Oneinfer
Oneinfer est une plateforme d'inférence IA haute performance pour les développeurs. Elle offre une API unifiée pour accéder …
Oneinfer est une plateforme d'inférence IA haute performance pour les développeurs. Elle offre une API unifiée pour accéder à plus de 15 LLM comme GPT-4 et Claude, simplifiant l'intégration de l'IA. La plateforme propose un déploiement sans serveur, une mise à l'échelle automatique, une sécurité de niveau entreprise et une tarification à l'usage. Elle fournit également une place de marché pour la location d'instances GPU pour des charges de travail IA personnalisées.

Dank
Dank est un framework open-source, natif JavaScript, pour l'orchestration et le déploiement d'agents IA conteneurisés. Il permet aux …
Dank est un framework open-source, natif JavaScript, pour l'orchestration et le déploiement d'agents IA conteneurisés. Il permet aux développeurs de construire, gérer et scaler plusieurs agents IA comme des microservices sur n'importe quelle infrastructure cloud, simplifiant les déploiements IA complexes grâce à une architecture native Docker et un monitoring en temps réel.
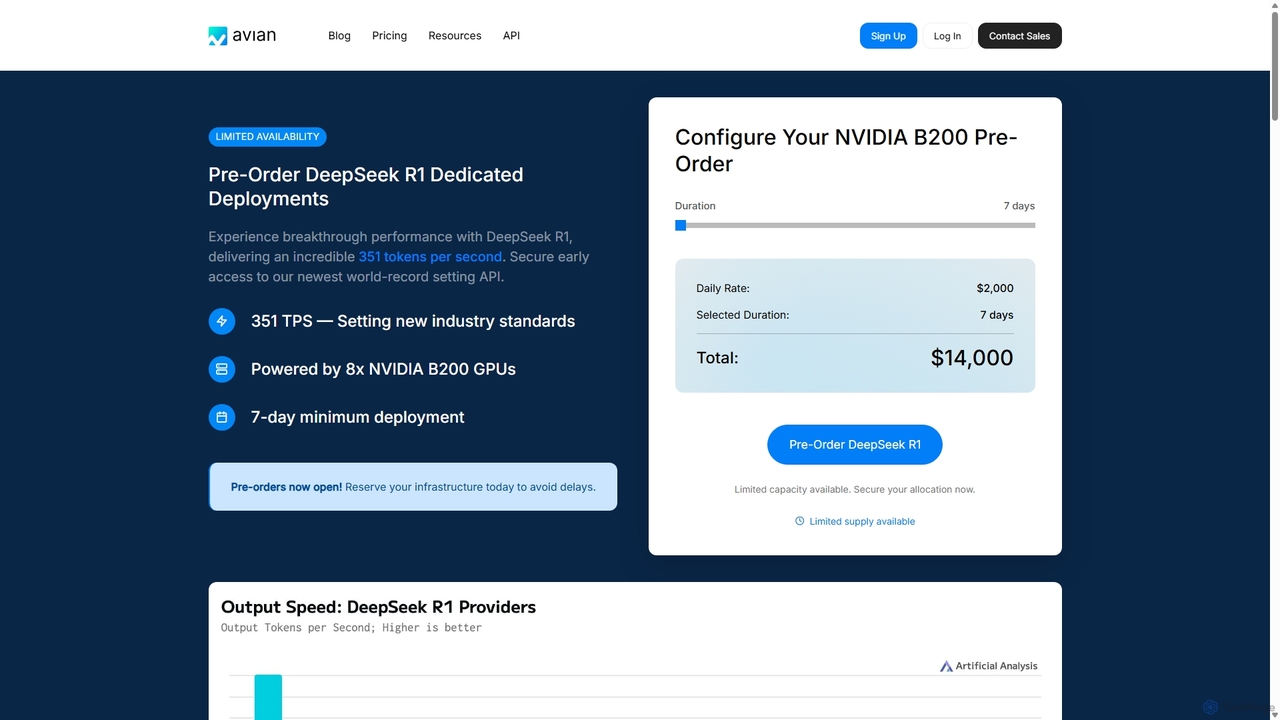
Avian
Avian est une plateforme d'inférence IA haute performance offrant des vitesses record pour les grands modèles de langage …
Avian est une plateforme d'inférence IA haute performance offrant des vitesses record pour les grands modèles de langage (LLM). Elle fournit à la fois une API sans serveur pour les modèles populaires et des déploiements GPU dédiés pour les modèles personnalisés de HuggingFace. Conçue pour la scalabilité et les charges de travail de production, Avian offre des vitesses d'inférence 3 à 10 fois plus rapides que la moyenne de l'industrie, avec une sécurité de niveau entreprise et des prix compétitifs.
Zetic.ai
Zetic.ai est une plateforme permettant aux développeurs de déployer des modèles d'IA directement sur des appareils périphériques (edge …
Zetic.ai est une plateforme permettant aux développeurs de déployer des modèles d'IA directement sur des appareils périphériques (edge devices), éliminant le besoin de serveurs GPU coûteux. Son pipeline automatisé, ZETIC.MLange, optimise et convertit les modèles pour une exécution sur l'appareil, atteignant des performances jusqu'à 60 fois plus rapides grâce à l'accélération NPU, tout en garantissant la confidentialité des données et en réduisant la latence.
SiliconFlow
SiliconFlow est une plateforme d'infrastructure IA unifiée conçue pour l'inférence haute performance de grands modèles de langage (LLM) …
SiliconFlow est une plateforme d'infrastructure IA unifiée conçue pour l'inférence haute performance de grands modèles de langage (LLM) et de modèles multimodaux. Elle offre aux développeurs et aux entreprises des options de déploiement évolutives, rentables et flexibles, y compris des API sans serveur, des GPU réservés et des capacités de réglage fin, le tout accessible via une seule API compatible avec OpenAI.
FriendliAI
FriendliAI est une plateforme d'infrastructure d'IA générative conçue pour accélérer et optimiser l'inférence des modèles d'IA. Elle offre …
FriendliAI est une plateforme d'infrastructure d'IA générative conçue pour accélérer et optimiser l'inférence des modèles d'IA. Elle offre des solutions performantes et rentables pour déployer, servir et mettre à l'échelle de grands modèles de langage et multimodaux en production, avec des options flexibles pour des environnements dédiés, sans serveur ou sur site.