Groq
Visiter le site web
Groq Aperçu
Groq est une entreprise de technologie d'IA qui a développé une infrastructure révolutionnaire pour l'inférence d'IA, conçue dès le départ pour la vitesse, la qualité et la rentabilité. Au cœur de l'offre de Groq se trouve son unité de traitement du langage (LPU™) propriétaire, un nouveau type de processeur conçu spécifiquement pour les exigences de calcul de l'exécution de modèles d'IA, en particulier les grands modèles de langage (LLM). Contrairement aux GPU, qui ont été adaptés du traitement graphique, le LPU est spécialement conçu pour l'inférence, ce qui lui permet de fournir une latence prévisible, inférieure à la milliseconde, et un débit exceptionnellement élevé en jetons par seconde. Cela permet de créer des applications d'IA conversationnelles véritablement en temps réel qui étaient auparavant irréalisables.
La technologie est accessible via GroqCloud™, une plateforme complète qui permet aux développeurs et aux entreprises d'exploiter la puissance des LPU via une API simple et robuste. Groq prend en charge une large gamme de modèles open-source populaires, y compris diverses versions de Llama, Mistral, Qwen et Gemma, ainsi que des modèles spécialisés pour la reconnaissance automatique de la parole (ASR) comme Whisper et la synthèse vocale (TTS). Cet accent mis sur la vitesse et l'efficacité vise à alimenter une nouvelle vague d'innovation en rendant l'IA haute performance accessible et abordable pour une communauté mondiale de plus de 1,9 million de développeurs.
Comment utiliser Groq
La prise en main de Groq est conçue pour être simple pour les développeurs. La principale méthode d'interaction se fait via l'API GroqCloud™.
- Inscription : Créez un compte gratuit sur le site web de Groq pour accéder à la console développeur.
- Obtenir une clé API : Une fois inscrit, vous pouvez générer une clé API depuis votre tableau de bord. Cette clé authentifiera vos requêtes.
- Intégration : Avec la clé API, vous pouvez commencer à effectuer des appels vers les points de terminaison des modèles de Groq. Le processus d'intégration est simple, ne nécessitant souvent que quelques lignes de code pour remplacer un point de terminaison d'API existant (par exemple, d'OpenAI ou d'un autre fournisseur) par celui de Groq. La plateforme fournit une documentation claire et des SDK pour faciliter ce processus.
- Choisir un modèle : Sélectionnez parmi une liste variée de modèles LLM, ASR ou TTS pris en charge en fonction des besoins de votre application en termes de vitesse, de fenêtre de contexte et de capacité.
- Traitement par lots : Pour les tâches à grande échelle et non en temps réel, les développeurs peuvent utiliser l'API par lots. Cela permet de soumettre des milliers de requêtes de manière asynchrone avec une réduction de coût de 50 %, sans affecter les limites de débit standard.
- Déploiement en entreprise : Pour les grandes entreprises ayant des besoins spécifiques en matière de sécurité ou de performance, Groq propose également des solutions de déploiement sur site (on-premise).
Fonctionnalités principales de Groq
- Moteur d'inférence LPU™ : Un processeur conçu sur mesure spécifiquement pour l'inférence du langage IA, offrant des performances déterministes à latence ultra-faible.
- Vitesse d'inférence inégalée : Atteint des vitesses de pointe dans l'industrie, souvent mesurées en centaines de jetons par seconde, permettant des interactions en temps réel avec de grands modèles.
- Plateforme GroqCloud™ : Un service cloud entièrement géré et évolutif qui fournit un accès API à l'infrastructure alimentée par LPU.
- Large prise en charge des modèles open-source : Offre une sélection de LLM de premier plan (Llama, Mistral, Qwen), de modèles ASR (Whisper) et de modèles TTS.
- Tarification rentable : Un modèle de tarification à l'utilisation très compétitif basé sur les jetons, les caractères ou le temps, conçu pour offrir le coût par jeton le plus bas sans sacrifier les performances.
- API par lots : Une API asynchrone pour traiter de grandes charges de travail avec une remise importante, idéale pour le traitement et l'analyse de données hors ligne.
- Évolutivité et cohérence : L'architecture garantit que les performances restent constantes et rapides, même lorsque le trafic et les charges de travail augmentent.
- API conviviale pour les développeurs : Une API simple et facile à intégrer, largement compatible avec les normes existantes, facilitant le changement et la création.
Cas d'utilisation pour Groq
La vitesse extrême du LPU de Groq ouvre un large éventail d'applications nécessitant des réponses d'IA en temps réel :
- IA conversationnelle et chatbots : Création de robots de service client très réactifs, d'assistants virtuels et de compagnons interactifs capables de comprendre et de répondre instantanément.
- Création de contenu : Génération d'articles de blog, de contenu pour les réseaux sociaux, de textes marketing et même de livres entiers en quelques secondes.
- Transcription et résumé en temps réel : Transcription de l'audio de réunions ou d'événements en direct et génération de résumés à la volée.
- Applications à commande vocale : Alimentation d'interfaces utilisateur activées par la voix, rédaction d'e-mails par dictée et contrôle de logiciels par commandes vocales.
- Outils d'apprentissage interactifs : Création de plans de cours dynamiques et personnalisés et de parcours éducatifs qui s'adaptent en temps réel aux entrées de l'utilisateur.
- Analyse financière : Développement d'agents d'IA capables de fournir des analyses de graphiques boursiers en direct, des résumés d'actualités financières et des criblages de marché.
- Génération et assistance de code : Fourniture aux développeurs de suggestions de code instantanées, d'aide au débogage et d'explications.
Avantages de Groq
Le principal avantage de Groq réside dans son matériel spécialement conçu, ce qui se traduit par plusieurs avantages clés pour les utilisateurs :
- Vitesse fulgurante : En éliminant les goulots d'étranglement des architectures GPU traditionnelles, Groq offre les vitesses d'inférence les plus rapides du marché, ce qui est essentiel pour les applications destinées aux utilisateurs.
- Rapport prix-performance supérieur : L'efficacité du LPU permet à Groq de proposer ses services à un coût par jeton inférieur, rendant l'IA puissante plus viable économiquement pour les entreprises de toutes tailles.
- Performances prévisibles : Contrairement à certains systèmes qui ralentissent sous une forte charge, la latence de Groq reste constamment basse, garantissant une expérience utilisateur fiable à n'importe quelle échelle.
- Technologie pérenne : Alors que les modèles d'IA deviennent de plus en plus grands et complexes, l'architecture spécialisée de Groq est conçue pour gérer efficacement la prochaine génération de charges de travail d'IA.
- Facilité d'adoption : L'approche axée sur les développeurs avec une API simple garantit que les équipes peuvent rapidement intégrer la vitesse de Groq dans leurs applications existantes ou nouvelles avec un minimum d'effort.
Tarification et plans
Groq fonctionne sur un modèle de tarification freemium et à la demande, le rendant accessible aux développeurs individuels et évolutif pour les grandes entreprises.
- Niveau gratuit : Les utilisateurs peuvent s'inscrire et commencer à construire gratuitement pour tester la plateforme et ses capacités.
- Paiement à l'utilisation : Après le niveau gratuit, la tarification est à la demande. Pour les grands modèles de langage (LLM), les coûts sont calculés par million de jetons, avec des tarifs différents pour les jetons d'entrée et de sortie. Par exemple, un modèle rapide comme Llama 3 8B est tarifé à environ 0,05 $ par million de jetons d'entrée et 0,08 $ par million de jetons de sortie.
- Tarification ASR & TTS : Les modèles de reconnaissance automatique de la parole (ASR) comme Whisper sont tarifés à l'heure d'audio transcrit (par exemple, environ 0,02-0,11 $/heure). Les modèles de synthèse vocale (TTS) sont tarifés par million de caractères.
- Remise de l'API par lots : L'utilisation de l'API par lots pour de grands travaux asynchrones offre une remise de 50 % sur les tarifs standard à la demande.
- Solutions d'entreprise : Des options de tarification et de déploiement personnalisées, y compris des solutions sur site, sont disponibles pour les entreprises clientes sur demande.
Groq Commentaires (0)
Connectez-vous pour laisser un commentaire
Connectez-vous maintenantGroqAnalyse du trafic du site web
Trafic récent
Statut
Tendance du trafic mensuel
Localisation géographique
Top 5 pays / régions
-
🇮🇳 India47,26%
-
🇺🇸 United States23,34%
-
🇧🇷 Brazil13,64%
-
🇵🇰 Pakistan8,27%
-
🇮🇩 Indonesia7,49%
Source de trafic
| Type de source | Pourcentage |
|---|---|
|
Accès direct
|
77,60% |
|
Trafic référent
|
20,90% |
|
E-mail
|
1,50% |
Mots-clés populaires
| Mot-clé | Coût par clic (CPC) |
|---|---|
|
$1,61
|
|
|
$2,10
|
|
|
$2,53
|
|
|
$1,26
|
|
|
$2,23
|
Groq Alternatives
Voir tout
OpenAI
OpenAI est une entreprise de recherche et de déploiement en IA de premier plan, dédiée à garantir que …
OpenAI est une entreprise de recherche et de déploiement en IA de premier plan, dédiée à garantir que l'intelligence artificielle générale (AGI) profite à toute l'humanité. Elle développe des modèles de pointe comme GPT-5, ChatGPT pour l'IA conversationnelle, Sora pour la génération de vidéo à partir de texte, et DALL-E pour la génération d'images. Grâce à sa plateforme API robuste, OpenAI permet aux développeurs et aux entreprises d'intégrer de puissantes capacités d'IA dans leurs applications, stimulant l'innovation dans divers secteurs.

Inception Labs
Inception Labs présente une nouvelle génération de grands modèles de langage à diffusion (dLLM) jusqu'à 10 fois plus …
Inception Labs présente une nouvelle génération de grands modèles de langage à diffusion (dLLM) jusqu'à 10 fois plus rapides et moins chers que les modèles traditionnels. En s'appuyant sur une approche parallèle basée sur la diffusion, il offre une vitesse, une qualité et un contrôle sans précédent pour la génération de texte et de code, idéal pour les applications d'entreprise.
TextSynth
TextSynth offre aux développeurs un accès puissant et économique à une suite de modèles d'IA, y compris de …
TextSynth offre aux développeurs un accès puissant et économique à une suite de modèles d'IA, y compris de grands modèles de langage (LLM), de la conversion texte-image, texte-parole et parole-texte, via une API REST flexible et un terrain de jeu interactif. Il propose des modèles comme Llama, Mistral, Stable Diffusion et Whisper, optimisés pour la vitesse et l'accessibilité.
fal.ai
Une plateforme de médias génératifs pour les développeurs, fournissant des API ultra-rapides pour exécuter et affiner des modèles …
Une plateforme de médias génératifs pour les développeurs, fournissant des API ultra-rapides pour exécuter et affiner des modèles d'IA avancés pour les images, la vidéo et la 3D. Accédez à des modèles de pointe avec des vitesses d'inférence jusqu'à 4 fois plus rapides.

Ollama
Ollama est un puissant framework open-source pour exécuter localement de grands modèles de langage (LLM) comme Llama 3, …
Ollama est un puissant framework open-source pour exécuter localement de grands modèles de langage (LLM) comme Llama 3, Mistral et Gemma sur votre propre matériel. Disponible pour macOS, Windows et Linux, il simplifie la configuration et la gestion des modèles open-source, permettant un développement et une utilisation de l'IA privés, hors ligne et rentables.
Outspeed
Une API et un SDK pour les développeurs afin de créer et de déployer des compagnons vocaux IA …
Une API et un SDK pour les développeurs afin de créer et de déployer des compagnons vocaux IA avec émotion et mémoire en temps réel. Intégrez facilement des interactions vocales naturelles à faible latence dans les applications web et mobiles.
SiliconFlow
SiliconFlow est une plateforme d'infrastructure IA unifiée conçue pour l'inférence haute performance de grands modèles de langage (LLM) …
SiliconFlow est une plateforme d'infrastructure IA unifiée conçue pour l'inférence haute performance de grands modèles de langage (LLM) et de modèles multimodaux. Elle offre aux développeurs et aux entreprises des options de déploiement évolutives, rentables et flexibles, y compris des API sans serveur, des GPU réservés et des capacités de réglage fin, le tout accessible via une seule API compatible avec OpenAI.
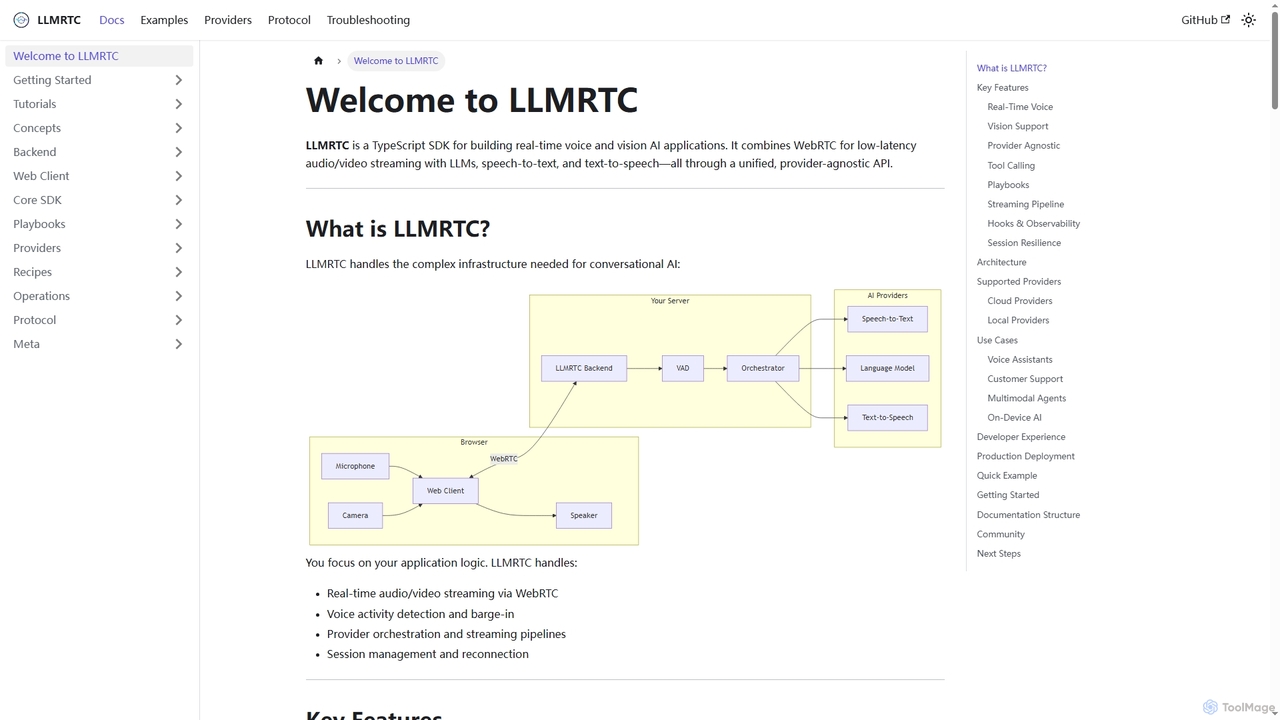
LLMRTC
LLMRTC est un SDK TypeScript pour la création d'applications d'IA vocales et visuelles en temps réel. Il intègre …
LLMRTC est un SDK TypeScript pour la création d'applications d'IA vocales et visuelles en temps réel. Il intègre WebRTC pour le streaming audio/vidéo à faible latence avec les LLM, la reconnaissance vocale et la synthèse vocale, le tout via une API unifiée et agnostique aux fournisseurs. Les développeurs peuvent se concentrer sur la logique applicative tandis que LLMRTC gère l'infrastructure complexe de l'IA conversationnelle.

InternAI (Shusheng)
InternAI (Shusheng) est une suite complète de modèles de fondation open-source et haute performance développée par le Laboratoire …
InternAI (Shusheng) est une suite complète de modèles de fondation open-source et haute performance développée par le Laboratoire d'IA de Shanghai. Elle couvre le langage, la multimodalité, la prévision météorologique, la conception aérospatiale, la modélisation 3D, la finance et la recherche scientifique, visant à stimuler l'innovation mondiale.
ComfyOnline
Une plateforme cloud pour exécuter des workflows ComfyUI en ligne sans matériel coûteux. Elle offre un environnement sans …
Une plateforme cloud pour exécuter des workflows ComfyUI en ligne sans matériel coûteux. Elle offre un environnement sans serveur, un déploiement d'API en un clic pour les applications d'IA, et un accès payant à l'utilisation à des GPU haute performance comme H100 et A100. Elle simplifie l'ensemble du processus, de la création du workflow au déploiement évolutif.
Groq Catégorie
Groq Étiquettes
Groq Outil d'IA
Groq Fonction d'intégration
Copiez simplement le code d'intégration ci-dessous et collez ce superbe badge sur votre blog, article ou site officiel pour diriger le trafic directement vers la page de cet outil et augmenter rapidement votre visibilité et votre base d'utilisateurs !

Aucun commentaire pour l'instant, soyez le premier à commenter !