Nexa SDK
Nexa SDK est une boîte à outils puissante permettant aux développeurs de déployer n'importe quel modèle d'IA, y …
Nexa SDK est une boîte à outils puissante permettant aux développeurs de déployer n'importe quel modèle d'IA, y compris les modèles de pointe et de dernière génération, sur n'importe quel appareil (mobile, PC, IoT, automobile) en quelques minutes. Il offre une inférence sur l'appareil prête pour la production avec accélération matérielle sur les NPU, GPU et CPU, optimisée pour la vitesse et l'efficacité énergétique.
Oneinfer
Oneinfer est une plateforme d'inférence IA haute performance pour les développeurs. Elle offre une API unifiée pour accéder …
Oneinfer est une plateforme d'inférence IA haute performance pour les développeurs. Elle offre une API unifiée pour accéder à plus de 15 LLM comme GPT-4 et Claude, simplifiant l'intégration de l'IA. La plateforme propose un déploiement sans serveur, une mise à l'échelle automatique, une sécurité de niveau entreprise et une tarification à l'usage. Elle fournit également une place de marché pour la location d'instances GPU pour des charges de travail IA personnalisées.
Runexo
Runexo est une plateforme GPU cloud conçue pour optimiser le développement, l'entraînement et l'inférence de l'IA. Elle offre …
Runexo est une plateforme GPU cloud conçue pour optimiser le développement, l'entraînement et l'inférence de l'IA. Elle offre un accès instantané à des GPU haute performance pay-as-you-go et un stockage cloud sécurisé, permettant aux développeurs, chercheurs et entreprises de lancer des applications d'IA comme Stable Diffusion, ComfyUI et Fooocus en quelques secondes, sans configuration ni exigences matérielles.

BrainHost
BrainHost propose un hébergement KVM VPS haute performance avec stockage NVMe, conçu pour la vitesse et la fiabilité. …
BrainHost propose un hébergement KVM VPS haute performance avec stockage NVMe, conçu pour la vitesse et la fiabilité. Avec un provisionnement en 30 secondes, des centres de données mondiaux à Hong Kong et US West, et le panneau de contrôle intuitif VirtFusion, il fournit une infrastructure robuste pour les sites web, le commerce électronique, l'inférence d'IA et les applications de jeux. Une évolutivité flexible et un routage réseau avancé garantissent un accès stable et rapide dans le monde entier.
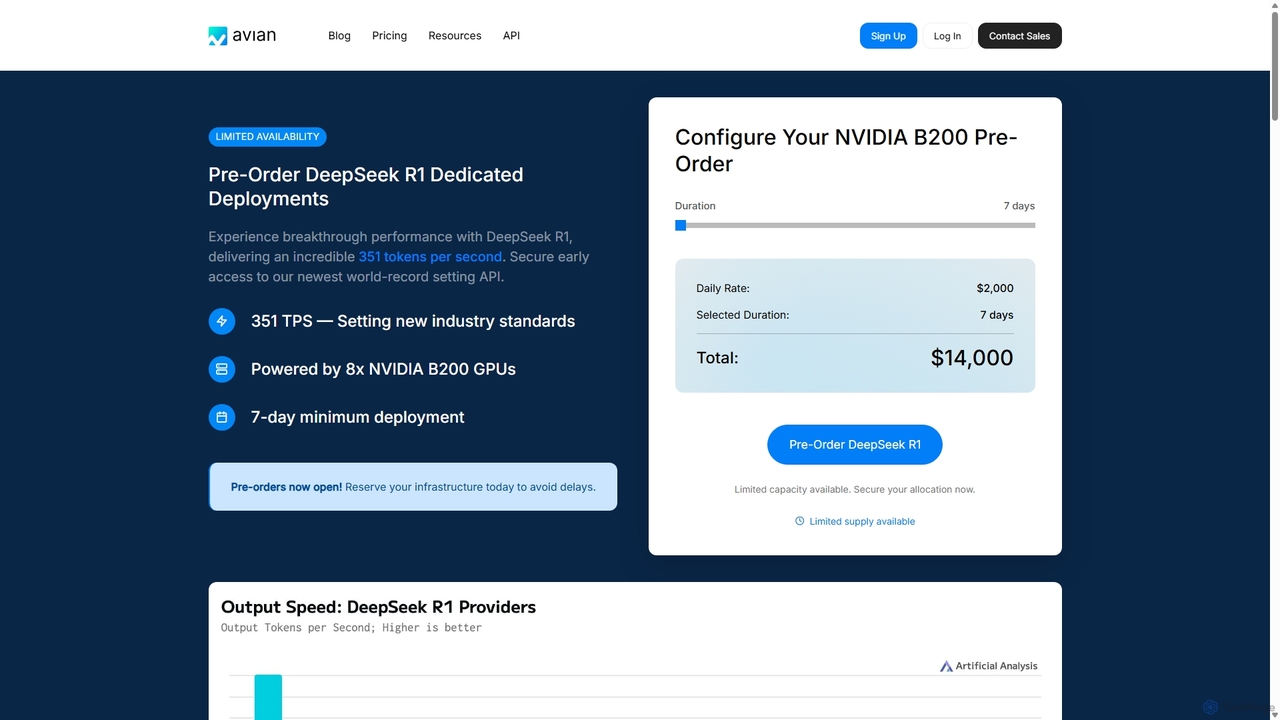
Avian
Avian est une plateforme d'inférence IA haute performance offrant des vitesses record pour les grands modèles de langage …
Avian est une plateforme d'inférence IA haute performance offrant des vitesses record pour les grands modèles de langage (LLM). Elle fournit à la fois une API sans serveur pour les modèles populaires et des déploiements GPU dédiés pour les modèles personnalisés de HuggingFace. Conçue pour la scalabilité et les charges de travail de production, Avian offre des vitesses d'inférence 3 à 10 fois plus rapides que la moyenne de l'industrie, avec une sécurité de niveau entreprise et des prix compétitifs.
DistributeAI
DistributeAI est une plateforme de supercalculateur d'IA décentralisée qui offre aux développeurs un accès évolutif et à faible …
DistributeAI est une plateforme de supercalculateur d'IA décentralisée qui offre aux développeurs un accès évolutif et à faible coût à une vaste bibliothèque de modèles d'IA open source. Elle permet de créer et de déployer des applications d'IA via une API et un SDK conviviaux pour les développeurs, tout en permettant aux utilisateurs de monétiser leur puissance de calcul inutilisée.

mancer
mancer est un service d'inférence de grands modèles de langage (LLM) à haute performance offrant un accès API …
mancer est un service d'inférence de grands modèles de langage (LLM) à haute performance offrant un accès API à une gamme variée de modèles puissants et affinés. Il est conçu pour les développeurs, les amateurs et les entreprises afin d'intégrer des capacités d'IA avancées dans leurs applications sans gérer une infrastructure complexe.
Groq
Groq est une plateforme d'inférence IA révolutionnaire offrant aux développeurs une vitesse et une rentabilité inégalées. Propulsé par …
Groq est une plateforme d'inférence IA révolutionnaire offrant aux développeurs une vitesse et une rentabilité inégalées. Propulsé par son unité de traitement du langage (LPU) sur mesure, Groq offre des performances en temps réel pour les grands modèles de langage (LLM), la reconnaissance vocale et les applications de synthèse vocale. Il propose une API conviviale pour les développeurs, permettant une intégration transparente pour créer des solutions d'IA de nouvelle génération à faible latence et à grande échelle.
Salad
Salad est une plateforme cloud de GPU distribuée qui exploite la puissance de calcul inutilisée d'un réseau mondial …
Salad est une plateforme cloud de GPU distribuée qui exploite la puissance de calcul inutilisée d'un réseau mondial de PC grand public. Elle offre aux entreprises des ressources GPU à la demande, très abordables et évolutives pour les charges de travail IA/ML, l'entraînement de modèles et l'inférence, réduisant les coûts de calcul jusqu'à 90 % par rapport aux fournisseurs de cloud traditionnels.

OctoAI
OctoAI est une plateforme de calcul haute performance permettant aux développeurs d'exécuter, d'ajuster et de mettre à l'échelle …
OctoAI est une plateforme de calcul haute performance permettant aux développeurs d'exécuter, d'ajuster et de mettre à l'échelle des modèles d'IA générative de manière efficace. Elle propose des points de terminaison d'API optimisés et prêts pour la production pour des modèles open-source populaires comme Llama, Mixtral et Stable Diffusion. En se concentrant sur des optimisations système approfondies, OctoAI offre des vitesses d'inférence plus rapides et des coûts réduits, permettant aux entreprises de créer et de déployer des applications d'IA évolutives sans gérer d'infrastructure complexe.
Cloudflare
Cloudflare est une plateforme cloud de connectivité mondiale offrant une suite complète de services pour la sécurité, la …
Cloudflare est une plateforme cloud de connectivité mondiale offrant une suite complète de services pour la sécurité, la performance et la fiabilité. Elle protège les sites web et les applications contre les menaces en ligne avec son WAF et son atténuation DDoS, accélère la livraison de contenu via son CDN mondial, et fournit une plateforme sans serveur pour que les développeurs puissent construire et déployer des applications, y compris des services alimentés par l'IA à la périphérie.
Qualcomm AI Hub
Une plateforme pour développeurs permettant d'optimiser et de déployer des modèles d'IA sur l'appareil. Qualcomm AI Hub fournit …
Une plateforme pour développeurs permettant d'optimiser et de déployer des modèles d'IA sur l'appareil. Qualcomm AI Hub fournit une bibliothèque de plus de 100 modèles pré-optimisés et des outils pour compiler, profiler et exécuter vos propres modèles sur du matériel Snapdragon réel, simplifiant ainsi le chemin vers la production pour les applications d'IA en périphérie (edge).
Awan LLM
Awan LLM est une plateforme API d'inférence LLM économique et sans restriction pour les développeurs et les utilisateurs …
Awan LLM est une plateforme API d'inférence LLM économique et sans restriction pour les développeurs et les utilisateurs avancés. Elle offre une génération de jetons illimitée pour un forfait mensuel fixe, éliminant les coûts par jeton. La plateforme donne accès à des modèles populaires comme Meta Llama 3.1 sans censure, fonctionnant sur du matériel propriétaire haute performance.
Banana
Banana était une plateforme GPU sans serveur conçue pour les développeurs d'IA afin de déployer et de mettre …
Banana était une plateforme GPU sans serveur conçue pour les développeurs d'IA afin de déployer et de mettre à l'échelle des modèles d'apprentissage automatique pour l'inférence. Elle offrait des fonctionnalités telles que l'autoscaling des GPU, une tarification au coût de calcul et une suite complète d'outils DevOps. Veuillez noter : La plateforme Banana a été officiellement arrêtée le 31 mars 2024 et n'est plus opérationnelle.