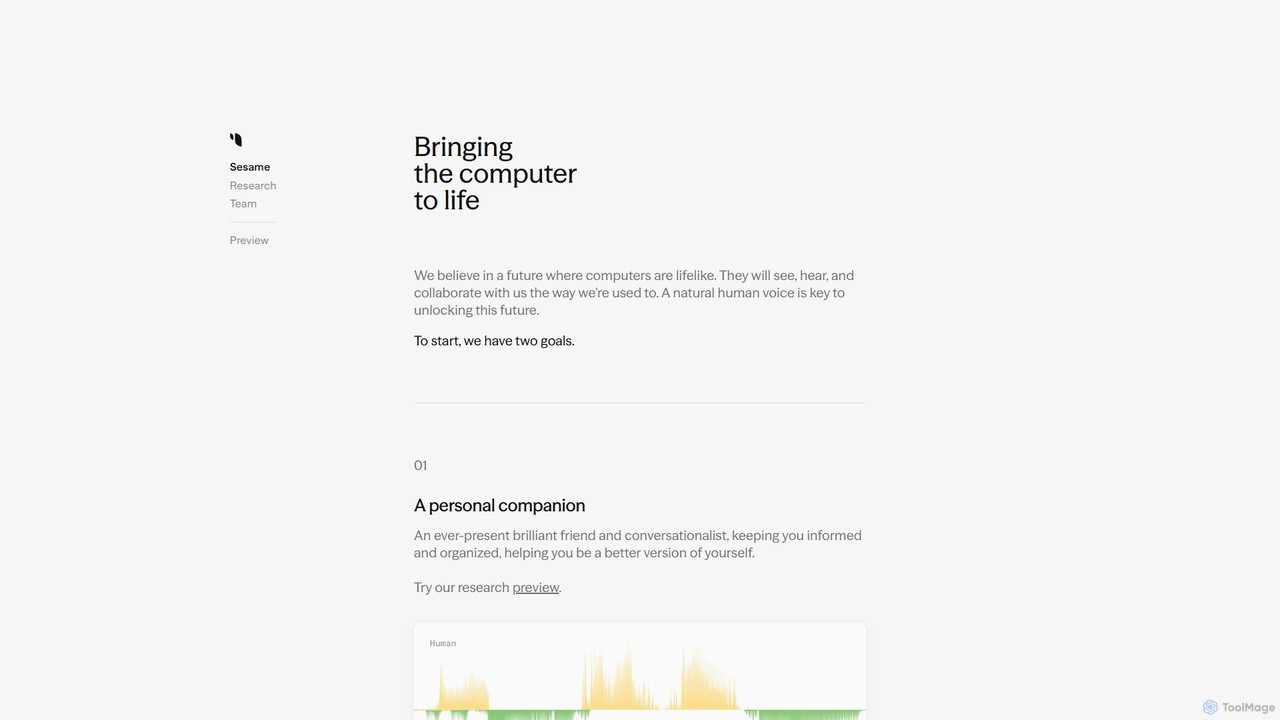
Sesame
Sesame développe un compagnon personnel IA réaliste, conçu pour interagir par le biais de conversations naturelles et émotionnellement …
Sesame développe un compagnon personnel IA réaliste, conçu pour interagir par le biais de conversations naturelles et émotionnellement intelligentes. En se concentrant sur la "présence vocale", il vise à franchir la vallée de l'étrange de la voix numérique. La plateforme combine son modèle de parole conversationnelle (CSM) avancé avec une vision de lunettes légères, créant un partenaire collaboratif omniprésent.
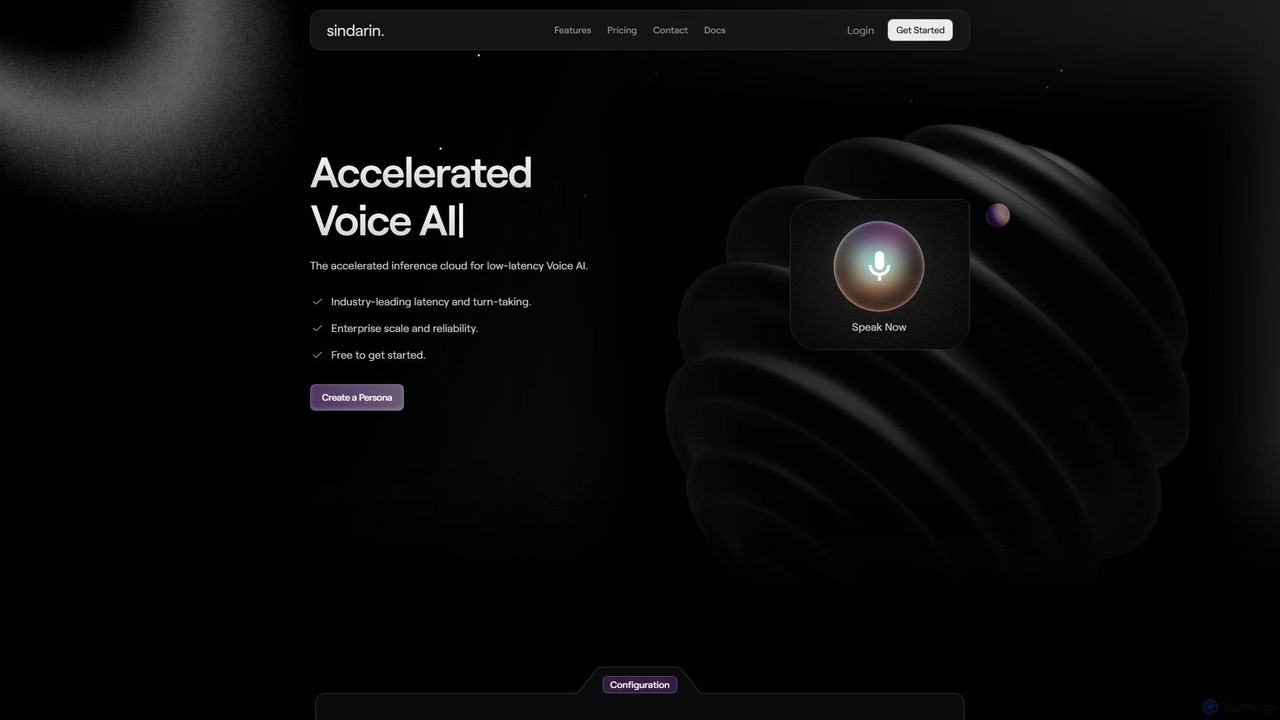
Sindarin
Sindarin est une plateforme cloud accélérée pour les développeurs qui créent des IA vocales conversationnelles à faible latence. …
Sindarin est une plateforme cloud accélérée pour les développeurs qui créent des IA vocales conversationnelles à faible latence. Elle fournit une API et une plateforme sans code pour créer des personas d'IA très réactifs et au son naturel. Avec une prise de parole de pointe et une gestion transparente des interruptions, Sindarin permet de créer des expériences vocales véritablement interactives pour des applications dans le service client, le bien-être, les jeux, et plus encore, offrant une échelle et une fiabilité de niveau entreprise.
À propos de Synthèse Vocale
Les outils de Synthèse Vocale, souvent appelés logiciels de Texte-à-Parole (TTS), sont une catégorie d'applications d'IA qui convertissent le texte écrit en parole audible et quasi humaine. Ces outils utilisent des modèles avancés d'apprentissage profond pour générer un audio réaliste, avec une intonation, un rythme et des nuances émotionnelles naturels. Leur principale valeur réside dans l'automatisation de la création de contenu vocal de haute qualité pour les vidéos, les podcasts et les fonctionnalités d'accessibilité, éliminant le besoin d'enregistrement manuel. Les plateformes avancées offrent également des capacités puissantes comme le clonage de voix et la création de voix personnalisées uniques pour l'identité de marque.
Fonctionnalités Clés
- Génération de Voix Haute Fidélité : Produit une parole claire et naturelle, difficile à distinguer d'une voix humaine.
- Clonage et Personnalisation de Voix : Permet aux utilisateurs de créer une réplique numérique d'une voix spécifique ou de concevoir une nouvelle voix unique.
- Contrôle Émotionnel et Stylistique : Fournit des options pour ajuster le ton émotionnel (par ex., joyeux, triste, en colère) et le style de parole (par ex., présentateur de journal, conversationnel).
- Support Multilingue et d'Accents : Offre une large gamme de voix dans de nombreuses langues et accents régionaux pour un contenu mondial.
- Support SSML : Permet un contrôle fin sur la prononciation, la hauteur, le débit et les pauses en utilisant le Langage de Balisage de Synthèse Vocale.
Cas d'Utilisation
Les outils de Synthèse Vocale sont largement adoptés par les créateurs de contenu pour produire des voix off pour les vidéos YouTube et des narrations de podcasts. En entreprise, ils sont utilisés pour créer des modules d'e-learning et des systèmes SVI (Serveur Vocal Interactif) professionnels. Les développeurs intègrent également cette technologie via des API pour créer des applications à commande vocale et améliorer l'accessibilité numérique pour les utilisateurs malvoyants.
Comment Choisir
Lors de la sélection d'un outil de Synthèse Vocale, évaluez d'abord la qualité et le naturel de la voix produite. Considérez la gamme d'options de personnalisation, telles que le clonage de voix, les contrôles émotionnels et le support linguistique. Pour les développeurs, la disponibilité et la documentation d'une API sont essentielles. Enfin, comparez les modèles de tarification, qui peuvent être basés sur le nombre de caractères, des niveaux d'abonnement ou l'utilisation de l'API, pour trouver celui qui correspond à l'échelle de votre projet.
Synthèse VocaleCas d'utilisation
Création de Voix Off Professionnelles pour Vidéos
Les créateurs de contenu et les équipes marketing ont souvent besoin de voix off de haute qualité pour des vidéos promotionnelles, des tutoriels ou du contenu pour les réseaux sociaux. Au lieu d'engager des comédiens de doublage et de réserver du temps en studio, ils utilisent un outil de Synthèse Vocale. En collant simplement leur script dans l'application, ils peuvent sélectionner une voix appropriée, ajuster le ton et le rythme, et générer un fichier audio propre en quelques minutes. Ce processus permet une itération rapide et des mises à jour faciles du script, réduisant considérablement le temps et les coûts de production tout en maintenant une voix de marque cohérente sur tous les supports vidéo.
Génération de Livres Audio et de Contenu de Podcast
Les auteurs et les éditeurs peuvent transformer des livres écrits en livres audio complets sans le coût élevé d'une narration professionnelle. En important des chapitres d'un manuscrit dans une plateforme de Synthèse Vocale, ils peuvent produire des heures d'audio cohérent. De même, les blogueurs et les podcasteurs peuvent convertir leurs articles en épisodes audio, élargissant leur audience à ceux qui préfèrent écouter plutôt que lire. Les outils avancés permettent d'utiliser des voix différentes pour différents personnages et de contrôler le rythme pour créer une expérience d'écoute captivante, rendant le contenu plus accessible et polyvalent.
Développement d'Applications Accessibles
Les développeurs de logiciels et les concepteurs UX utilisent les API de Synthèse Vocale pour intégrer des fonctionnalités d'accessibilité dans leurs produits. Par exemple, une application d'actualités peut intégrer un bouton « Écouter l'article » qui lit le texte à haute voix pour les utilisateurs malvoyants ou pour ceux qui effectuent plusieurs tâches. Dans les applications éducatives, le TTS peut fournir des conseils de prononciation aux apprenants de langues. En exploitant une API de synthèse, les développeurs peuvent s'assurer que leurs applications sont inclusives et conformes aux normes d'accessibilité comme le WCAG, offrant une meilleure expérience à tous les utilisateurs sans avoir à construire la technologie vocale complexe à partir de zéro.
Création de Voix de Marque Personnalisées
Les entreprises visant une identité de marque unique peuvent utiliser les fonctionnalités de clonage de voix pour créer une voix de marque exclusive. Une entreprise peut engager un comédien de doublage pour une seule session d'enregistrement, puis utiliser un outil de Synthèse Vocale pour cloner cette voix. Cette voix numérique peut ensuite être utilisée de manière cohérente sur tous les points de contact, y compris les publicités, les systèmes SVI et les assistants intégrés à l'application. Cette approche est plus rentable que d'engager l'acteur à plusieurs reprises et garantit une identité de marque audio parfaitement cohérente et reconnaissable qui peut être déployée instantanément pour tout nouveau contenu.
Automatisation de la Narration pour l'E-Learning d'Entreprise
Les concepteurs pédagogiques dans les grandes organisations sont chargés de créer et de mettre à jour de nombreux modules de formation. Enregistrer manuellement l'audio pour chaque module prend du temps et il est difficile de maintenir la cohérence, surtout lorsque des mises à jour sont nécessaires. En utilisant un outil de Synthèse Vocale, ils peuvent générer une narration standardisée et claire pour tous les cours. Si une politique ou une procédure change, il leur suffit de mettre à jour le texte et de régénérer l'audio, garantissant que tous les supports de formation sont à jour et uniformes. Cela rationalise l'ensemble du cycle de vie du développement de l'e-learning et rend la localisation dans différentes langues beaucoup plus efficace.
Prototypage d'Interfaces Utilisateur Vocales (VUI)
Les concepteurs et développeurs qui créent des applications à commande vocale, telles que des skills pour enceintes intelligentes ou des assistants embarqués, doivent tester les flux de conversation. Au lieu d'implémenter un code complexe pour chaque itération, ils utilisent un outil de Synthèse Vocale pour convertir rapidement les scripts en audio. Cela permet à l'équipe d'entendre le son du dialogue en temps réel, d'identifier les formulations maladroites et de tester l'expérience utilisateur avec une sortie vocale réaliste. Cette méthode de prototypage rapide accélère le processus de conception, améliore la qualité de la VUI finale et permet une itération plus centrée sur l'utilisateur avant de s'engager dans le développement.