Crawly
Visiter le site web
Crawly Aperçu
Crawly est un robot d'indexation web puissant et intelligent développé par Diffbot, un leader de l'extraction de données alimentée par l'IA. Il est conçu pour éliminer complètement les défis manuels et techniques du web scraping. Au lieu d'écrire du code complexe ou d'utiliser des sélecteurs fragiles qui se cassent avec les mises à jour de sites web, Crawly s'appuie sur une intelligence artificielle avancée, y compris la vision par ordinateur et le traitement du langage naturel, pour comprendre et interpréter les pages web comme un humain. Cela lui permet d'identifier et d'extraire automatiquement des données complètes et structurées d'un site web entier avec une seule URL en entrée.
La promesse principale de Crawly est de 'transformer les sites web en données en quelques secondes'. Il navigue à travers un site web, suit les liens et analyse la structure de chaque page pour différencier les différents types de contenu tels que les articles, les produits, les discussions et les galeries d'images. Les données extraites sont ensuite organisées dans un format propre et structuré, prêtes à être utilisées immédiatement dans des applications, des analyses de données ou des modèles d'apprentissage automatique.
Comment utiliser Crawly
L'utilisation de Crawly est conçue pour être incroyablement simple et accessible à tous, quel que soit le niveau de compétence technique. Le processus ne comporte que quelques étapes :
- Entrer l'URL : Rendez-vous sur le site web de Crawly. Dans le champ de saisie prévu, entrez l'URL complète du site que vous souhaitez explorer.
- Fournir l'e-mail : Entrez votre adresse e-mail. Elle est utilisée pour vous notifier et vous livrer les résultats une fois l'exploration terminée.
- Lancer l'exploration : Cliquez sur le bouton 'Crawl My Website'. Le moteur d'IA de Crawly commencera alors à parcourir l'ensemble du site, à analyser les pages et à extraire les informations.
- Télécharger les données : Une fois le processus terminé, vous recevrez les données extraites. Vous pouvez les télécharger dans des formats pratiques et structurés comme JSON ou CSV, ce qui facilite leur importation dans des bases de données, des feuilles de calcul ou d'autres logiciels.
Fonctionnalités principales de Crawly
- Extraction automatique alimentée par l'IA : Utilise l'IA avancée de Diffbot pour reconnaître et extraire automatiquement les données d'articles, de produits, de discussions, etc., sans aucune configuration manuelle.
- Champs de données complets : Extrait un riche ensemble de points de données, y compris le Titre, le Texte, le HTML, les Commentaires, la Date, l'Auteur, l'URL de l'Auteur, les Images, les Vidéos, les Informations sur l'Éditeur (Pays, Nom) et la Langue.
- Reconnaissance d'entités : Identifie et balise automatiquement les entités dans le texte, telles que les personnes, les organisations et les lieux, ajoutant une autre couche de métadonnées précieuses.
- Exploration complète du site : Contrairement aux scrapers de page unique, Crawly navigue sur un site web entier pour collecter des données de manière exhaustive.
- Sortie de données structurées : Fournit des données propres et bien structurées aux formats JSON ou CSV, éliminant le besoin de post-traitement et de nettoyage des données.
- Solution sans code : Ne nécessite aucune compétence en programmation ni connaissance des technologies de web scraping, ce qui le rend accessible aux spécialistes du marketing, aux chercheurs et aux analystes commerciaux.
- Robuste et résilient : Parce qu'il comprend la structure sémantique du contenu, il n'est pas facilement cassé par les changements de mise en page du site web, un problème courant avec les scrapers traditionnels.
Cas d'utilisation pour Crawly
Crawly est un outil polyvalent adapté à un large éventail d'applications :
- Étude de marché : Collectez automatiquement les informations sur les produits des concurrents, les prix, les avis des clients et les mentions dans la presse pour obtenir un avantage concurrentiel.
- Génération de leads : Extrayez les coordonnées, les informations sur l'entreprise et le personnel clé des sites web d'entreprise et des annuaires en ligne.
- Agrégation de contenu : Créez un fil d'actualités personnalisé ou une plateforme de contenu en agrégeant des articles, des billets de blog et des vidéos de plusieurs sources.
- Données pour l'apprentissage automatique : Créez de grands ensembles de données de haute qualité pour entraîner des modèles d'apprentissage automatique, tels que l'analyse des sentiments sur les avis de produits ou l'analyse des tendances à partir d'articles de presse.
- Veille de marque : Suivez en temps réel la manière dont votre marque, vos produits ou vos dirigeants sont mentionnés sur le web.
Avantages de Crawly
Le principal avantage de Crawly est sa simplicité et sa puissance. Il démocratise l'extraction de données web, permettant aux non-développeurs d'effectuer des tâches qui nécessiteraient normalement une équipe d'ingénieurs. Il permet d'économiser d'énormes quantités de temps et de ressources en automatisant l'ensemble du processus de scraping. De plus, son approche basée sur l'IA garantit une plus grande précision et une meilleure résilience que les méthodes traditionnelles, fournissant un flux fiable de données de haute qualité. En tant que produit de Diffbot, il est soutenu par une technologie de niveau entreprise approuvée par de grandes sociétés du monde entier.
Tarification et plans
Crawly propose une exploration d'essai gratuite directement depuis sa page d'accueil, permettant aux utilisateurs de tester ses capacités en entrant une URL et une adresse e-mail. Ceci est conçu pour fournir un échantillon des données structurées que l'outil peut produire. Pour des besoins plus étendus, tels que l'exploration à grande échelle, l'extraction fréquente de données ou l'accès à l'API pour une utilisation programmatique, les utilisateurs s'abonneraient généralement à la suite complète d'outils proposée par sa société mère, Diffbot. La tarification de Diffbot est échelonnée, avec des plans disponibles pour les startups, les entreprises et les grandes entreprises, offrant différents niveaux d'appels d'API et de fonctionnalités.
Crawly Commentaires (0)
Connectez-vous pour laisser un commentaire
Connectez-vous maintenantCrawlyAnalyse du trafic du site web
Trafic récent
Statut
Tendance du trafic mensuel
Localisation géographique
Top 5 pays / régions
-
🇺🇸 United States49,82%
-
🇮🇳 India40,61%
-
🇯🇵 Japan9,57%
Mots-clés populaires
| Mot-clé | Coût par clic (CPC) |
|---|---|
|
$3,74
|
|
|
$0,00
|
|
|
$0,00
|
|
|
$3,25
|
|
|
$2,40
|
Crawly Alternatives
Voir tout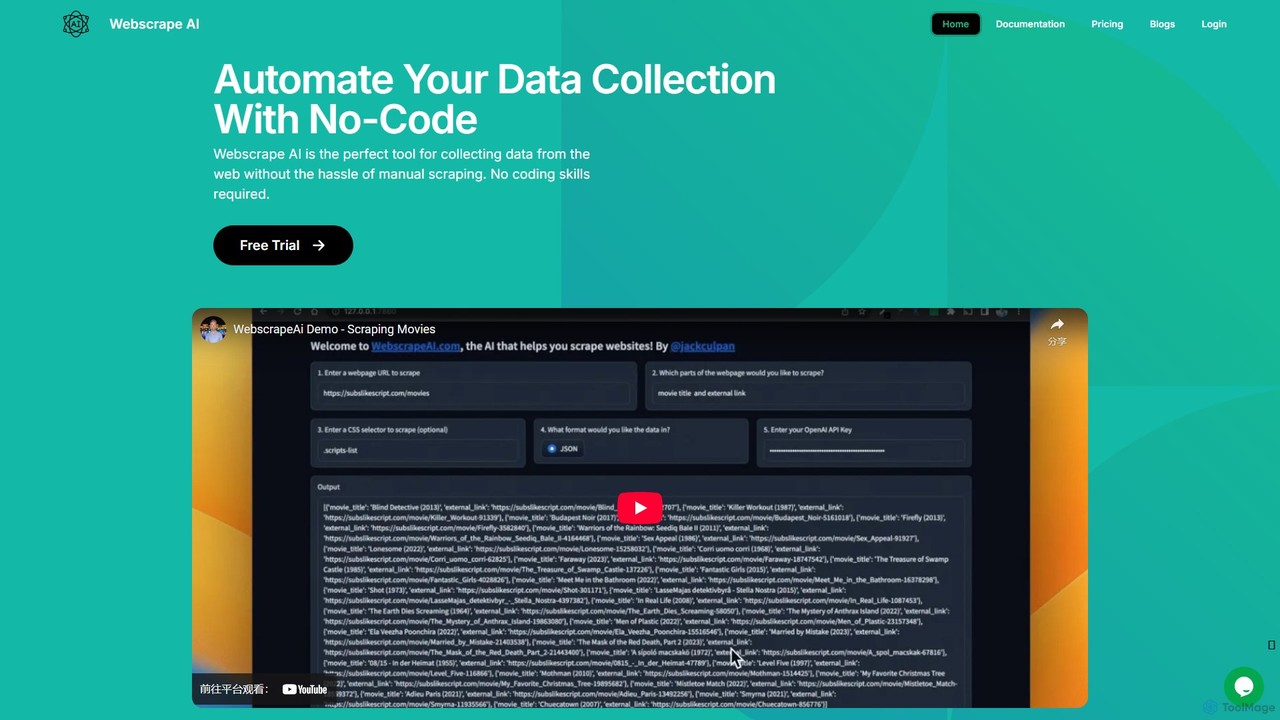
webscrapeai
WebscrapeAI est une plateforme sans code, alimentée par l'IA, conçue pour automatiser la collecte de données web. Fournissez …
WebscrapeAI est une plateforme sans code, alimentée par l'IA, conçue pour automatiser la collecte de données web. Fournissez simplement une URL et spécifiez les données dont vous avez besoin, et l'IA gère l'ensemble du processus de scraping. Il prend en charge les sites web dynamiques, le scraping en masse, l'intégration de proxy et offre une API pour les développeurs, rendant l'extraction de données rapide, précise et accessible à tous.
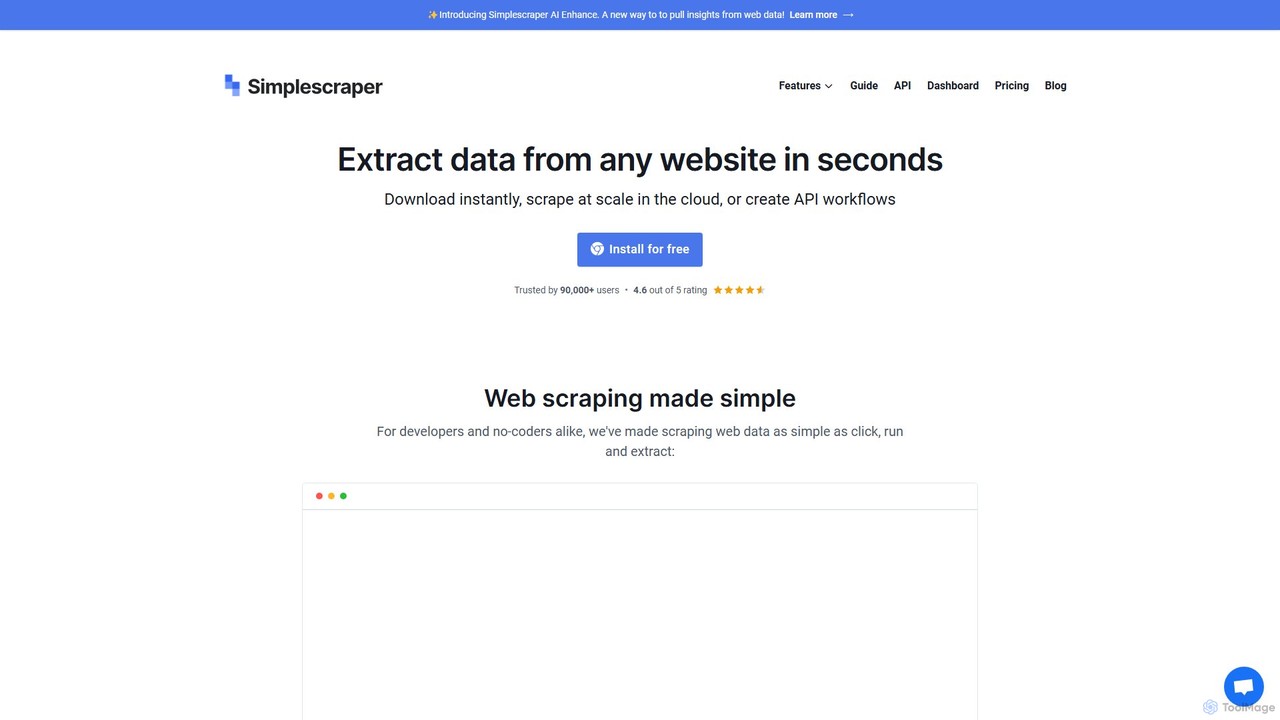
Simplescraper
Simplescraper est un puissant outil de web scraping qui extrait des données de n'importe quel site web en …
Simplescraper est un puissant outil de web scraping qui extrait des données de n'importe quel site web en quelques secondes. Il propose une extension Chrome conviviale pour la sélection de données sans code, une automatisation basée sur le cloud pour le scraping à grande échelle, et une fonctionnalité innovante d'IA (AI Enhance) pour extraire des informations à l'aide de simples invites. Transformez les sites web en données structurées (CSV, JSON) ou en API instantanées, et intégrez-les avec des outils comme Google Sheets et Airtable.

MrScraper
MrScraper est un outil de web scraping sans code, alimenté par l'IA, qui permet aux utilisateurs d'extraire sans …
MrScraper est un outil de web scraping sans code, alimenté par l'IA, qui permet aux utilisateurs d'extraire sans effort des données structurées de n'importe quel site web. Il automatise le processus de collecte de données, contournant les mesures anti-bot comme les CAPTCHAs et les blocages d'IP, ce qui le rend idéal pour l'intelligence tarifaire, les études de marché et la génération de leads.
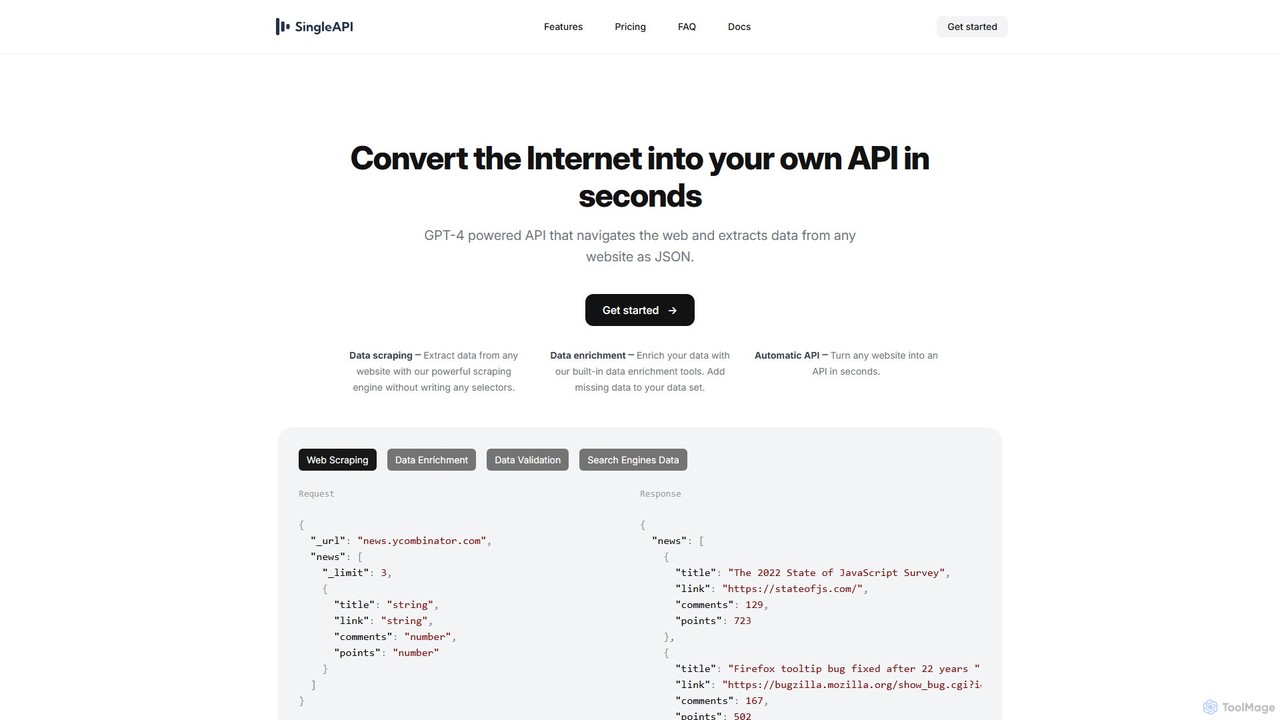
SingleAPI
SingleAPI est un outil alimenté par GPT-4 qui convertit instantanément n'importe quel site web en une API JSON …
SingleAPI est un outil alimenté par GPT-4 qui convertit instantanément n'importe quel site web en une API JSON structurée. Il simplifie le web scraping, l'extraction de données et l'enrichissement de données sans écrire de code ou de sélecteurs, permettant aux utilisateurs d'accéder sans effort aux données web pour diverses applications.
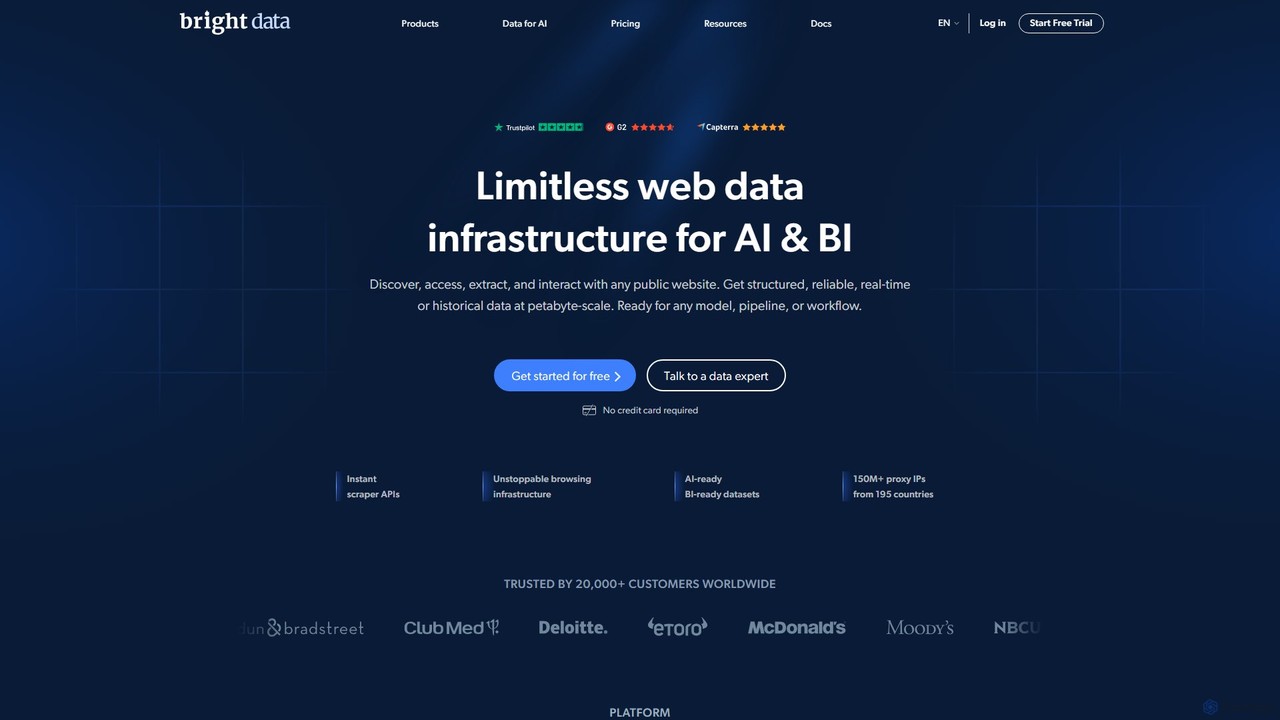
Bright Data
Bright Data est la première plateforme mondiale de données web, offrant une suite complète d'outils comprenant des réseaux …
Bright Data est la première plateforme mondiale de données web, offrant une suite complète d'outils comprenant des réseaux de proxys, des scrapers web alimentés par l'IA et des ensembles de données prêts à l'emploi. Elle permet aux entreprises de collecter de grandes quantités de données web publiques pour l'entraînement de l'IA, les études de marché et la veille concurrentielle.
Kadoa
Kadoa est une plateforme de web scraping sans code, alimentée par l'IA, qui automatise l'extraction de données de …
Kadoa est une plateforme de web scraping sans code, alimentée par l'IA, qui automatise l'extraction de données de n'importe quel site web ou document. Elle permet aux utilisateurs de créer des pipelines de données évolutifs et auto-réparateurs en quelques minutes, éliminant les goulots d'étranglement techniques et fournissant des informations en temps réel pour la finance, le commerce de détail et l'intelligence de marché.
Octoparse
Octoparse est un puissant outil de web scraping sans code qui permet à quiconque d'extraire des données de …
Octoparse est un puissant outil de web scraping sans code qui permet à quiconque d'extraire des données de sites web sans programmation. Il dispose d'un concepteur de flux de travail visuel, d'un assistant IA pour une configuration facile et de centaines de modèles prédéfinis pour les sites populaires. Grâce à l'automatisation basée sur le cloud, à la rotation d'IP et à la résolution de CAPTCHA, Octoparse gère efficacement les tâches de scraping complexes, transformant les pages web en données structurées pour la génération de leads, les études de marché, et plus encore.
Oxylabs
Oxylabs est un fournisseur de premier plan de services de proxy premium et de solutions de collecte de …
Oxylabs est un fournisseur de premier plan de services de proxy premium et de solutions de collecte de données web au niveau de l'entreprise. S'appuyant sur un immense réseau de proxys d'origine éthique de plus de 177 millions d'adresses IP, il propose des API de Scraper alimentées par l'IA, un débloqueur web et le nouveau AI Studio pour l'extraction de données en langage naturel. Il permet aux entreprises de collecter des données web publiques à grande échelle pour le commerce électronique, la cybersécurité, la protection des marques et les études de marché sans être bloquées.
Browse AI
Browse AI est une plateforme sans code qui permet aux utilisateurs d'extraire et de surveiller des données de …
Browse AI est une plateforme sans code qui permet aux utilisateurs d'extraire et de surveiller des données de n'importe quel site web. Entraînez facilement un robot pour scraper des informations, transformer des sites web en feuilles de calcul ou en API, et suivre automatiquement les changements. Conçu pour les marketeurs, les chercheurs et les développeurs afin d'automatiser la collecte de données sans écrire de code, il propose des robots pré-construits et des intégrations transparentes avec des outils comme Google Sheets et Zapier.
Curlent
Curlent est une plateforme de web scraping et d'extraction de données alimentée par l'IA qui automatise la collecte …
Curlent est une plateforme de web scraping et d'extraction de données alimentée par l'IA qui automatise la collecte de données structurées à partir de n'importe quel site web. Elle gère intelligemment le contenu dynamique, les mesures anti-bot et les mises en page complexes, fournissant des données propres et prêtes à l'emploi via une API puissante.
Crawly Catégorie
Crawly Étiquettes
Crawly Outil d'IA
Crawly Fonction d'intégration
Copiez simplement le code d'intégration ci-dessous et collez ce superbe badge sur votre blog, article ou site officiel pour diriger le trafic directement vers la page de cet outil et augmenter rapidement votre visibilité et votre base d'utilisateurs !

Aucun commentaire pour l'instant, soyez le premier à commenter !