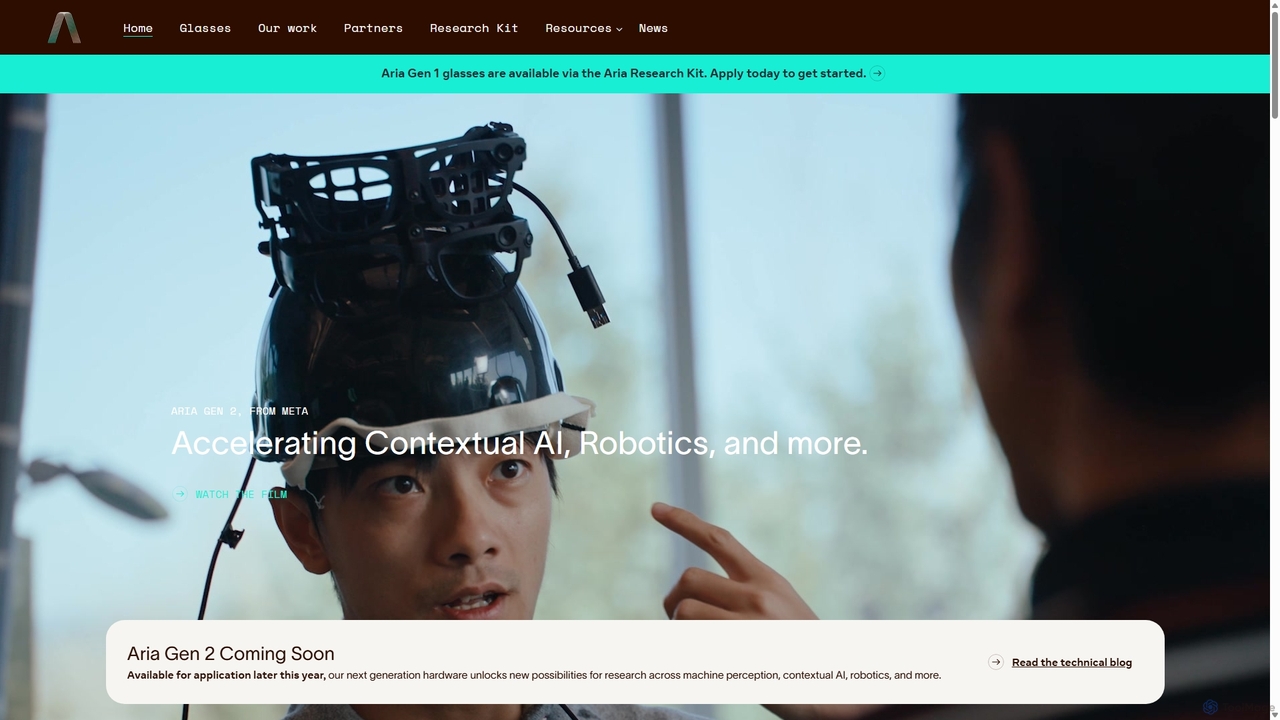
Project Aria
Project Aria est une initiative de recherche de Meta conçue pour accélérer le développement de l'IA contextuelle, de …
Project Aria est une initiative de recherche de Meta conçue pour accélérer le développement de l'IA contextuelle, de la réalité augmentée (RA) et de la robotique. Il utilise des lunettes de recherche avancées, comme les Aria Gen 2, pour capturer des données en perspective à la première personne, offrant aux chercheurs une plateforme complète incluant du matériel, des jeux de données open source et des outils de développement pour construire l'avenir de la perception machine.

Allen Institute for AI (AI2)
L'Allen Institute for AI (AI2) est un institut de recherche à but non lucratif dédié à la création …
L'Allen Institute for AI (AI2) est un institut de recherche à but non lucratif dédié à la création d'IA révolutionnaire pour le bien commun. Il se concentre sur la création de grands modèles de langage véritablement open source comme OLMo, de jeux de données complets et d'outils d'IA spécialisés pour faire progresser la recherche scientifique et relever les grands défis mondiaux dans des domaines tels que la science du climat, la conservation et la médecine.
À propos de Ensembles de données
Les ensembles de données sont des collections de données organisées utilisées pour entraîner, valider et tester des modèles d'intelligence artificielle. Ces collections, qui peuvent inclure des images, du texte, de l'audio ou des données numériques, fournissent les connaissances fondamentales permettant aux algorithmes d'apprentissage automatique d'apprendre des modèles et de faire des prédictions. L'accès à des ensembles de données pertinents et de haute qualité est une première étape essentielle dans le développement d'applications d'IA efficaces, des systèmes de vision par ordinateur aux processeurs de langage naturel. Ils servent de « manuels » à partir desquels l'IA apprend, influençant directement la précision et les performances du modèle final.
Fonctionnalités Clés
- Données Structurées et Étiquetées : Les données sont souvent organisées et annotées avec des étiquettes (par ex., « chat » ou « chien » pour les images) pour faciliter l'apprentissage supervisé.
- Types de Données Variés : Comprend une large gamme de formats tels que des images, des documents texte, des clips audio et des données tabulaires pour prendre en charge diverses tâches d'IA.
- Division des Données : Généralement pré-divisés en ensembles d'entraînement, de validation et de test pour assurer une évaluation correcte du modèle et prévenir le surajustement.
- Métadonnées Complètes : Accompagnés d'une documentation détaillée expliquant les sources de données, les méthodes de collecte et les informations de licence.
Cas d'Utilisation
Les ensembles de données sont fondamentaux dans la recherche universitaire et le développement commercial de l'IA. Ils sont utilisés par les scientifiques des données pour entraîner des modèles d'apprentissage automatique personnalisés, par les chercheurs pour évaluer les performances des algorithmes par rapport à des normes établies, et par les développeurs pour affiner des modèles pré-entraînés pour des tâches spécifiques comme l'analyse des sentiments ou la détection d'objets.
Comment Choisir
Lors de la sélection d'un ensemble de données, tenez compte de sa pertinence par rapport à votre problème spécifique et de sa qualité globale, y compris la précision des étiquettes et l'absence de biais. Évaluez également la taille de l'ensemble de données — il doit être suffisamment grand pour que votre modèle apprenne efficacement. Enfin, vérifiez les termes de la licence pour vous assurer qu'ils autorisent votre utilisation prévue, que ce soit à des fins commerciales ou universitaires.
Ensembles de donnéesCas d'utilisation
Entraîner un Modèle de Reconnaissance d'Image Personnalisé
Un ingénieur en vision par ordinateur doit construire un modèle pour identifier des défauts de fabrication spécifiques. Il utilise un ensemble de données d'images de produits étiquetées de haute qualité, où chaque image est annotée comme « conforme » ou « non conforme » avec le type de défaut. En entraînant son réseau de neurones convolutifs (CNN) sur cet ensemble de données, le modèle apprend à distinguer les produits sans défaut des divers défauts, automatisant ainsi le processus de contrôle qualité et augmentant la précision de la détection.
Affiner un Modèle de Langage pour le Support Client
Une startup souhaite créer un chatbot spécialisé pour son secteur. Un spécialiste de l'apprentissage automatique prend un grand modèle de langage pré-entraîné et l'affine à l'aide d'un ensemble de données organisé de demandes de clients spécifiques au secteur et des réponses d'experts correspondantes. Ce processus adapte le modèle général pour comprendre la terminologie de niche et fournir des réponses pertinentes et précises, améliorant considérablement l'expérience du support client.
Évaluer un Nouvel Algorithme de Recommandation
Une équipe de science des données a développé un nouvel algorithme pour un moteur de recommandation de films. Pour prouver son efficacité, ils le testent sur un ensemble de données public et standard de l'industrie comme MovieLens. Ils comparent la précision de prédiction de leur algorithme (par exemple, sa capacité à prédire les notes des utilisateurs) aux benchmarks établis. Cela permet une évaluation et une validation objectives des performances avant de déployer le nouveau système.
Développer un Appareil Domotique à Commande Vocale
Un développeur IoT crée un appareil qui répond aux commandes vocales. Il utilise un grand ensemble de données audio contenant des milliers d'heures de commandes parlées par divers locuteurs avec différents accents et dans divers environnements acoustiques. Cet ensemble de données est utilisé pour entraîner un modèle de reconnaissance vocale, garantissant que l'appareil peut comprendre de manière fiable les commandes de l'utilisateur comme « allume les lumières » ou « règle une minuterie » dans des conditions réelles.
Créer un Assistant IA pour le Diagnostic Médical
Un institut de recherche médicale vise à créer un outil d'IA pour aider les radiologues à détecter les tumeurs à partir de scanners IRM. Ils utilisent un ensemble de données spécialisé et anonymisé d'images médicales, où chaque scan est étiqueté par des radiologues experts. L'entraînement d'un modèle sur cet ensemble de données aide à créer un système qui peut mettre en évidence les zones potentiellement préoccupantes, servant de deuxième avis et améliorant potentiellement la vitesse et la précision du diagnostic.
Effectuer une Analyse des Sentiments pour une Étude de Marché
Un analyste marketing souhaite évaluer l'opinion publique sur le lancement d'un nouveau produit. Il utilise un ensemble de données de publications sur les réseaux sociaux et d'avis sur les produits, chacun étant étiqueté avec un sentiment (positif, négatif, neutre). En entraînant un modèle de traitement du langage naturel (NLP) sur ces données, il peut analyser automatiquement des milliers de nouveaux commentaires, fournissant des informations en temps réel sur la satisfaction des clients et identifiant les domaines à améliorer.