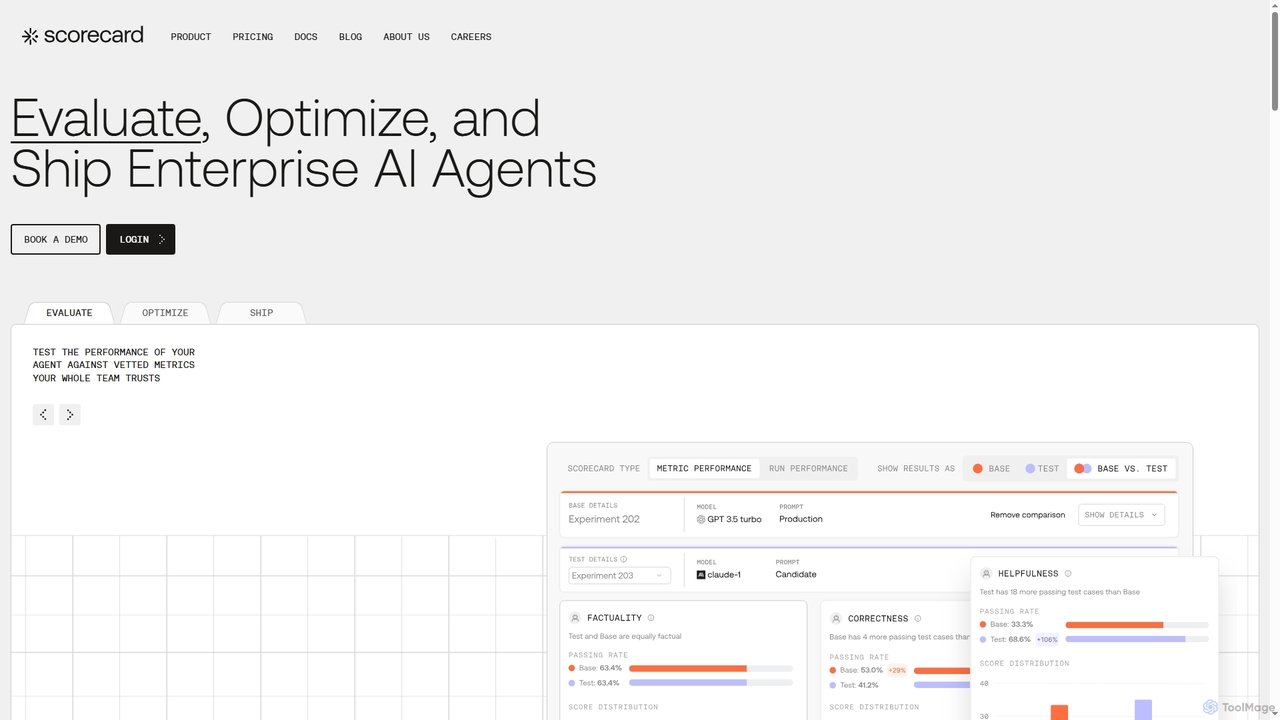
Scorecard
Scorecard est une plateforme de bout en bout pour évaluer, optimiser et déployer des agents IA d'entreprise. Elle …
Scorecard est une plateforme de bout en bout pour évaluer, optimiser et déployer des agents IA d'entreprise. Elle aide les équipes à remplacer les tests subjectifs par des évaluations structurées, en fournissant des outils de surveillance continue, de gestion des prompts et de métriques de performance pour construire des applications IA fiables et dignes de confiance.
À propos de Évaluation
Les outils d'évaluation sont des solutions basées sur l'IA conçues pour évaluer systématiquement les performances, l'équité et la robustesse des modèles d'IA. Ces outils exploitent diverses métriques, ensembles de données de test et cadres analytiques pour fournir des informations approfondies sur le comportement du modèle. Leur objectif principal est de garantir que les modèles sont fiables, précis et éthiquement solides avant et après le déploiement, jouant un rôle critique dans le cycle de vie plus large de la gestion des modèles d'IA.
Fonctionnalités Clés
- Calcul des Métriques de Performance: Quantifie la précision, l'exactitude, le rappel, le score F1 et d'autres métriques pertinentes du modèle.
- Détection et Atténuation des Biais: Identifie et mesure les biais algorithmiques à travers différents groupes démographiques ou segments de données.
- Tests de Robustesse: Évalue la stabilité et la résilience du modèle face aux attaques adverses ou aux changements inattendus de données.
- Intégration de l'Explicabilité (XAI): Fournit des informations sur les raisons pour lesquelles un modèle a fait une prédiction particulière, améliorant la transparence.
- Comparaison des Versions de Modèles: Compare les performances de différentes itérations ou versions de modèles pour suivre les améliorations.
Cas d'Utilisation
Les outils d'évaluation des modèles d'IA sont essentiels à diverses étapes du cycle de vie de l'IA. Les scientifiques des données les utilisent pour une validation rigoureuse avant le déploiement, garantissant que les nouveaux modèles respectent les critères de performance. Les équipes MLOps s'appuient sur eux pour la surveillance continue des modèles déployés, détectant la dérive des performances ou les problèmes de qualité des données. De plus, les chercheurs et les développeurs exploitent ces outils pour comparer différentes architectures de modèles et optimiser leurs solutions d'IA.
Comment Choisir
Le choix d'un outil d'évaluation de modèles d'IA nécessite de prendre en compte plusieurs facteurs. Privilégiez les outils qui prennent en charge une gamme complète de métriques d'évaluation pertinentes pour votre type de modèle et vos objectifs commerciaux. Recherchez de solides capacités d'intégration avec vos pipelines MLOps et sources de données existants. L'évolutivité, les fonctionnalités d'interprétabilité et les fonctionnalités de reporting robustes sont également cruciales pour une gouvernance et une conformité efficaces des modèles.
ÉvaluationCas d'utilisation
Validation de Modèle Avant Déploiement
Les scientifiques des données utilisent des outils d'évaluation pour tester rigoureusement les nouveaux modèles d'IA, tels qu'un système de détection de fraude, contre divers ensembles de données avant le déploiement. Cela garantit que le modèle respecte les critères de précision et de fiabilité, identifiant les faiblesses potentielles ou les cas limites qui pourraient entraîner des erreurs coûteuses en production. Le processus aide à valider la préparation du modèle pour une application dans le monde réel, minimisant les risques.
Évaluation des Biais et de l'Équité
Les éthiciens et développeurs d'IA utilisent des plateformes d'évaluation pour détecter et quantifier systématiquement les biais au sein des modèles, tels que ceux utilisés pour les demandes de prêt ou le recrutement. En analysant les prédictions à travers différents groupes démographiques, ils peuvent identifier les résultats injustes, comprendre leurs causes profondes et mettre en œuvre des stratégies pour atténuer les comportements discriminatoires, garantissant un déploiement éthique de l'IA.
Surveillance Continue des Performances
Les ingénieurs MLOps intègrent des outils d'évaluation dans leurs pipelines de production pour surveiller en continu les performances des modèles d'IA déployés, tels que les moteurs de recommandation. Ces outils suivent les métriques clés au fil du temps, alertant les équipes en cas de dégradation des performances, de dérive des données ou de dérive conceptuelle, permettant une intervention proactive pour maintenir la précision et la pertinence du modèle.
Sélection Comparative de Modèles
Les chercheurs en apprentissage automatique utilisent des outils d'évaluation pour comparer les performances de plusieurs modèles candidats ou de différentes versions du même modèle. Par exemple, lors du développement d'un modèle de traitement du langage naturel, ils peuvent évaluer objectivement quelle architecture ou quel ensemble d'hyperparamètres donne les meilleurs résultats pour diverses tâches linguistiques, guidant ainsi la sélection optimale du modèle.
Rapports de Conformité Réglementaire
Les entreprises des secteurs réglementés, comme la finance ou la santé, utilisent des outils d'évaluation pour générer des pistes d'audit complètes et des rapports de performance pour leurs systèmes d'IA. Cela aide à démontrer l'adhésion aux normes de l'industrie et aux exigences réglementaires, telles que les mandats d'explicabilité ou les directives d'équité, offrant transparence et responsabilité aux auditeurs et aux parties prenantes.
Tests de Robustesse Adversariale
Les spécialistes de la sécurité appliquent des outils d'évaluation pour tester les modèles d'IA, en particulier dans des applications critiques comme la conduite autonome ou la cybersécurité, contre les attaques adversariales. En simulant des entrées malveillantes conçues pour tromper le modèle, ils peuvent évaluer sa robustesse et identifier les vulnérabilités, renforçant la résilience du modèle contre les menaces sophistiquées et assurant sa fiabilité dans des environnements hostiles.