Tensorlake
Visiter le site web
Tensorlake Aperçu
Tensorlake est un Cloud de Données IA complet conçu pour combler le fossé entre les données brutes non structurées et les applications d'IA avancées. Il sert de plateforme unifiée pour les développeurs et les entreprises afin de transformer de manière fiable des données complexes provenant de diverses sources — y compris les PDF, les images, les notes manuscrites et les feuilles de calcul — en formats structurés et prêts à l'ingestion comme JSON ou markdown. Ce processus est crucial pour alimenter les Grands Modèles de Langage (LLM), améliorer les systèmes de Génération Augmentée par Récupération (RAG) et automatiser les flux de travail métier critiques.
La plateforme repose sur deux piliers fondamentaux : l'API d'Ingestion de Documents et les Workflows Serverless. L'API d'Ingestion de Documents offre des capacités d'analyse quasi humaines, préservant la mise en page originale et l'ordre de lecture des documents tout en extrayant des informations avec une grande précision. Les Workflows Serverless permettent aux utilisateurs de construire et de déployer des pipelines de traitement de données de bout en bout, entièrement gérés, en utilisant Python. Ces workflows sont hautement évolutifs, capables de traiter des millions de documents, et rentables car ils se réduisent à zéro lorsqu'ils sont inactifs.
Comment utiliser Tensorlake
L'utilisation de Tensorlake implique un flux de travail simple et centré sur le développeur :
- Télécharger ou Connecter des Données : Commencez par télécharger des fichiers directement via l'API ou en connectant vos sources de données existantes. La plateforme prend en charge une vaste gamme de types de fichiers.
- Appeler l'API pour le Traitement : Utilisez l'API d'Ingestion de Documents pour traiter vos fichiers. Vous pouvez soit utiliser le point de terminaison 'Parse' pour une conversion de document générale, soit le point de terminaison 'Extract' avec un schéma Pydantic défini pour extraire des données spécifiques et structurées au format JSON.
- Construire des Workflows Personnalisés (Optionnel) : Pour des transformations de données plus complexes, utilisez les Workflows Serverless de Tensorlake. Écrivez des fonctions Python pour définir les étapes de votre pipeline de données, telles que le nettoyage, l'enrichissement et le routage des données extraites vers vos bases de données ou d'autres systèmes.
- Récupérer les Données Traitées : Accédez aux données transformées et structurées instantanément après la fin du travail ou configurez un webhook pour des notifications asynchrones. La sortie est optimisée pour une utilisation dans les applications d'IA.
- Intégrer avec l'IA/LLM : Fournissez les données structurées de haute qualité à vos pipelines RAG, agents IA ou autres modèles d'apprentissage automatique pour améliorer leur précision et leurs capacités.
Fonctionnalités principales de Tensorlake
- API d'Ingestion de Documents : Analyse tout type de fichier, des notes manuscrites aux feuilles de calcul complexes, en préservant la mise en page et le contexte.
- Extraction de Données Structurées : Convertit le contenu non structuré en morceaux propres de JSON ou de markdown en utilisant des schémas Python personnalisés pour une extraction de haute précision.
- Workflows Serverless : Construisez, déployez et mettez à l'échelle des pipelines de traitement de données basés sur Python sans gérer aucune infrastructure. Les workflows s'adaptent automatiquement à la demande.
- Optimisation pour RAG : Produit des morceaux de données structurées enrichies de métadonnées, spécifiquement optimisés pour améliorer la précision et la pertinence des systèmes de Génération Augmentée par Récupération.
- Évolutivité Massive : Conçu pour traiter plus de 100 000 documents par client et par jour et gérer 10 000 événements par seconde avec une latence extrêmement faible.
- Détection de Signature : Une fonctionnalité intégrée pour identifier automatiquement la présence ou l'absence de signatures dans les documents, permettant des déclencheurs d'automatisation intelligents.
- Sécurisé et Collaboratif : Fournit un Contrôle d'Accès Basé sur les Rôles (RBAC), des espaces de noms pour la protection des données et des journaux détaillés pour une visibilité et une conformité complètes.
Cas d'utilisation pour Tensorlake
Tensorlake est idéal pour les applications à enjeux élevés où la précision des données est primordiale :
- Systèmes RAG Avancés : Construisez des pipelines de récupération sophistiqués pour les LLM en combinant la recherche sémantique avec des filtres structurés dérivés du contenu du document (par ex., tableaux, figures, métadonnées).
- Automatisation des Services Financiers : Traitez les demandes de prêt, les documents d'audit fiscal et les états financiers pour extraire des informations clés et automatiser la prise de décision.
- Gestion des Données de Santé : Numérisez et structurez les dossiers des patients, les rapports de laboratoire et les articles de recherche médicale pour l'analyse et la conformité.
- Juridique et Conformité : Analysez les contrats, les titres de propriété et les dépôts légaux pour extraire des clauses, identifier les risques et garantir la conformité.
- Chaîne d'Approvisionnement et Logistique : Traitez les documents de commerce international, les factures et les connaissements pour rationaliser les opérations et améliorer la visibilité.
Avantages de Tensorlake
Tensorlake offre un avantage concurrentiel significatif :
- Précision Inégalée : Ses capacités d'analyse et d'extraction structurée quasi humaines fournissent des données de haute qualité, minimisant les erreurs dans les modèles d'IA.
- Développement Simplifié : L'approche code-first et pilotée par API simplifie la création de pipelines de données complexes, permettant aux équipes de construire plus rapidement.
- Évolutivité Rentable : L'architecture serverless et la tarification transparente à l'usage garantissent que vous ne payez que ce que vous utilisez, ce qui rend la mise à l'échelle économique.
- Plateforme de Bout en Bout : Fournit une solution unique et unifiée pour l'ingestion, la structuration et l'orchestration, éliminant le besoin de pipelines fragiles à outils multiples.
- Flexibilité : S'intègre de manière transparente avec des outils populaires comme LangChain et Qdrant pour améliorer les piles d'IA existantes.
Tarification et plans
Tensorlake propose un modèle de tarification transparent et basé sur l'utilisation, sans frais cachés pour le stockage ou la bande passante.
- Ingestion de Documents : Un tarif simple, à la demande, de 0,01 $ par page.
- Workflows Serverless : Facturé à la seconde en fonction des ressources de calcul consommées :
- Nvidia H100 : 0,0009 $/s
- Nvidia A100 : 0,0005 $/s
- CPU (1 vCPU) : 0,00004 $/s
- Mémoire (DDR4) : 0,00009 $/Go/s
- Sur Site (On-Premise) : Des plans d'entreprise personnalisés sont disponibles pour un déploiement au sein de votre propre réseau. Contactez le service commercial pour plus de détails.
Tensorlake Commentaires (0)
Connectez-vous pour laisser un commentaire
Connectez-vous maintenantTensorlakeAnalyse du trafic du site web
Trafic récent
Statut
Tendance du trafic mensuel
Localisation géographique
Top 5 pays / régions
-
🇺🇸 United States45,83%
-
🇨🇴 Colombia19,81%
-
🇳🇬 Nigeria13,65%
-
🇮🇳 India10,93%
-
🇻🇳 Vietnam9,78%
Source de trafic
| Type de source | Pourcentage |
|---|---|
|
Accès direct
|
81,84% |
|
Trafic référent
|
13,45% |
|
E-mail
|
4,71% |
Mots-clés populaires
| Mot-clé | Coût par clic (CPC) |
|---|---|
|
$0,00
|
|
|
$0,00
|
|
|
$4,07
|
|
|
$3,60
|
|
|
$6,31
|
Tensorlake Alternatives
Voir tout
ScrapeGraphAI
ScrapeGraphAI est une API de web scraping alimentée par l'IA qui transforme les sites web non structurés en …
ScrapeGraphAI est une API de web scraping alimentée par l'IA qui transforme les sites web non structurés en données JSON propres et structurées à l'aide de simples invites en langage naturel. Conçu pour les développeurs, les agents IA et les flux de travail automatisés, il simplifie l'extraction de données sans code complexe.

boundaryml
boundaryml (BAML) est un langage de programmation et une boîte à outils spécialisés permettant aux développeurs d'extraire de …
boundaryml (BAML) est un langage de programmation et une boîte à outils spécialisés permettant aux développeurs d'extraire de manière fiable des données structurées à partir de grands modèles de langage (LLM). Il transforme l'ingénierie complexe des prompts en un processus rationalisé, semblable à du code, garantissant des sorties typées et corrigées des erreurs sur divers LLM et langages de programmation comme Python et TypeScript. Il est conçu pour améliorer la fiabilité, réduire les coûts et accélérer les cycles de développement des applications d'IA.
Eventual
Eventual construit l'avenir de l'infrastructure de données avec Daft, un moteur de requête open-source haute performance pour les …
Eventual construit l'avenir de l'infrastructure de données avec Daft, un moteur de requête open-source haute performance pour les données multimodales. Il permet aux ingénieurs de traiter des images, des vidéos, de l'audio et du texte à l'échelle du pétaoctet avec la simplicité de SQL, accélérant considérablement les flux de travail d'IA et de ML sans nécessiter une expertise approfondie des systèmes distribués.

Apify
Apify est une plateforme full-stack de web scraping et d'automatisation qui permet aux développeurs de créer, déployer et …
Apify est une plateforme full-stack de web scraping et d'automatisation qui permet aux développeurs de créer, déployer et publier des outils d'extraction de données, appelés 'Actors'. Elle offre une vaste place de marché de scrapers pré-construits pour des sites populaires comme Google Maps, Instagram et TikTok, ainsi qu'une infrastructure cloud robuste pour créer des solutions personnalisées. Avec le support de Python et JavaScript, de bibliothèques open-source et d'intégrations transparentes, Apify simplifie la collecte de données web à toute échelle.
Firecrawl
Firecrawl est une API open-source, axée sur les développeurs, qui transforme n'importe quel site web en données propres …
Firecrawl est une API open-source, axée sur les développeurs, qui transforme n'importe quel site web en données propres et prêtes pour les LLM. Elle gère toutes les complexités du web scraping, y compris le rendu JavaScript, la rotation de proxy et les limites de taux, vous permettant d'alimenter des applications d'IA, des agents et des systèmes RAG avec un contenu web fiable. Elle offre des fonctionnalités de scraping, de crawling et de recherche via une API simple.

Docalysis
Docalysis est une plateforme alimentée par l'IA qui vous permet de discuter avec vos documents PDF. Obtenez des …
Docalysis est une plateforme alimentée par l'IA qui vous permet de discuter avec vos documents PDF. Obtenez des réponses instantanées, extrayez des informations clés et analysez plusieurs fichiers à la fois, économisant jusqu'à 95% de votre temps de lecture. Elle est conçue pour les chercheurs, les professionnels du droit et les entreprises afin d'améliorer la productivité et de débloquer des informations à partir de documents de manière sécurisée et efficace.
Chonkie
Chonkie est un framework d'ingestion de données open source conçu pour les applications d'IA. Il nettoie, segmente (chunking) …
Chonkie est un framework d'ingestion de données open source conçu pour les applications d'IA. Il nettoie, segmente (chunking) et enrichit efficacement diverses sources de données comme les PDF, le code et le texte, préparant des données optimisées et prêtes pour le contexte pour les grands modèles de langage afin d'améliorer la précision, de réduire les hallucinations et de renforcer les systèmes de génération augmentée par la récupération (RAG).
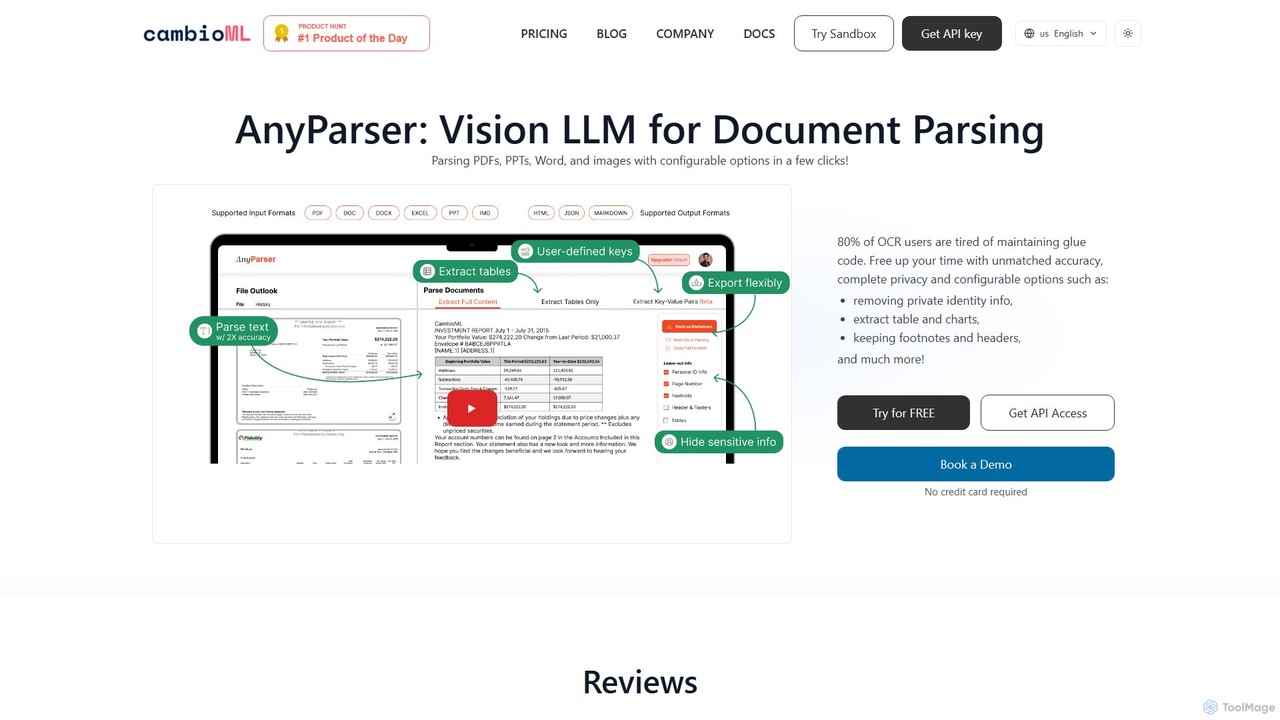
CambioML
CambioML propose l'API AnyParser, un puissant LLM de Vision conçu pour l'analyse de documents de haute précision. Il …
CambioML propose l'API AnyParser, un puissant LLM de Vision conçu pour l'analyse de documents de haute précision. Il extrait du texte, des tableaux, des graphiques et des paires clé-valeur à partir de PDF, d'images et de documents Office. Avec des fonctionnalités telles que la rédaction des PII, des sorties configurables et un traitement en temps réel, il est idéal pour les développeurs et les entreprises des secteurs de la finance, de la recherche et de l'analyse de données pour automatiser les flux de travail d'extraction de données tout en garantissant la confidentialité et l'efficacité.
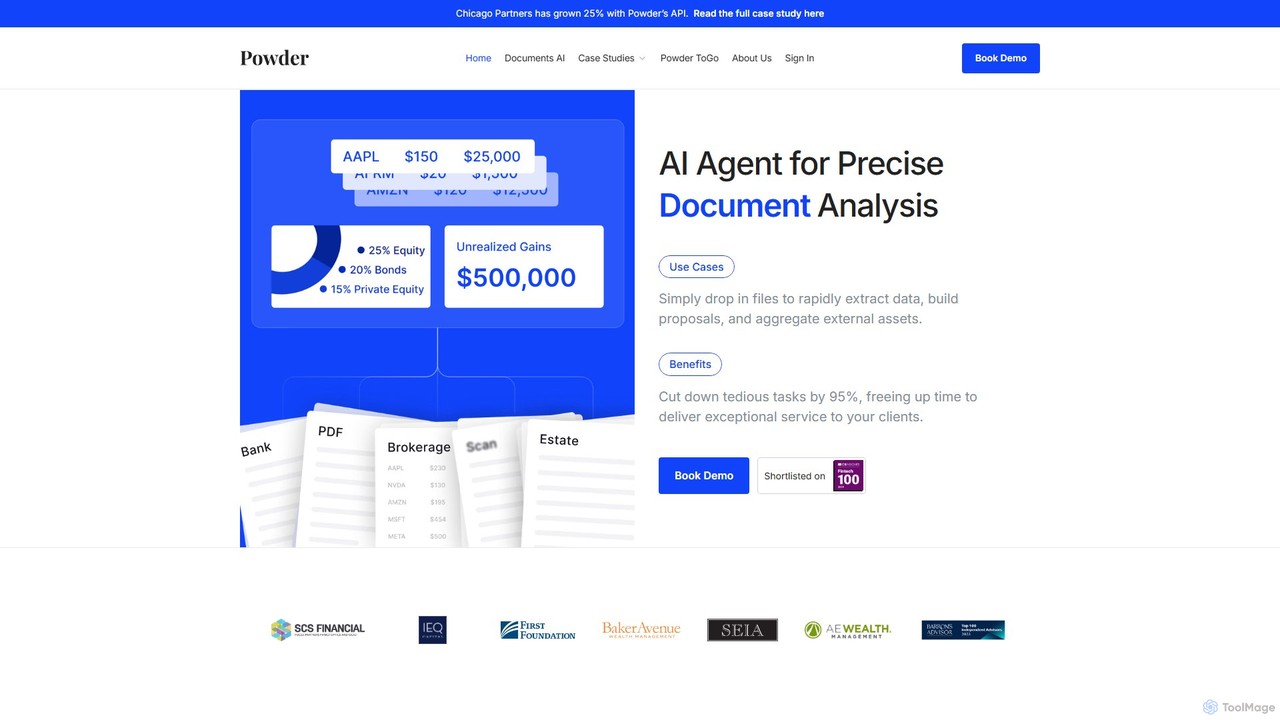
Powder
Powder est une plateforme alimentée par l'IA pour les sociétés de gestion de patrimoine, conçue pour automatiser l'analyse …
Powder est une plateforme alimentée par l'IA pour les sociétés de gestion de patrimoine, conçue pour automatiser l'analyse de documents. Elle extrait des données des relevés financiers et d'autres documents pour élaborer rapidement des propositions, analyser des portefeuilles et améliorer le service client, économisant jusqu'à 95 % du temps de traitement manuel.

Asimov
Asimov fournit une API de recherche IA fondamentale pour les développeurs afin de créer des agents et des …
Asimov fournit une API de recherche IA fondamentale pour les développeurs afin de créer des agents et des applications intelligents. Il intègre une recherche sémantique et un reclassement pour une haute précision, une ingestion de contenu simple et une gestion robuste des sources. La plateforme est conçue avec une sécurité de niveau entreprise et offre un suivi d'utilisation détaillé, ce qui en fait une solution complète pour créer des expériences de recherche personnalisées.
Tensorlake Catégorie
Tensorlake Étiquettes
Tensorlake Outil d'IA
Tensorlake Fonction d'intégration
Copiez simplement le code d'intégration ci-dessous et collez ce superbe badge sur votre blog, article ou site officiel pour diriger le trafic directement vers la page de cet outil et augmenter rapidement votre visibilité et votre base d'utilisateurs !

Aucun commentaire pour l'instant, soyez le premier à commenter !