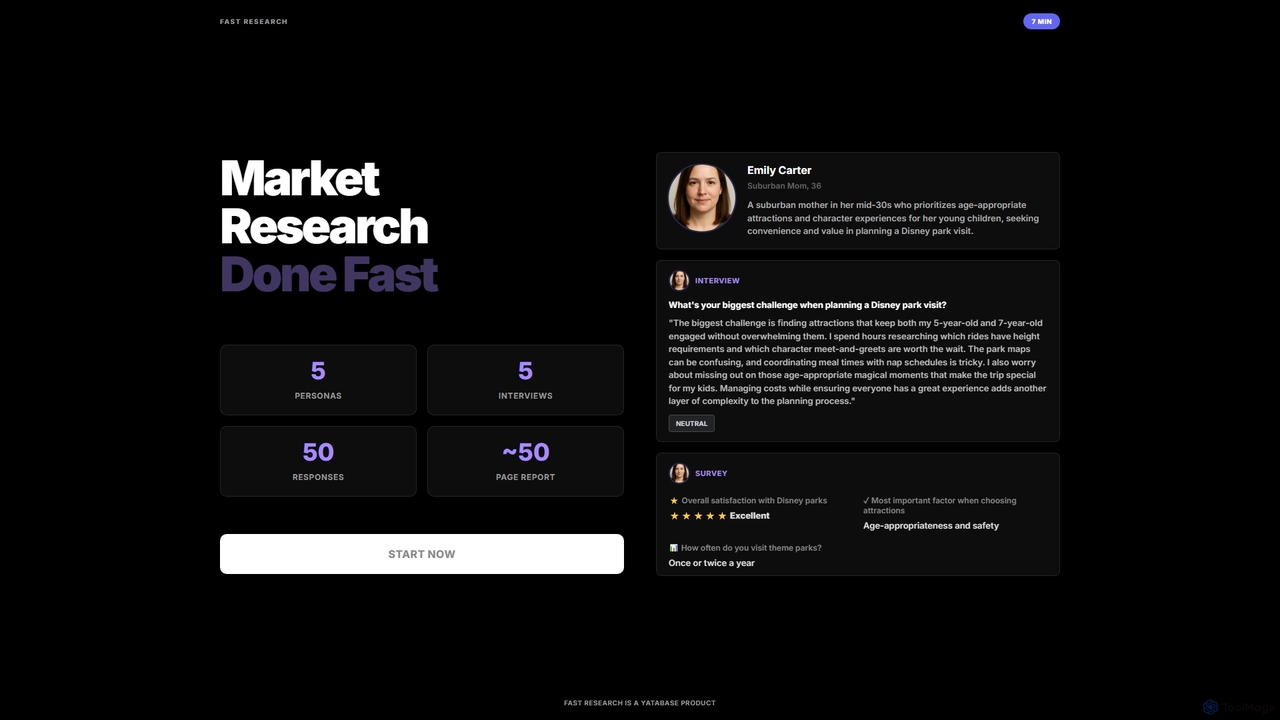
Fast Research
Fast Research est un outil d'étude de marché alimenté par l'IA qui génère rapidement des données synthétiques, y …
Fast Research est un outil d'étude de marché alimenté par l'IA qui génère rapidement des données synthétiques, y compris des personas détaillés, des entretiens simulés et des réponses à des enquêtes. Il fournit des rapports complets, permettant aux entreprises d'obtenir des informations rapides et exploitables pour la prise de décision stratégique sans les complexités de la collecte de données traditionnelle.
À propos de Données synthétiques
Les Données Synthétiques désignent des ensembles de données générés artificiellement qui imitent les propriétés statistiques et les modèles des données du monde réel sans contenir d'informations personnelles ou sensibles réelles. Ces outils basés sur l'IA exploitent des algorithmes avancés pour créer des données réalistes, répondant à des défis critiques tels que la confidentialité des données, la rareté et les biais. Ils offrent une alternative sécurisée et flexible pour diverses fins analytiques et de développement, en particulier dans la recherche marketing.
Fonctionnalités Clés
- Préservation de la Confidentialité: Génère des données qui maintiennent l'intégrité statistique tout en garantissant qu'aucune donnée individuelle réelle n'est exposée.
- Augmentation des Données: Crée des points de données supplémentaires pour étendre les ensembles de données existants, améliorant l'entraînement et la robustesse des modèles.
- Atténuation des Biais: Permet la génération d'ensembles de données équilibrés pour réduire les biais inhérents trouvés dans les données du monde réel.
- Simulation Réaliste: Produit des données qui reflètent avec précision les distributions, les corrélations et les structures des données originales.
- Évolutivité: Permet la génération de grands volumes de données à la demande, surmontant les limitations de la collecte de données réelles.
Cas d'Utilisation
Les entreprises utilisent les données synthétiques pour tester de nouvelles fonctionnalités de produits, simuler des scénarios de marché ou entraîner des modèles d'IA sans compromettre la confidentialité des clients. Les chercheurs peuvent analyser les tendances et les modèles dans des domaines sensibles comme la santé ou la finance, garantissant une gestion éthique des données.
Comment Choisir
Lors de la sélection d'un outil de données synthétiques, tenez compte de la fidélité requise (à quel point il imite les données réelles), des types de données qu'il peut générer (tabulaires, images, texte), de ses garanties de confidentialité et de ses capacités d'intégration avec les pipelines de données existants. Évaluez la facilité d'utilisation et le niveau de contrôle offert sur les caractéristiques des données.
Données synthétiquesCas d'utilisation
Développement de Modèles d'IA Préservant la Confidentialité
Les scientifiques des données utilisent des données synthétiques pour entraîner des modèles d'apprentissage automatique pour des applications sensibles (par exemple, diagnostics de santé, détection de fraude financière) sans accéder ni exposer les informations réelles des patients ou des clients. Cela garantit la conformité avec des réglementations strictes en matière de confidentialité comme le RGPD et l'HIPAA, permettant un développement robuste de modèles dans des industries hautement réglementées.
Simulation du Comportement du Marché pour les Tests de Produits
Les chercheurs en marketing génèrent des ensembles de données clients synthétiques pour simuler diverses conditions de marché et les réponses des consommateurs aux lancements de nouveaux produits ou aux campagnes marketing. Cela permet des tests A/B sans risque, la planification de scénarios et la prévision de la demande avant le déploiement réel, ce qui réduit les coûts et atténue les impacts négatifs potentiels.
Surmonter la Rareté des Données sur les Marchés de Niche
Les startups ou les entreprises des industries de niche manquent souvent de données réelles suffisantes pour des analyses robustes ou l'entraînement de modèles d'IA. Les outils de données synthétiques aident à créer des ensembles de données étendus et représentatifs pour combler ces lacunes, permettant une analyse complète, le développement de produits et l'intelligence concurrentielle, même avec des sources de données originales limitées.
Amélioration des Tests et du Développement Logiciel
Les développeurs de logiciels utilisent des données synthétiques pour peupler les environnements de test, garantissant que les applications peuvent gérer diverses entrées de données et cas limites sans dépendre de données de production sensibles. Cela accélère les cycles de test, améliore la qualité des logiciels et permet une validation plus approfondie des nouvelles fonctionnalités et mises à jour dans un cadre contrôlé et sécurisé.
Atténuation des Biais dans les Ensembles de Données d'Entraînement d'IA
Les chercheurs et développeurs en éthique de l'IA utilisent la génération de données synthétiques pour créer des ensembles de données équilibrés qui corrigent les biais présents dans les données du monde réel (par exemple, la sous-représentation de certaines données démographiques). Cela conduit à des systèmes d'IA plus justes et équitables, réduisant les résultats discriminatoires et améliorant la fiabilité globale des applications d'IA.
Faciliter le Partage et la Collaboration de Données
Les organisations peuvent partager des versions synthétiques de leurs ensembles de données propriétaires ou sensibles avec des partenaires externes, des chercheurs ou des organismes de réglementation. Cela permet l'innovation et la recherche collaboratives tout en respectant strictement les accords de gouvernance des données et de confidentialité, favorisant un environnement sécurisé pour les informations basées sur les données à travers les écosystèmes.