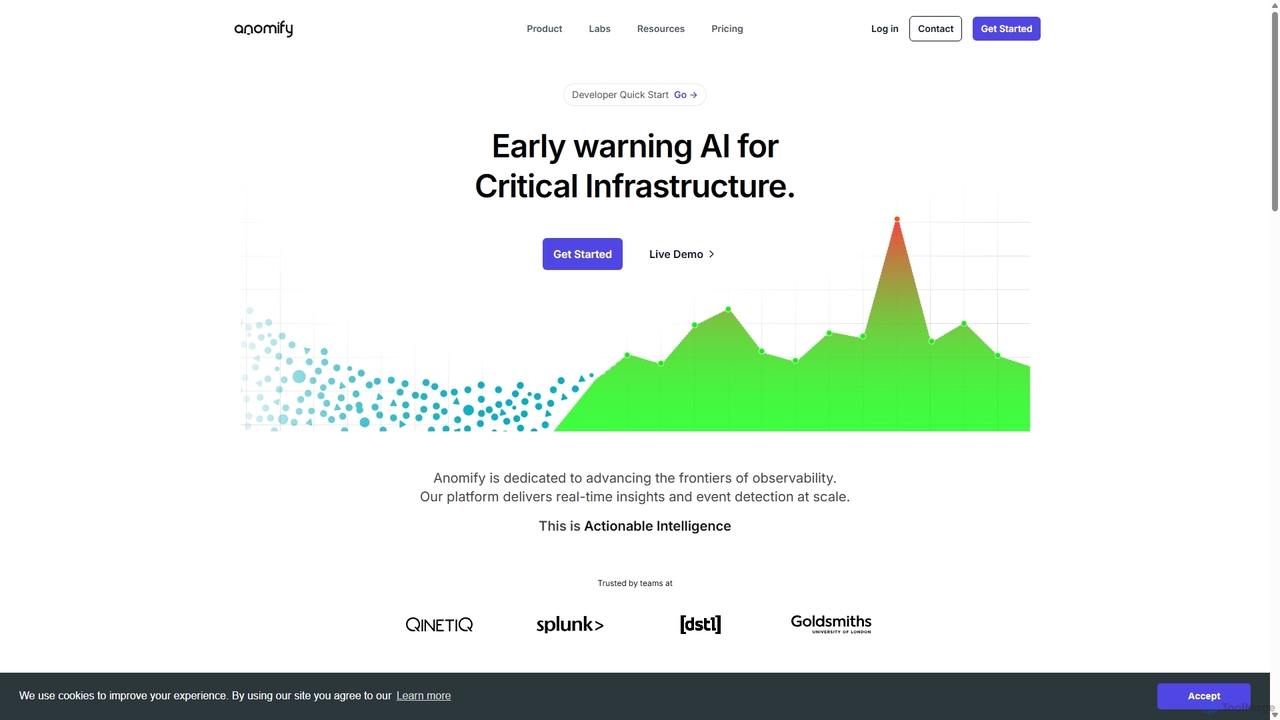
Anomify
Anomify est une plateforme d'alerte précoce alimentée par l'IA pour les infrastructures critiques, offrant une détection d'anomalies en …
Anomify est une plateforme d'alerte précoce alimentée par l'IA pour les infrastructures critiques, offrant une détection d'anomalies en temps réel et une observabilité à grande échelle. Elle exploite l'apprentissage automatique multi-étapes pour analyser les données de séries chronologiques, réduire considérablement les faux positifs et accélérer l'analyse des causes profondes. Conçue pour les équipes DevOps, SRE et informatiques, Anomify transforme la surveillance de réactive à proactive, garantissant la performance et la fiabilité du système.
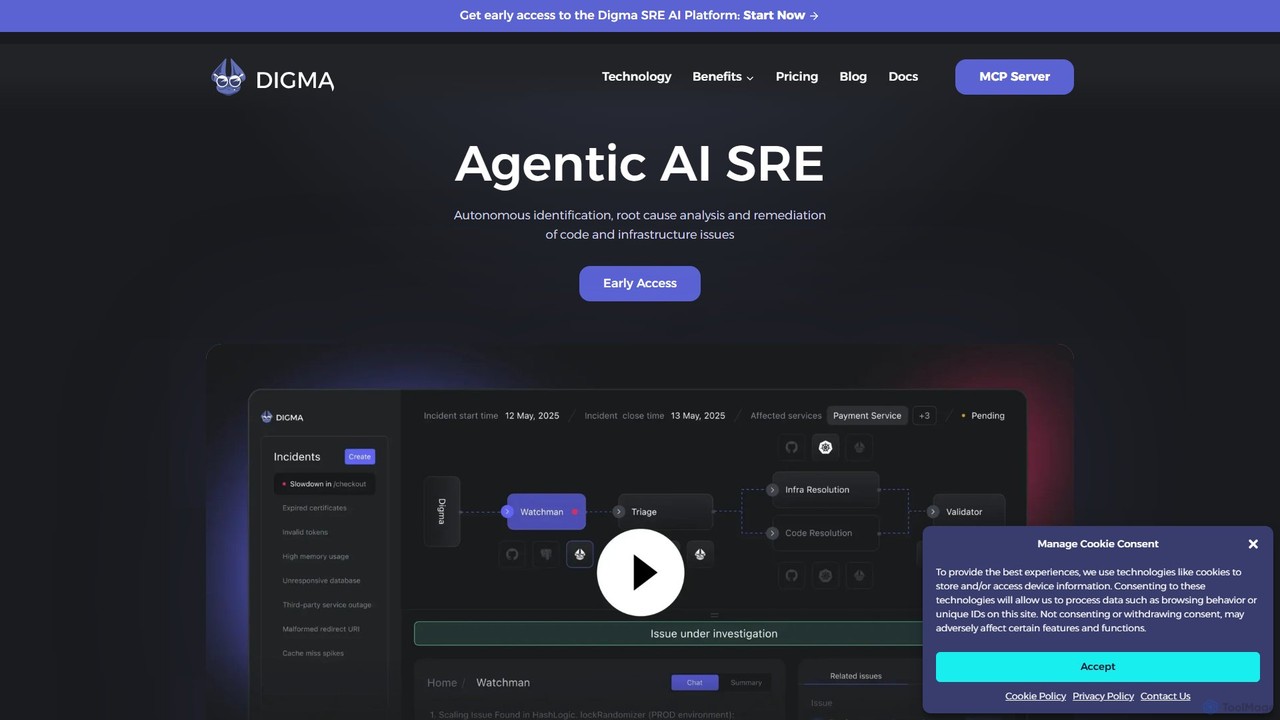
Digma
Digma est une plateforme SRE IA agentique qui utilise l'Analyse de Code Dynamique (DCA) pour identifier, analyser et …
Digma est une plateforme SRE IA agentique qui utilise l'Analyse de Code Dynamique (DCA) pour identifier, analyser et corriger de manière autonome les problèmes de code et d'infrastructure avant qu'ils n'atteignent la production. Elle s'intègre à votre pile d'observabilité pour fournir des informations en temps réel, prévenir les changements cassants et optimiser les performances des applications, réduisant ainsi considérablement le temps de résolution et l'effort d'ingénierie.
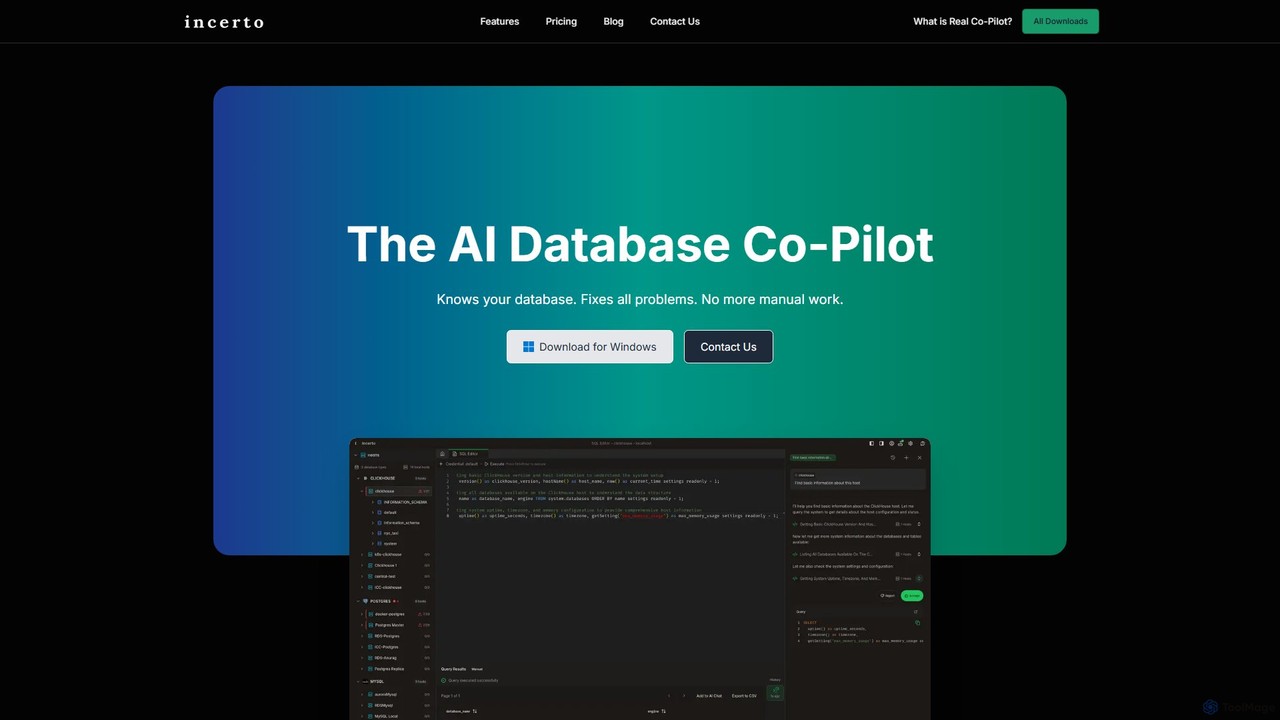
Incerto
Incerto est un copilote IA agentique conçu pour résoudre tous les problèmes de base de données. Il détecte …
Incerto est un copilote IA agentique conçu pour résoudre tous les problèmes de base de données. Il détecte et résout de manière proactive les problèmes de production, optimise les performances des requêtes et automatise les tâches complexes de gestion de base de données. En s'appuyant sur un moteur de contexte riche et des agents IA spécialisés, Incerto réduit considérablement le travail manuel, minimise les temps d'arrêt et améliore l'efficacité et la sécurité globales des bases de données pour les développeurs et les DBA.
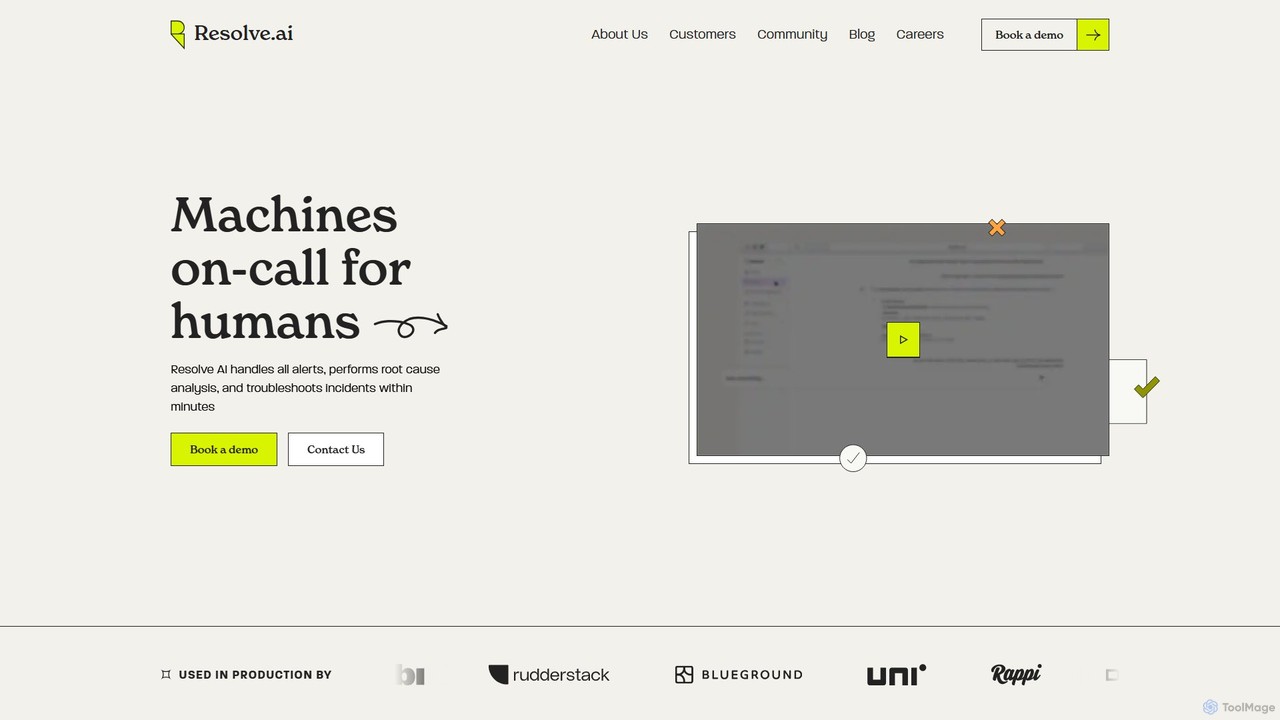
Resolve.ai
Resolve.ai est une plateforme SRE à IA Agentique qui automatise la réponse aux incidents et l'analyse des causes …
Resolve.ai est une plateforme SRE à IA Agentique qui automatise la réponse aux incidents et l'analyse des causes racines. Elle agit comme un membre d'équipe virtuel d'astreinte, enquêtant sur les alertes, testant des hypothèses et identifiant les problèmes en quelques minutes pour réduire le MTTR, diminuer l'épuisement des ingénieurs et augmenter la disponibilité du système.
À propos de Observabilité
Les outils d'observabilité sont des plateformes avancées conçues pour fournir des informations approfondies et interrogeables sur l'état interne des systèmes informatiques complexes. Ils fonctionnent en collectant, corrélant et analysant des données de télémétrie à haute cardinalité, principalement des journaux (logs), des métriques et des traces. Cela permet aux équipes d'ingénierie de dépasser la simple surveillance pour explorer et comprendre activement le comportement du système, rendant possible le débogage de problèmes inédits dans des environnements distribués. Ces outils sont cruciaux pour maintenir la fiabilité et la performance des applications cloud-natives modernes.
Fonctionnalités Clés
- Données de Télémétrie Unifiées : Ingeste et corrèle les trois piliers de l'observabilité : journaux, métriques et traces distribuées sur une seule plateforme.
- Traçage Distribué : Visualise le parcours de bout en bout des requêtes à travers plusieurs microservices et composants.
- Analyse à Haute Cardinalité : Permet d'interroger et de filtrer les données sur la base d'attributs arbitraires, ce qui est essentiel pour déboguer des sessions utilisateur ou des requêtes spécifiques.
- Détection d'Anomalies par IA : Identifie automatiquement les schémas inhabituels ou les écarts par rapport aux performances de base sans règles préconfigurées.
- Cartographie des Dépendances de Services : Génère des cartes en temps réel montrant comment les différents services et composants d'infrastructure interagissent.
Cas d'Usage
Les outils d'observabilité sont principalement utilisés par les ingénieurs DevOps, les ingénieurs en fiabilité de site (SRE) et les développeurs de logiciels travaillant sur des systèmes complexes et distribués. Ils sont essentiels pour le dépannage des incidents de production dans les architectures de microservices, l'optimisation des performances des applications en identifiant les goulots d'étranglement, et la compréhension de l'impact des nouveaux déploiements de code en temps réel. Ces plateformes sont également précieuses pour la gestion de l'infrastructure cloud et l'analyse de la sécurité.
Comment Choisir
Lors de la sélection d'un outil d'observabilité, tenez compte de sa compatibilité avec les sources de données et de l'étendue de ses intégrations. Évaluez la puissance et la convivialité de son langage de requête pour l'exploration des données. Analysez sa capacité à évoluer pour gérer votre volume de données et son modèle de tarification (par exemple, par hôte, par Go ingéré). Enfin, considérez l'efficacité de ses outils de visualisation, de ses tableaux de bord et de ses capacités d'alerte basées sur l'IA pour le flux de travail de votre équipe.
ObservabilitéCas d'utilisation
Déboguer les pannes de microservices en production
Un ingénieur en fiabilité de site (SRE) reçoit une alerte concernant des taux d'erreur élevés dans le service de paiement. En utilisant une plateforme d'observabilité, il accède à la trace distribuée d'une transaction échouée. La trace visualise le chemin de la requête à travers les microservices d'authentification, d'inventaire et de paiement. Il identifie rapidement que le service de paiement expire lors de l'appel à une API tierce. En inspectant les journaux associés à cet ID de trace spécifique, il trouve le message d'erreur exact, ce qui lui permet de résoudre le problème en quelques minutes au lieu de plusieurs heures.
Optimiser de manière proactive les performances des applications
Une équipe DevOps remarque une augmentation progressive des temps de réponse de l'API. Elle utilise un outil d'observabilité pour analyser les métriques de ses serveurs d'applications, bases de données et caches. En créant un tableau de bord qui corrèle l'utilisation du processeur, la latence des requêtes de base de données et les taux de réussite du cache, elle découvre une requête de base de données spécifique qui est devenue inefficace avec la croissance des données. La fonction de traçage distribué confirme que cette requête est le principal goulot d'étranglement. L'équipe optimise la requête et déploie le correctif, réussissant à réduire le temps de réponse moyen de l'API de 40 % avant que cela n'affecte les utilisateurs finaux.
Comprendre l'impact des nouveaux déploiements de code
Un développeur de logiciels déploie une nouvelle fonctionnalité qui refactorise une partie essentielle de l'application. Immédiatement après le déploiement, il utilise une plateforme d'observabilité pour comparer les métriques commerciales clés (comme les inscriptions d'utilisateurs) et les métriques de performance (comme la latence et les taux d'erreur) avant et après le changement. Les tableaux de bord de la plateforme montrent une légère augmentation de la latence mais une baisse significative de l'utilisation de la mémoire. Cette approche basée sur les données permet à l'équipe de valider que la refactorisation a été un succès et a eu l'impact positif escompté sur la consommation des ressources sans affecter négativement l'expérience utilisateur.
Surveiller l'utilisation et les coûts des ressources cloud
Un ingénieur cloud est chargé d'optimiser les coûts d'infrastructure. Il utilise un outil d'observabilité pour collecter des métriques détaillées de son cluster Kubernetes, y compris l'utilisation CPU/mémoire par pod, le trafic réseau et les demandes de volumes persistants. En visualisant ces données, il identifie plusieurs services sur-provisionnés qui utilisent constamment moins de 20 % de leurs ressources allouées. Il repère également une fuite de mémoire dans un conteneur d'application spécifique. Sur la base de ces informations, il ajuste les demandes et les limites de ressources pour les services et corrige la fuite, ce qui entraîne une réduction de 25 % de sa facture cloud mensuelle.
Corréler la santé du système avec les KPI métier
Un chef de produit pour un site de commerce électronique veut comprendre pourquoi les taux d'abandon de panier sont élevés. En utilisant un outil d'observabilité qui s'intègre à l'analyse métier, il crée un tableau de bord superposant les métriques techniques (temps de chargement des pages, erreurs d'API) avec les métriques métier (articles ajoutés au panier, finalisations de paiement). Il découvre une forte corrélation : chaque fois que la latence de l'API de 'traitement des paiements' dépasse 2 secondes, le taux d'abandon de panier grimpe de 50 %. Ce lien direct entre la performance technique et les résultats commerciaux fournit une justification claire pour prioriser les ressources d'ingénierie afin d'optimiser l'API de paiement.
Améliorer la sécurité avec la détection d'anomalies
Une équipe des opérations de sécurité (SecOps) utilise une plateforme d'observabilité pour ingérer les journaux d'authentification de tous les services. Elle configure un moniteur alimenté par l'IA pour détecter les anomalies dans les schémas de connexion. Le système signale automatiquement une augmentation soudaine des tentatives de connexion échouées provenant d'une plage d'adresses IP jamais vue auparavant, suivie d'une connexion réussie. Cela déclenche une alerte immédiate. L'analyste de sécurité enquête sur les traces et les journaux associés, confirme qu'il s'agit d'une attaque par bourrage de mots de passe (credential stuffing), et bloque rapidement la plage d'adresses IP malveillante et force une réinitialisation du mot de passe pour le compte compromis, empêchant ainsi une violation plus importante.