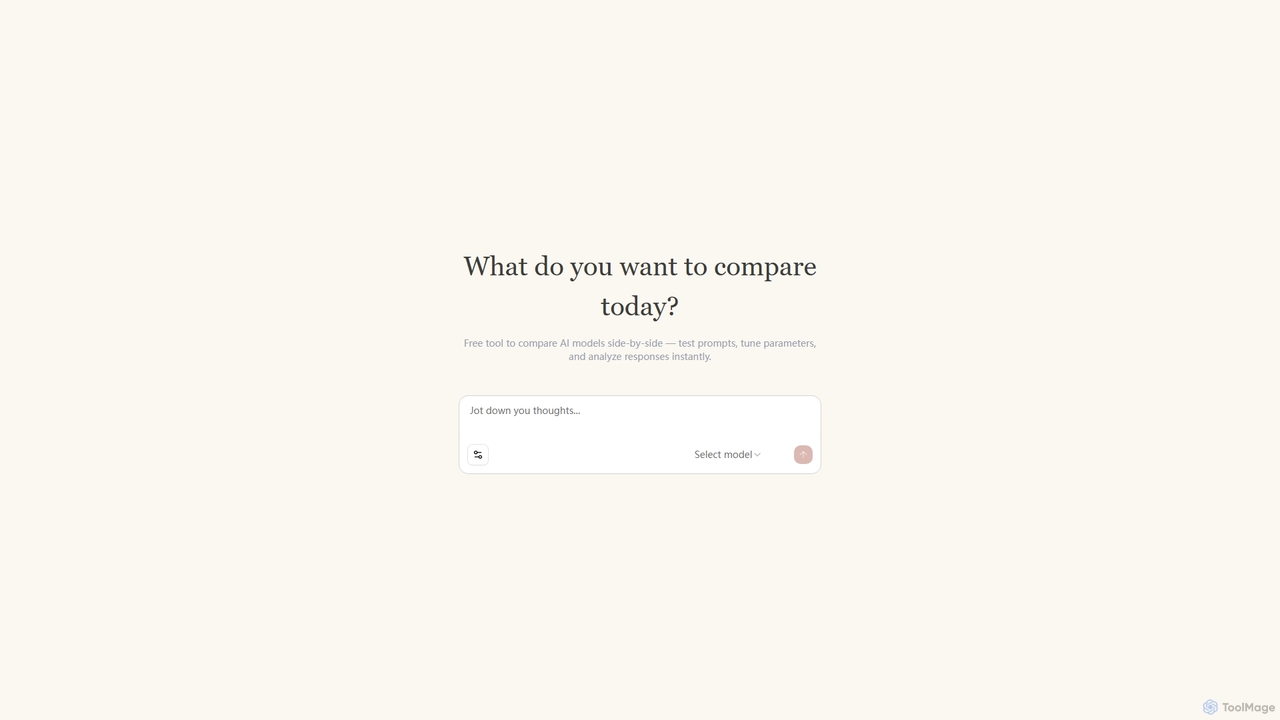
Llm Lab Three
Un outil gratuit pour les développeurs et les chercheurs permettant de comparer les grands modèles de langage (LLM) …
Un outil gratuit pour les développeurs et les chercheurs permettant de comparer les grands modèles de langage (LLM) côte à côte. Testez des prompts, ajustez les paramètres et analysez instantanément les réponses pour trouver le modèle optimal pour n'importe quelle tâche.
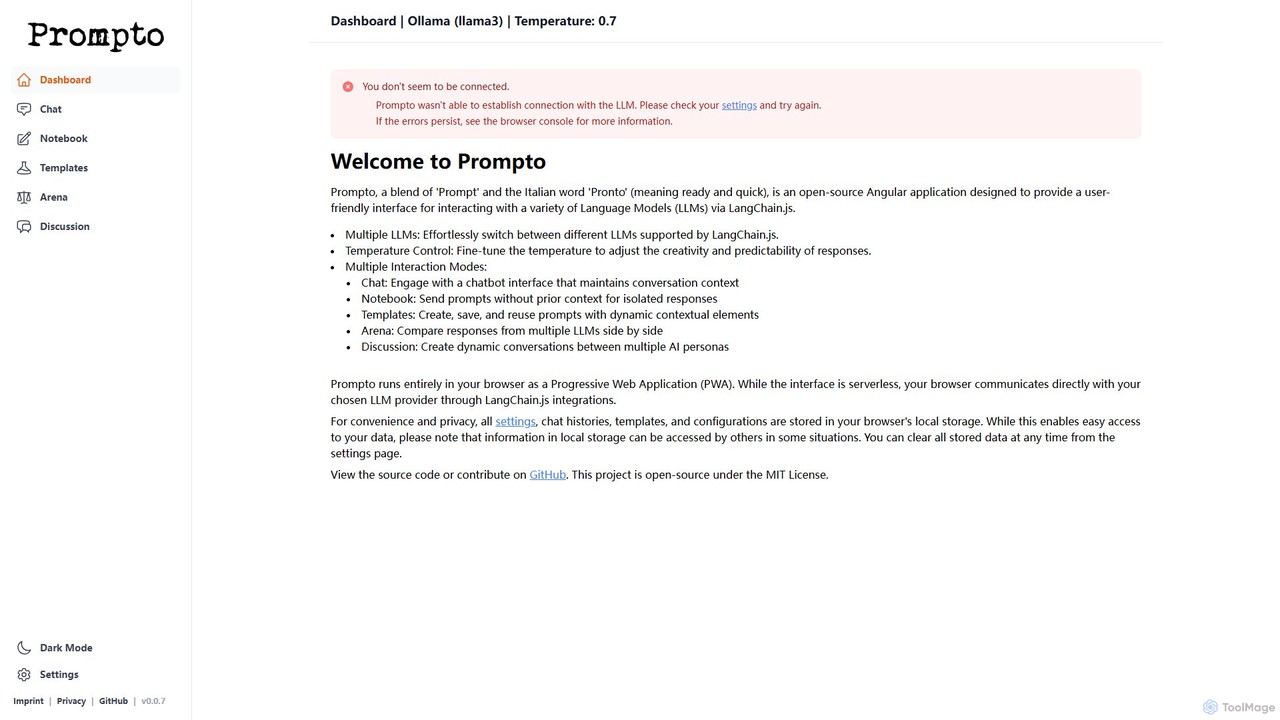
Prompto
Prompto est une interface gratuite, open-source et basée sur un navigateur pour interagir avec une large gamme de …
Prompto est une interface gratuite, open-source et basée sur un navigateur pour interagir avec une large gamme de grands modèles de langage (LLM). Il utilise LangChain.js pour se connecter directement à des fournisseurs comme OpenAI, Anthropic et des modèles locaux via Ollama, offrant des fonctionnalités avancées telles qu'une arène de comparaison de modèles, des modèles de prompts et des discussions multi-IA, tout en priorisant la confidentialité de l'utilisateur en stockant les données localement.
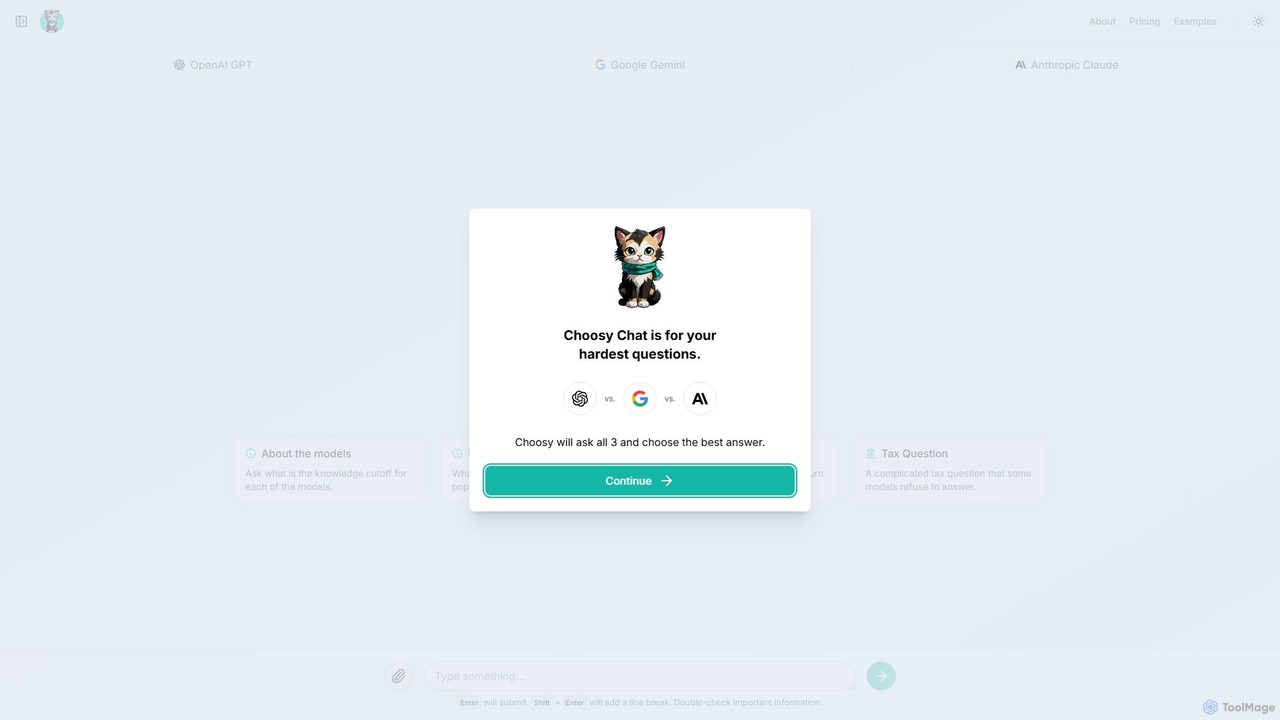
Choosy Chat
Choosy Chat est un outil d'IA qui envoie simultanément votre prompt à GPT, Gemini et Claude, vous permettant …
Choosy Chat est un outil d'IA qui envoie simultanément votre prompt à GPT, Gemini et Claude, vous permettant de comparer leurs réponses côte à côte. Il vous aide à trouver la meilleure réponse possible pour toute requête, du codage à l'écriture créative.
À propos de Comparaison de modèles
Les outils de Comparaison de modèles sont des plateformes spécialisées pour évaluer et comparer les performances de différents modèles d'IA côte à côte. Ces outils fournissent un environnement structuré pour tester les modèles à l'aide d'ensembles de données standardisés, de prompts personnalisés et d'indicateurs de performance clés tels que la précision, la vitesse et le coût. Ils sont essentiels pour les développeurs, les chercheurs et les entreprises afin de prendre des décisions basées sur les données lors de la sélection du modèle d'IA le plus adapté à une application spécifique. Cela permet une analyse objective au-delà des arguments marketing, garantissant des performances et une rentabilité optimales.
Fonctionnalités Clés
- Interface Côte à Côte : Comparez directement les sorties des modèles pour le même prompt dans une vue unifiée.
- Benchmarking Automatisé : Exécutez des tests standardisés (par ex., MMLU, HellaSwag) pour mesurer les performances objectives.
- Analyse des Coûts et de la Latence : Suivez les coûts de l'API et les temps de réponse pour évaluer l'efficacité des différents modèles.
- Classements Qualitatifs : Accédez à des classements participatifs ou d'experts basés sur la préférence humaine et la qualité.
- Suites de Tests Personnalisées : Téléchargez vos propres ensembles de données et prompts pour évaluer les modèles sur des tâches spécifiques à votre domaine.
Cas d'Utilisation
Ces outils sont largement utilisés par les développeurs d'IA qui sélectionnent un modèle de fondation pour une nouvelle application, les équipes MLOps qui surveillent la dégradation des modèles, et les chefs de produit qui comparent le rapport coût-performance de fournisseurs comme OpenAI, Anthropic et Google. Les chercheurs les utilisent également pour valider les performances de nouveaux modèles par rapport à des benchmarks établis.
Comment Choisir
Lors de la sélection d'un outil, tenez compte de la gamme de modèles pris en charge (open-source vs propriétaire), des métriques d'évaluation et des benchmarks disponibles, de la possibilité d'utiliser des données personnalisées pour les tests, et si vous avez besoin d'une interface utilisateur conviviale, d'une API pour l'automatisation, ou des deux. Évaluez également le modèle de tarification pour vous assurer qu'il correspond à votre volume de tests.
Comparaison de modèlesCas d'utilisation
Sélection d'un LLM pour un Chatbot de Service Client
Un chef de produit d'une entreprise de commerce électronique doit choisir un Grand Modèle de Langage (LLM) pour son nouveau chatbot IA. À l'aide d'un outil de comparaison de modèles, il crée une suite de tests avec 100 requêtes clients courantes. Il exécute cette suite sur des modèles comme GPT-4, Claude 3 et Llama 3, en les comparant sur la précision des réponses, la politesse, la latence et le coût pour 1 000 requêtes. La vue côte à côte de la plateforme révèle que Claude 3 offre le meilleur équilibre entre qualité et coût pour son cas d'utilisation spécifique, permettant une décision basée sur les données en quelques heures au lieu de semaines de tests manuels.
Benchmarking d'un Modèle Open-Source Affiné
Une équipe d'ingénierie ML a affiné un modèle Llama 3 sur la base de connaissances interne de son entreprise. Pour valider son efficacité, elle utilise une plateforme de comparaison de modèles pour le benchmarker par rapport au modèle Llama 3 de base et à GPT-4. Ils exécutent des tests standards de l'industrie comme MMLU pour les connaissances générales et un ensemble de tests personnalisés de 50 paires de Q&R internes. Les résultats montrent que leur modèle affiné surpasse le modèle de base de 30 % sur les questions internes, justifiant ainsi les ressources consacrées à l'affinage.
Optimisation des Coûts pour une Fonctionnalité de Contenu IA
Une startup propose une fonctionnalité d'IA qui résume des articles pour les utilisateurs. Alors que la croissance des utilisateurs s'accélère, le coût de leur API de modèle haut de gamme actuelle devient une préoccupation. L'équipe de développement utilise un outil de comparaison de modèles pour tester des modèles moins chers et plus petits sur leur tâche de résumé. Ils comparent les sorties en termes de qualité, de cohérence et de longueur, tout en surveillant le tableau de bord d'analyse des coûts. Ils découvrent un modèle distillé plus petit qui offre 95 % de la qualité pour seulement 40 % du coût, améliorant ainsi considérablement leurs marges bénéficiaires.
Test A/B de Modèles de Génération d'Images pour le Marketing
Une équipe marketing doit générer des visuels pour une nouvelle campagne publicitaire. Ils ne savent pas s'il faut utiliser Midjourney, Stable Diffusion ou DALL-E 3 pour l'esthétique souhaitée. Ils utilisent un outil de comparaison de modèles pour saisir le même ensemble de prompts créatifs dans les trois modèles. La plateforme organise les sorties, permettant à l'équipe de voter et de classer les images générées en fonction de l'alignement avec la marque, de l'attrait visuel et de la créativité. Ce processus structuré les aide à identifier rapidement Stable Diffusion comme étant le plus adapté au style de leur campagne.
Recherche Académique sur les Capacités des Modèles
Un chercheur universitaire étudie les capacités de raisonnement des derniers modèles d'IA. Il exploite l'API d'une plateforme de comparaison de modèles pour exécuter par programme des milliers de puzzles logiques et de problèmes mathématiques sur une douzaine de modèles différents. L'outil automatise les tests, collecte les résultats et fournit des scores de précision agrégés. Cela permet au chercheur d'économiser des centaines d'heures de script et d'exécution manuels, lui permettant de se concentrer sur l'analyse des données et la publication de ses découvertes sur les tendances de performance des modèles.
Choisir un Modèle de Génération de Code pour les Outils de Développement
Une entreprise qui développe un plugin IDE souhaite ajouter une fonctionnalité de complétion de code par IA. Le responsable technique doit choisir entre des modèles comme GitHub Copilot (basé sur GPT), Code Llama et d'autres modèles de codage spécialisés. Ils utilisent un outil de comparaison de modèles avec une suite de benchmarks comme HumanEval. Cela leur permet de mesurer objectivement la capacité de chaque modèle à générer des extraits de code corrects et efficaces dans divers langages de programmation, garantissant ainsi l'intégration de l'option la plus fiable et la plus performante pour leurs utilisateurs.