critères de performance, le tout dans un environnement cloud unifié.
Affinage d'un modèle de langage fondamental
Une startup de technologie juridique souhaite créer un assistant IA spécialisé pour l'analyse de contrats. Au lieu de construire un grand modèle de langage (LLM) à partir de zéro, ils décident d'affiner un modèle open-source puissant sur leur jeu de données propriétaire de documents juridiques. Ils utilisent une plateforme cloud pour louer une instance GPU à haute mémoire (comme une A100) pour quelques jours. Ils téléchargent leur jeu de données sur un stockage cloud sécurisé et utilisent un framework d'entraînement populaire pour exécuter le processus d'affinage. Le cloud fournit la puissance de calcul nécessaire sur une base temporaire et rentable, leur permettant de créer un actif IA hautement spécialisé et précieux sans posséder de matériel coûteux.
Hébergement d'un environnement de science des données collaboratif
Une équipe de data scientists distribuée a besoin d'un environnement centralisé pour collaborer sur un projet. La configuration d'environnements locaux individuels entraîne des conflits de version et des incohérences. Le chef d'équipe utilise un service de notebooks géré d'un fournisseur de cloud (comme Amazon SageMaker Studio ou Google Vertex AI Workbench). Cela fournit à chaque membre de l'équipe une instance JupyterLab conteneurisée et basée sur le cloud avec un accès partagé aux jeux de données et aux dépôts de code. Cela garantit que tout le monde travaille avec les mêmes outils et données, rationalise la collaboration et permet au chef d'équipe de suivre facilement les progrès et de gérer les ressources sans aucune configuration d'infrastructure.