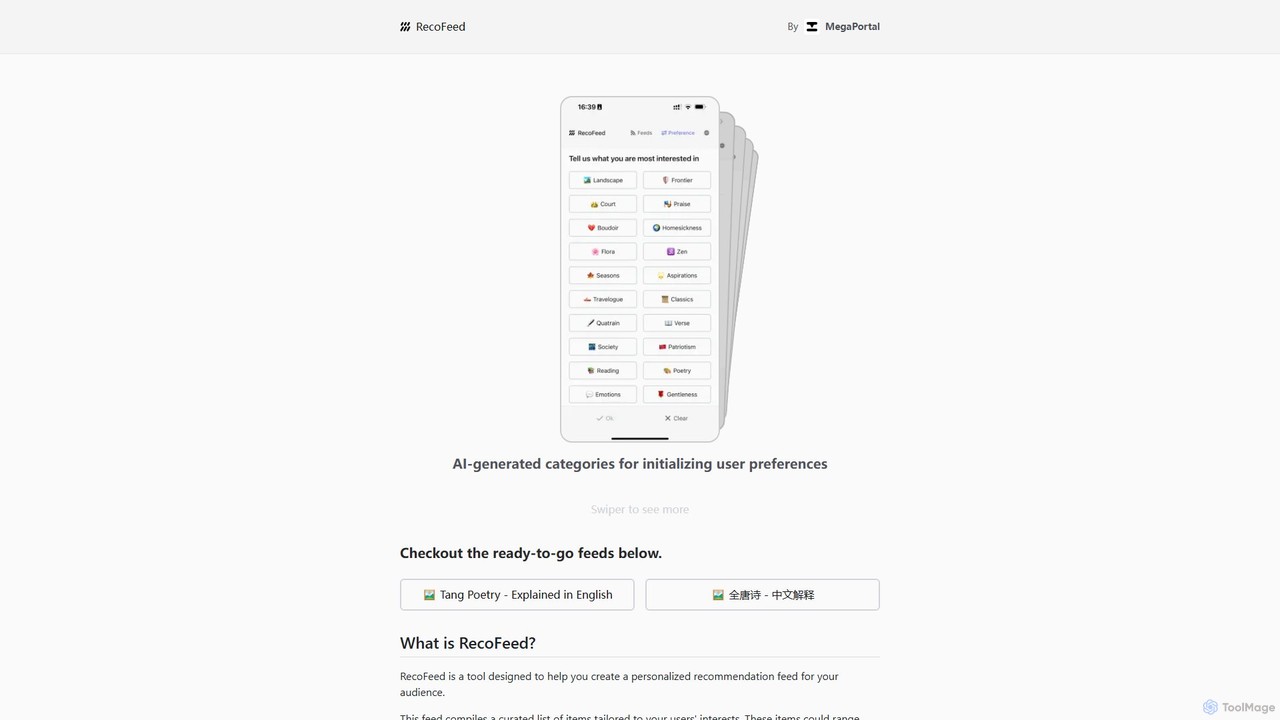
RecoFeed
RecoFeed est un outil destiné aux développeurs pour créer des flux de recommandation personnalisés. Il utilise une base …
RecoFeed est un outil destiné aux développeurs pour créer des flux de recommandation personnalisés. Il utilise une base de données vectorielle sur l'appareil, CloseVector, pour générer des suggestions en temps réel localement sur l'appareil de l'utilisateur, garantissant une confidentialité maximale des données et une faible latence. Il est conçu pour les applications et les sites web dans divers secteurs tels que le e-commerce, les plateformes de contenu et les médias sociaux.
À propos de Base de données vectorielle
Une base de données vectorielle est un système de base de données spécialisé conçu pour stocker, gérer et rechercher efficacement des plongements vectoriels de haute dimension. Contrairement aux bases de données traditionnelles qui indexent les données sur la base de valeurs exactes, les bases de données vectorielles utilisent des algorithmes de plus proches voisins approximatifs (ANN) pour trouver les éléments les plus similaires en fonction de leurs représentations vectorielles. Cette capacité est fondamentale pour alimenter des applications d'IA avancées telles que la recherche sémantique, les moteurs de recommandation et la génération augmentée par récupération (RAG) pour les grands modèles de langage. Elles offrent une vitesse et une évolutivité exceptionnelles pour les tâches de recherche par similarité sur des ensembles de données massifs et non structurés comme le texte, les images et l'audio.
Fonctionnalités Clés
- Indexation de vecteurs de haute dimension : Organise efficacement les données vectorielles à l'aide d'algorithmes comme HNSW ou IVF pour une récupération rapide.
- Recherche par similarité : Effectue des recherches basées sur la proximité vectorielle (par ex., similarité cosinus, distance euclidienne) pour trouver des éléments sémantiquement similaires.
- Évolutivité et performance : Conçue pour gérer des milliards de vecteurs et des charges de requêtes élevées avec une faible latence, ce qui est crucial pour les applications en temps réel.
- Filtrage des métadonnées : Combine la recherche par similarité vectorielle avec le filtrage de métadonnées traditionnel pour des résultats plus précis et contextuels.
Cas d'utilisation
Les bases de données vectorielles sont essentielles pour les ingénieurs IA/ML, les scientifiques des données et les développeurs qui créent des applications nécessitant la compréhension des relations sémantiques dans les données. Elles sont largement utilisées dans le commerce électronique pour la recherche visuelle et les recommandations, dans les systèmes d'entreprise pour la recherche intelligente dans les bases de connaissances, et dans l'IA générative pour fournir un contexte factuel aux grands modèles de langage, réduisant ainsi les inexactitudes.
Comment choisir
Lors de la sélection d'une base de données vectorielle, évaluez ses algorithmes d'indexation et ses benchmarks de performance pour votre type de données spécifique. Considérez le modèle de déploiement : les services gérés dans le cloud offrent une facilité d'utilisation, tandis que les options auto-hébergées offrent plus de contrôle. Vérifiez également la disponibilité de SDK robustes dans vos langages de programmation préférés et les intégrations avec des frameworks d'IA populaires comme LangChain ou LlamaIndex. Enfin, évaluez son évolutivité et son modèle de tarification pour vous assurer qu'il répond à vos besoins à long terme.
Base de données vectorielleCas d'utilisation
Alimenter les chatbots IA avec la génération augmentée par récupération (RAG)
Un développeur IA est chargé de créer un chatbot de support client qui doit fournir des réponses précises à partir d'une base de connaissances privée, telle que des manuels de produits et des FAQ internes. Pour ce faire, les documents sont segmentés, convertis en plongements vectoriels et stockés dans une base de données vectorielle. Lorsqu'un utilisateur pose une question, sa requête est vectorisée et utilisée pour rechercher les morceaux de documents les plus pertinents dans la base de données. Ces morceaux récupérés sont ensuite transmis à un grand modèle de langage (LLM) en tant que contexte, permettant au chatbot de générer des réponses précises et contextuelles basées sur des données propriétaires et de réduire considérablement le risque d'hallucinations.
Mise en œuvre de la recherche sémantique pour les documents internes
Un gestionnaire de connaissances dans une grande entreprise doit améliorer la manière dont les employés trouvent des informations parmi des milliers de rapports internes et de documents de politique. La recherche par mots-clés traditionnelle est inefficace, échouant souvent à faire remonter du contenu conceptuellement lié. En mettant en œuvre une base de données vectorielle, tous les documents sont vectorisés pour capturer leur signification sémantique. Les employés peuvent désormais effectuer des recherches en utilisant des questions en langage naturel. Le système effectue une recherche par similarité pour récupérer des documents en fonction de leur pertinence conceptuelle, et non plus seulement des correspondances de mots-clés. Cela entraîne une amélioration de 80 % de la vitesse de récupération de l'information, stimulant la productivité et le partage des connaissances.
Création d'un moteur de recherche visuelle pour le e-commerce
Un développeur e-commerce pour un détaillant de mode en ligne souhaite créer une fonctionnalité « acheter le look », permettant aux clients de trouver des produits en téléchargeant une image. Pour ce faire, l'ensemble du catalogue d'images de produits est traité par un modèle de vision pour générer des plongements vectoriels, qui sont ensuite stockés dans une base de données vectorielle. Lorsqu'un utilisateur télécharge une image, celle-ci est également convertie en vecteur. La base de données effectue alors une recherche de similarité à grande vitesse pour trouver et afficher les images de produits avec les vecteurs les plus proches. Cette expérience de recherche intuitive améliore considérablement la découverte de produits et il a été démontré qu'elle augmente les taux de conversion en aidant les clients à trouver instantanément des articles visuellement similaires.
Création de systèmes de recommandation de contenu personnalisés
Un scientifique des données dans un service de streaming multimédia vise à augmenter l'engagement des utilisateurs en fournissant des recommandations de contenu très pertinentes. Ils représentent chaque élément de contenu (par exemple, films, articles) et le profil de chaque utilisateur sous forme de vecteurs de haute dimension. Lorsqu'un utilisateur interagit avec du contenu, son vecteur de profil est mis à jour. Une base de données vectorielle est utilisée pour effectuer des recherches de similarité en temps réel, trouvant les vecteurs de contenu les plus proches du vecteur d'intérêt d'un utilisateur. Cela permet à la plateforme de fournir des recommandations dynamiques et personnalisées qui s'adaptent aux goûts évolutifs de l'utilisateur, ce qui se traduit par des durées de session plus longues et une meilleure rétention des utilisateurs.
Détection d'anomalies dans le trafic réseau de cybersécurité
Un analyste en cybersécurité doit identifier les menaces potentielles au sein de vastes quantités de données de trafic réseau en temps réel. Les données opérationnelles normales, telles que les entrées de journal et les paquets réseau, sont converties en plongements vectoriels pour établir un cluster de référence d'activité « normale » dans l'espace vectoriel. Une base de données vectorielle ingère continuellement de nouvelles données, les convertit en vecteurs et les compare à cette référence. Tout point de données dont le vecteur s'éloigne considérablement du cluster normal est instantanément signalé comme une anomalie. Cette approche permet la détection rapide des menaces zero-day ou des défaillances système qui ne correspondent pas aux signatures connues, offrant une couche critique de sécurité proactive.
Déduplication de grands ensembles de données d'images
Un ingénieur en apprentissage automatique prépare un ensemble de données d'images massif pour entraîner un modèle de vision par ordinateur. Pour garantir la qualité des données et prévenir les biais du modèle, il est crucial de supprimer les images en double ou quasi-doubles. Chaque image de l'ensemble de données est convertie en un plongement vectoriel et indexée dans une base de données vectorielle. L'ingénieur exécute ensuite une recherche de similarité pour chaque image afin de trouver d'autres images dans un seuil de distance très faible. Ce processus identifie et marque efficacement tous les ensembles de quasi-doubles pour suppression, ce qui donne un ensemble de données d'entraînement plus propre et plus diversifié. Cela améliore la précision et les capacités de généralisation du modèle final.