Avian
Visiter le site web



Avian Aperçu
Avian est une plateforme d'infrastructure IA de pointe conçue pour fournir l'inférence IA la plus rapide et la plus fiable du marché. Elle s'adresse aux développeurs, aux ingénieurs IA et aux entreprises qui ont besoin de hautes performances en termes de débit et de faible latence pour leurs applications IA. En exploitant le matériel le plus récent, tel que les GPU NVIDIA B200 et H200, et des techniques d'optimisation avancées comme le décodage spéculatif, Avian atteint des vitesses de pointe, établissant de nouvelles références pour des modèles comme DeepSeek R1 à 351 tokens par seconde.
La plateforme offre deux services principaux pour répondre à divers besoins : une API Serverless flexible et de puissants Déploiements Dédiés. Cette double approche permet aux utilisateurs soit d'intégrer rapidement des modèles de premier plan dans leurs applications avec un simple appel API, soit d'obtenir un contrôle total sur leur infrastructure pour exécuter des modèles personnalisés et affinés pour des tâches spécialisées. Avian est conçu pour l'échelle, fonctionnant sans limite de débit pour soutenir les applications à mesure qu'elles passent du prototype à la production complète.
Comment utiliser Avian
Démarrer avec Avian est simple et conçu pour l'efficacité des développeurs. Il existe deux méthodes principales pour exploiter sa puissance :
- Utiliser l'API Serverless d'Avian : C'est le moyen le plus rapide d'accéder à des modèles haute performance. Les développeurs peuvent simplement s'inscrire, obtenir une clé API et faire des requêtes à divers points de terminaison de modèles (par exemple, la série Meta Llama 3.1). Le processus implique une implémentation de code simple, similaire à d'autres API IA, permettant une intégration transparente dans les applications existantes sans gérer aucune infrastructure.
- Configurer des Déploiements Dédiés : Pour les utilisateurs qui ont besoin d'exécuter des modèles personnalisés de HuggingFace ou qui nécessitent des ressources dédiées pour un débit élevé constant, Avian propose des instances GPU dédiées. Les utilisateurs peuvent sélectionner le type de GPU souhaité (par exemple, NVIDIA H200 SXM), configurer la durée du déploiement et déployer leur modèle sur l'infrastructure optimisée d'Avian. C'est idéal pour les charges de travail de production qui exigent des performances et une allocation de ressources garanties.
Fonctionnalités principales de Avian
- Vitesse d'Inférence Record : Atteint des vitesses allant jusqu'à 351 tokens par seconde, surpassant de manière significative les moyennes de l'industrie et permettant des applications IA en temps réel.
- API Serverless : Fournit un accès payant à l'usage à une gamme de modèles haute performance comme Meta Llama 3.1 et DeepSeek R1, sans limite de débit.
- Déploiements GPU Dédiés : Offre des instances dédiées avec les derniers GPU NVIDIA (B200, H200, H100) pour déployer n'importe quel modèle de HuggingFace, garantissant des performances et un contrôle maximum.
- Sécurité de Niveau Entreprise : Propose des mesures de sécurité robustes, y compris la conformité SOC2 Type 2 (en cours), le respect du RGPD, le cryptage TLS 1.2+ et l'Authentification Multi-Facteurs (MFA). Les données ne sont pas stockées de manière permanente, garantissant la confidentialité des utilisateurs.
- Scalable et Prêt pour la Production : Conçu pour gérer des charges de travail de production à haut volume sans dégradation des performances, soutenant les entreprises dans leur croissance.
- Connecteurs de Données : Offre une suite de connecteurs pour des plateformes comme Looker Studio et Google Sheets, permettant une intégration de données transparente à partir de sources comme Google Analytics, Facebook Ads, et plus encore.
Cas d'utilisation pour Avian
L'infrastructure à grande vitesse d'Avian est adaptée à un large éventail d'applications IA exigeantes :
- Chatbots et Assistants IA en Temps Réel : Alimenter une IA conversationnelle capable de répondre instantanément, offrant une expérience utilisateur naturelle et fluide.
- Génération de Contenu à Grande Échelle : Permettre aux plateformes de générer des articles, des textes marketing et du code à une échelle et une vitesse sans précédent.
- Analyse et Synthèse de Données Complexes : Traiter et analyser de vastes quantités de données textuelles en temps réel pour l'analyse financière, la recherche et l'informatique décisionnelle.
- Déploiement de Modèles Propriétaires : Les entreprises avec des modèles entraînés ou affinés sur mesure peuvent les déployer sur l'infrastructure dédiée d'Avian pour des performances optimales en environnement de production.
Avantages de Avian
Avian se distingue sur le marché concurrentiel de l'infrastructure IA par plusieurs avantages clés :
- Performance Inégalée : Offre des vitesses d'inférence 3 à 10 fois plus rapides par rapport aux autres grands fournisseurs de cloud et services d'inférence.
- Flexibilité : Prend en charge à la fois les modèles standard via une API simple et les modèles personnalisés sur du matériel dédié, répondant à tous les niveaux de développement IA.
- Rapport Coût-Efficacité : Propose des prix compétitifs pour son API et ses instances dédiées, offrant un rapport performance-prix supérieur.
- Fiabilité et Scalabilité : L'absence de limites de débit et l'utilisation d'une infrastructure de production garantissent que les applications peuvent évoluer de manière transparente sans rencontrer de goulots d'étranglement de performance.
- Posture de Sécurité Solide : Un engagement clair envers la sécurité des données et la confidentialité renforce la confiance des clients d'entreprise qui traitent des informations sensibles.
Tarification et plans
Avian propose une structure de tarification transparente et flexible adaptée à différents modes d'utilisation :
- API Avian (Paiement à l'usage) : Les utilisateurs sont facturés par million de tokens pour l'entrée et la sortie. Les prix sont compétitifs et varient selon le modèle. Par exemple :
- Meta Llama 3.1 8B Instruct : 0,10 $ par million de tokens d'entrée/sortie.
- Meta Llama 3.1 70B Instruct : 0,45 $ par million de tokens d'entrée/sortie.
- Meta Llama 3.1 405B Instruct : 1,50 $ par million de tokens d'entrée/sortie.
- Déploiements Dédiés : Facturés à la seconde pour les instances GPU réservées. Idéal pour les charges de travail à haut débit. Exemples de tarifs pour les instances réservées :
- NVIDIA H100 SXM (80 Go HBM3) : À partir de 0,00139 $/seconde.
- NVIDIA H200 SXM (141 Go HBM3) : À partir de 0,00208 $/seconde.
- Précommandes de Nouveau Matériel : Avian propose également des précommandes pour du matériel de pointe comme le NVIDIA B200, permettant aux clients de sécuriser l'accès à la dernière technologie. Par exemple, un déploiement de 7 jours d'un DeepSeek R1 sur une configuration 8x NVIDIA B200 est au prix de 14 000 $.
Avian Commentaires (0)
Connectez-vous pour laisser un commentaire
Connectez-vous maintenantAvianAnalyse du trafic du site web
Trafic récent
Statut
Tendance du trafic mensuel
Localisation géographique
Top 5 pays / régions
-
🇺🇸 United States34,45%
-
🇻🇳 Vietnam30,53%
-
🇬🇧 United Kingdom20,68%
-
🇮🇳 India14,34%
Mots-clés populaires
| Mot-clé | Coût par clic (CPC) |
|---|---|
|
$0,23
|
|
|
$0,00
|
|
|
$0,96
|
|
|
$0,00
|
|
|
$0,00
|
Avian Alternatives
Voir tout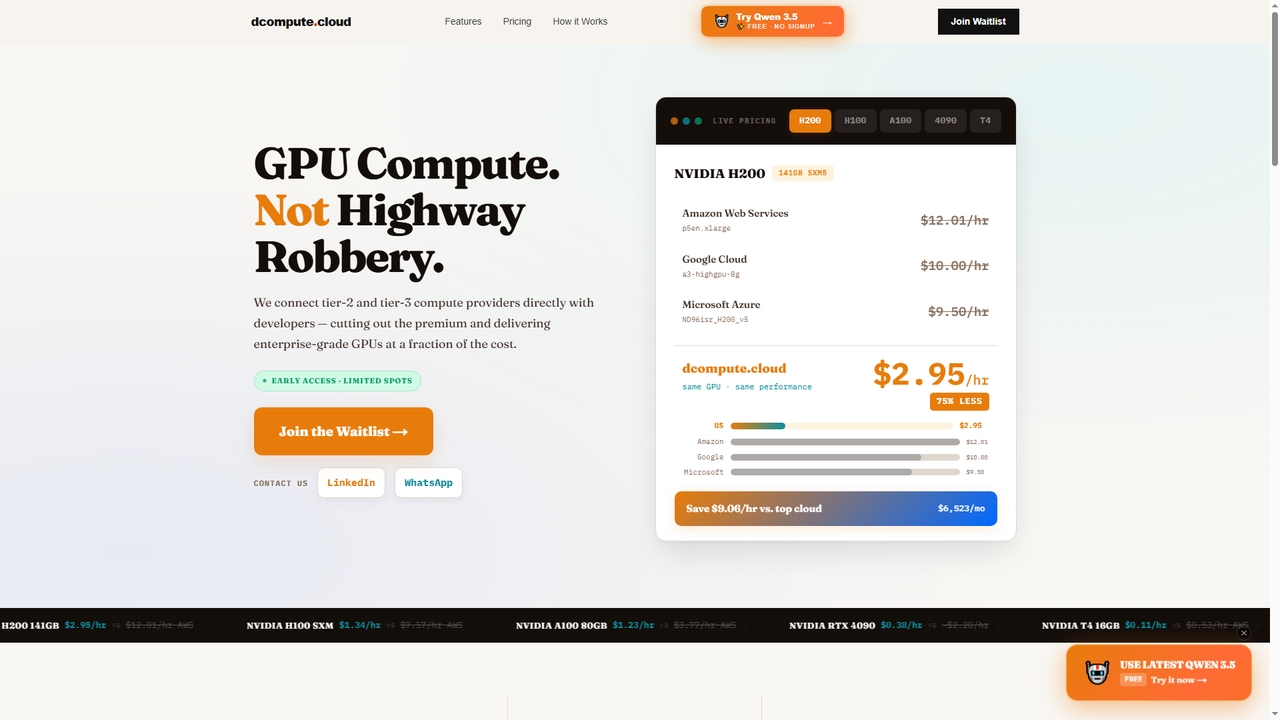
Dcompute
Dcompute est un marché de calcul GPU décentralisé qui connecte directement les développeurs à des fournisseurs de centres …
Dcompute est un marché de calcul GPU décentralisé qui connecte directement les développeurs à des fournisseurs de centres de données de niveau 2 et 3. Il propose des GPU NVIDIA de niveau entreprise (H200, H100, A100, RTX 4090, T4) pour une fraction du coût des grands fournisseurs de cloud, promettant des économies allant jusqu'à 90 %. La plateforme dispose d'un déploiement instantané, d'une API/tableau de bord unifié, d'une orchestration complète et d'une facturation purement à l'usage à la seconde, sans minimum.
Zetic.ai
Zetic.ai est une plateforme permettant aux développeurs de déployer des modèles d'IA directement sur des appareils périphériques (edge …
Zetic.ai est une plateforme permettant aux développeurs de déployer des modèles d'IA directement sur des appareils périphériques (edge devices), éliminant le besoin de serveurs GPU coûteux. Son pipeline automatisé, ZETIC.MLange, optimise et convertit les modèles pour une exécution sur l'appareil, atteignant des performances jusqu'à 60 fois plus rapides grâce à l'accélération NPU, tout en garantissant la confidentialité des données et en réduisant la latence.
Symphony
Symphony est une interface LLM universelle offrant une API compatible OpenAI pour déployer, gérer et faire évoluer les …
Symphony est une interface LLM universelle offrant une API compatible OpenAI pour déployer, gérer et faire évoluer les applications d'IA. Elle offre une fiabilité de niveau entreprise, des coûts réduits jusqu'à 20 % et prend en charge plus de 100 modèles d'IA majeurs comme GPT-5 et Llama 4, ce qui en fait la solution idéale pour les développeurs et les entreprises à la recherche d'une infrastructure d'IA efficace et robuste.
SiliconFlow
SiliconFlow est une plateforme d'infrastructure IA unifiée conçue pour l'inférence haute performance de grands modèles de langage (LLM) …
SiliconFlow est une plateforme d'infrastructure IA unifiée conçue pour l'inférence haute performance de grands modèles de langage (LLM) et de modèles multimodaux. Elle offre aux développeurs et aux entreprises des options de déploiement évolutives, rentables et flexibles, y compris des API sans serveur, des GPU réservés et des capacités de réglage fin, le tout accessible via une seule API compatible avec OpenAI.

Baseten
Baseten est une plateforme d'inférence de qualité production pour déployer, mettre à l'échelle et gérer des modèles d'IA. …
Baseten est une plateforme d'inférence de qualité production pour déployer, mettre à l'échelle et gérer des modèles d'IA. Elle offre des runtimes haute performance, des flux de travail de développeur fluides et des options de déploiement flexibles (cloud, auto-hébergé, hybride). Idéal pour les équipes d'ingénierie et de ML qui construisent des applications d'IA critiques.
Nexlayer
Nexlayer est la première plateforme cloud native d'agents, conçue pour permettre aux agents de codage IA de déployer …
Nexlayer est la première plateforme cloud native d'agents, conçue pour permettre aux agents de codage IA de déployer rapidement des applications prêtes pour la production. Elle automatise les infrastructures complexes, permettant aux développeurs et fondateurs de lancer des applications full-stack, des API et des bases de données en quelques minutes sans les frais généraux de DevOps.

Truefoundry
Truefoundry est une plateforme d'entreprise pour le déploiement, la gestion et la mise à l'échelle d'applications d'IA agentique. …
Truefoundry est une plateforme d'entreprise pour le déploiement, la gestion et la mise à l'échelle d'applications d'IA agentique. Elle fournit une passerelle IA unifiée pour orchestrer des flux de travail IA complexes, gérer les modèles et garantir la sécurité, la gouvernance et l'observabilité. Conçue pour les développeurs et les équipes MLOps, elle prend en charge les déploiements sur site, dans le cloud et hybrides, optimisant l'utilisation des GPU et accélérant la mise sur le marché.
Vespa.ai
Vespa.ai est une plateforme de recherche IA haute performance pour la création d'applications à grande échelle. Elle unifie …
Vespa.ai est une plateforme de recherche IA haute performance pour la création d'applications à grande échelle. Elle unifie la recherche vectorielle, la recherche textuelle et le classement par apprentissage automatique pour alimenter des cas d'utilisation avancés tels que la Génération Augmentée par Récupération (RAG), les moteurs de recommandation et la recherche intelligente. Conçue pour l'inférence en temps réel et la scalabilité, elle est utilisée par des entreprises de premier plan comme Spotify et Perplexity pour traiter des ensembles de données massifs avec une faible latence.

Nebius
Nebius est une plateforme cloud haute performance spécialement conçue pour les charges de travail exigeantes en IA et …
Nebius est une plateforme cloud haute performance spécialement conçue pour les charges de travail exigeantes en IA et en Machine Learning. Elle offre un accès évolutif aux derniers GPU NVIDIA, des instances uniques aux clusters massifs, complété par une suite de services gérés et un AI Studio intégré pour rationaliser l'ensemble du cycle de vie du ML, de la formation à l'inférence.
novita.ai
Novita AI est une plateforme cloud axée sur les développeurs, offrant un accès abordable et évolutif à plus …
Novita AI est une plateforme cloud axée sur les développeurs, offrant un accès abordable et évolutif à plus de 200 modèles d'IA via des API simples. Elle fournit des GPU sans serveur, des instances GPU dédiées et le déploiement de modèles personnalisés, permettant aux développeurs de créer et de faire évoluer des applications d'IA sans gérer l'infrastructure.
Avian Catégorie
Avian Étiquettes
Avian Métiers concernés
Avian Outil d'IA
Avian Fonction d'intégration
Copiez simplement le code d'intégration ci-dessous et collez ce superbe badge sur votre blog, article ou site officiel pour diriger le trafic directement vers la page de cet outil et augmenter rapidement votre visibilité et votre base d'utilisateurs !

Aucun commentaire pour l'instant, soyez le premier à commenter !