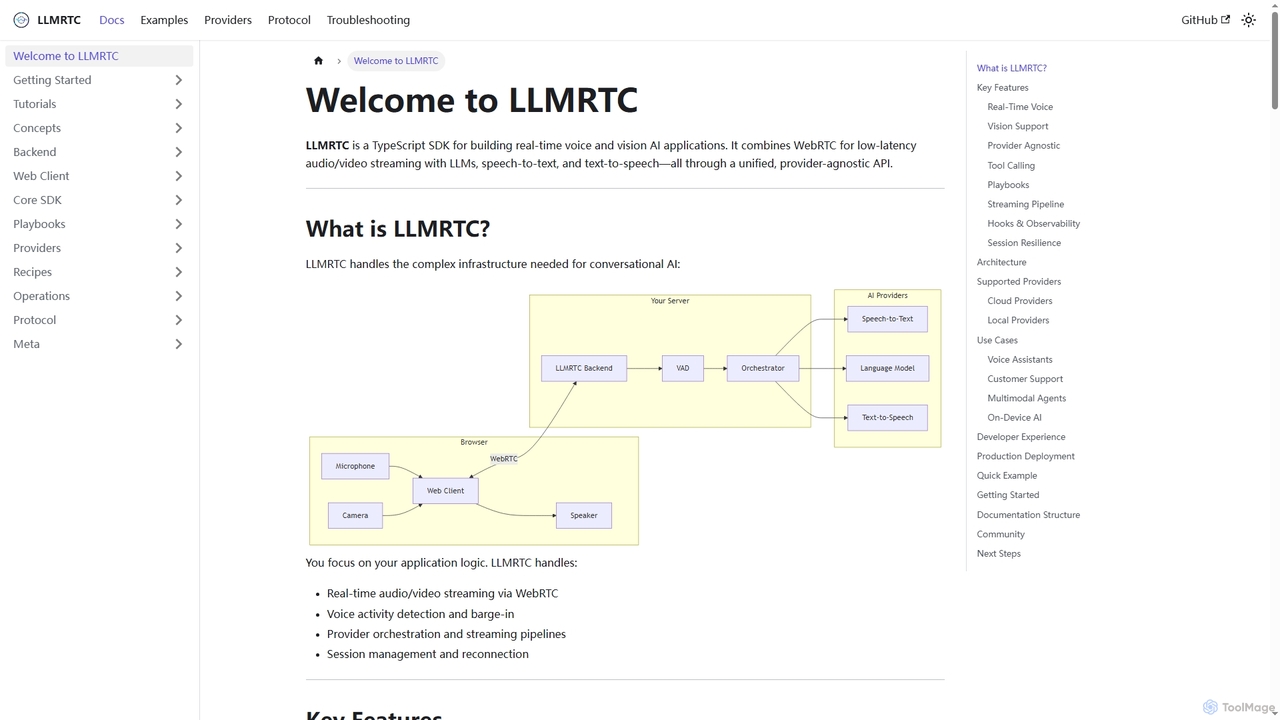
LLMRTC
LLMRTC est un SDK TypeScript pour la création d'applications d'IA vocales et visuelles en temps réel. Il intègre …
LLMRTC est un SDK TypeScript pour la création d'applications d'IA vocales et visuelles en temps réel. Il intègre WebRTC pour le streaming audio/vidéo à faible latence avec les LLM, la reconnaissance vocale et la synthèse vocale, le tout via une API unifiée et agnostique aux fournisseurs. Les développeurs peuvent se concentrer sur la logique applicative tandis que LLMRTC gère l'infrastructure complexe de l'IA conversationnelle.
Noiz
Noiz est une plateforme vocale IA avancée pour la synthèse vocale, le clonage de voix et le doublage …
Noiz est une plateforme vocale IA avancée pour la synthèse vocale, le clonage de voix et le doublage vidéo instantané. Créez des voix réalistes, clonez n'importe quelle voix à partir d'un clip audio de 3 à 10 secondes et traduisez votre contenu en plusieurs langues tout en préservant les caractéristiques vocales originales. Idéal pour les créateurs de contenu, les spécialistes du marketing et les développeurs.
voiceisolator
Un outil en ligne alimenté par l'IA, conçu pour l'isolation vocale de haute qualité, la suppression du bruit …
Un outil en ligne alimenté par l'IA, conçu pour l'isolation vocale de haute qualité, la suppression du bruit de fond et la séparation des pistes (stems) à partir de fichiers audio/vidéo. Il dispose également d'un générateur polyvalent de synthèse vocale (TTS) pour créer des voix off au son naturel. Idéal pour les musiciens, les créateurs de contenu et les monteurs vidéo.
CAMB.AI
CAMB.AI est une plateforme pionnière de localisation par IA pour les industries du contenu, du divertissement et du …
CAMB.AI est une plateforme pionnière de localisation par IA pour les industries du contenu, du divertissement et du sport. Elle offre un doublage et une traduction en temps réel préservant les émotions dans plus de 150 langues. Approuvée par des partenaires majeurs comme IMAX et MLS, elle permet aux créateurs de rendre leur contenu accessible dans le monde entier tout en conservant le ton et l'authenticité d'origine.
Altered
Altered est une plateforme professionnelle de technologie vocale par IA offrant à la fois le changement de voix …
Altered est une plateforme professionnelle de technologie vocale par IA offrant à la fois le changement de voix en temps réel et l'édition vocale en post-production. Grâce à sa technologie unique de morphing de la parole à la parole (Speech-To-Speech), les utilisateurs peuvent changer leur voix pour un portefeuille sélectionné, cloner n'importe quelle voix, modifier les accents ou restaurer la clarté vocale. Elle s'adresse aux créateurs de contenu, aux joueurs, aux centres d'appels et aux particuliers cherchant à modifier ou protéger leur voix.

neoformai
neoformai fournit des modèles d'IA avancés pour les dialectes africains, y compris la reconnaissance automatique de la parole …
neoformai fournit des modèles d'IA avancés pour les dialectes africains, y compris la reconnaissance automatique de la parole (ASR) et la synthèse vocale (TTS). Il permet aux développeurs et aux entreprises de créer des applications inclusives, de surmonter les barrières linguistiques et de rendre les expériences numériques accessibles à des millions de personnes à travers l'Afrique.
AudioPod
AudioPod est un studio audio professionnel alimenté par l'IA qui offre une suite complète d'outils pour les créateurs. …
AudioPod est un studio audio professionnel alimenté par l'IA qui offre une suite complète d'outils pour les créateurs. Il propose un clonage de voix avancé, une traduction parole-parole multilingue (doublage IA), une séparation des locuteurs de haute précision, une séparation des pistes musicales (stems), une réduction du bruit et une transcription automatisée. Il est conçu pour rationaliser les flux de production audio et vidéo pour les podcasteurs, les créateurs de contenu, les musiciens et les entreprises, rendant le traitement audio de qualité professionnelle accessible et efficace.
À propos de Synthèse vocale
Les outils de Synthèse vocale (Text To Speech, TTS) sont une catégorie de logiciels d'IA qui convertissent le texte écrit en audio parlé au son naturel. S'appuyant sur des modèles d'apprentissage profond, ces outils synthétisent des voix semblables à celles des humains, permettant un contrôle précis de la hauteur, du ton et de la vitesse. Ils sont essentiels pour rendre le contenu numérique accessible, créer des versions audio d'articles et fournir des voix off pour les vidéos et les podcasts. La technologie TTS moderne offre une large gamme de voix réalistes, de multiples langues et une expressivité émotionnelle, dépassant de loin les résultats robotiques.
Fonctionnalités Clés
- Voix et Langues Multiples : Accédez à une bibliothèque diversifiée de voix masculines, féminines et d'enfants dans de nombreuses langues et accents.
- Personnalisation de la Voix : Ajustez les paramètres de la parole comme la vitesse, la hauteur, le volume et ajoutez des pauses pour une élocution naturelle.
- Support SSML : Utilisez le langage de balisage de synthèse vocale (SSML) pour un contrôle fin de la prononciation, de l'accentuation et de l'intonation.
- Formats d'Exportation Audio : Téléchargez l'audio généré dans des formats courants comme MP3 et WAV pour diverses applications.
- Accès API : Intégrez les capacités TTS directement dans les applications et les sites web pour une génération audio en temps réel.
Cas d'Utilisation
Ces outils sont largement utilisés par les créateurs de contenu pour les voix off de vidéos, les auteurs pour la production de livres audio et les développeurs pour l'intégration de fonctions vocales dans les applications. Ils sont également essentiels dans la formation en entreprise pour les modules d'e-learning et dans le service client pour les systèmes SVI dynamiques.
Comment Choisir
Lors de la sélection d'un outil de Synthèse vocale, évaluez d'abord la qualité et le réalisme de la voix. Considérez la gamme de langues et d'accents disponibles. Évaluez le niveau de personnalisation et de contrôle, tel que le support SSML. Enfin, examinez le modèle de tarification et vérifiez la disponibilité de l'API si vous devez intégrer le service dans vos propres produits.
Synthèse vocaleCas d'utilisation
Création de voix off pour le contenu vidéo
Un créateur de contenu ou un spécialiste du marketing vidéo a besoin d'une voix off cohérente et professionnelle pour une série de vidéos explicatives sans le coût élevé d'un acteur vocal. Il peut coller son script dans un outil de synthèse vocale, sélectionner une voix et une langue appropriées, et affiner la diction en ajustant la vitesse et en ajoutant des pauses. L'audio final est exporté en tant que fichier MP3 et synchronisé avec les séquences vidéo. Ce processus réduit considérablement le temps et le budget de production, permettant une création de contenu plus rapide et des mises à jour faciles de la narration chaque fois que le script change.
Développement de modules d'e-learning et de formation
Un concepteur pédagogique crée un cours en ligne pour une main-d'œuvre mondiale. Pour rendre le contenu plus engageant et accessible, il utilise un outil de synthèse vocale pour narrer le texte à l'écran. En utilisant une API, la narration peut être générée dynamiquement, garantissant que toute mise à jour du matériel de cours est instantanément reflétée dans l'audio. Cette approche répond à différents styles d'apprentissage, aide les employés ayant des difficultés de lecture et facilite la production du cours en plusieurs langues en sélectionnant simplement différentes voix, améliorant ainsi l'expérience d'apprentissage globale.
Production de livres audio et de podcasts
Un auteur indépendant souhaite convertir son e-book en livre audio pour toucher un public plus large, mais n'a pas le budget pour un studio d'enregistrement professionnel. En utilisant un générateur de synthèse vocale, il peut télécharger l'intégralité de son manuscrit, choisir une voix de narrateur qui correspond au ton du livre et générer des fichiers audio de haute qualité pour chaque chapitre. Cela lui permet de publier sur des plateformes comme Audible ou Spotify pour une fraction du coût traditionnel. De même, un podcasteur peut utiliser le TTS pour créer des intros, des outros cohérents ou même des segments vocaux pour différents personnages dans une émission narrative.
Amélioration de l'accessibilité des sites web et des articles
Un éditeur numérique ou une organisation de presse souhaite rendre ses articles en ligne accessibles aux utilisateurs ayant une déficience visuelle ou des difficultés de lecture, conformément aux normes WCAG. Ils peuvent intégrer un widget de synthèse vocale sur leur site web. Cela permet aux visiteurs de cliquer sur un bouton « Écouter », qui convertit instantanément le texte de l'article en audio de haute qualité. Cela améliore non seulement l'accessibilité et l'expérience utilisateur, mais répond également aux besoins des utilisateurs qui préfèrent consommer du contenu de manière audible, comme pendant leurs déplacements ou en multitâche. Cela élargit la portée du site web et démontre un engagement en faveur de l'inclusivité.
Prototypage d'interfaces utilisateur vocales (VUI)
Un concepteur UX ou un développeur d'applications construit une application à commande vocale, telle qu'un assistant intelligent ou un système de navigation embarqué. Au lieu d'enregistrer de l'audio de remplacement, il utilise un outil de synthèse vocale pour générer rapidement des réponses vocales pour son prototype. Cela lui permet de tester différentes phrases, tonalités et temps de réponse dans un environnement de test utilisateur réaliste. La capacité de changer instantanément le texte et de régénérer l'audio rend le processus d'itération de la conception rapide et rentable, conduisant à une interface vocale finale plus soignée et conviviale.
Automatisation du service client avec les systèmes SVI
Un responsable de centre d'appels doit mettre à jour le système de Réponse Vocale Interactive (SVI) de son entreprise avec de nouvelles options de menu et des messages promotionnels. Au lieu d'engager un acteur vocal pour chaque petit changement, il utilise un service de synthèse vocale. Il lui suffit de taper les nouvelles invites, telles que « Nos heures d'ouverture ont changé », et de générer un fichier audio clair et professionnel. Cela garantit que le système téléphonique de l'entreprise dispose toujours d'informations à jour et maintient une voix de marque cohérente, tout en économisant un temps et des ressources considérables par rapport aux sessions d'enregistrement manuel.