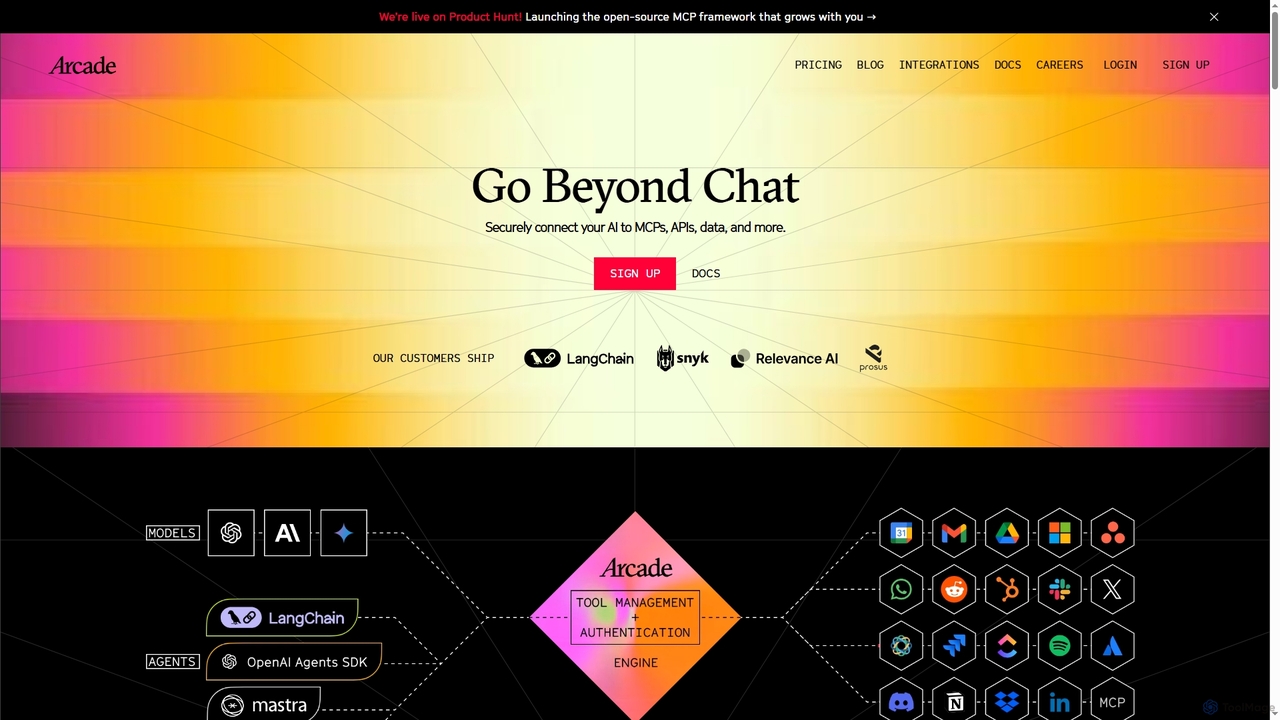
Arcade
Arcadeは開発者向けのAIツール呼び出しプラットフォームで、AIエージェントがユーザーに代わって安全にアクションを実行できるようにします。事前構築済みコネクタとカスタムSDKを介してAIをGmail、Slack、APIなどのサービスに接続し、複雑な認証(OAuth)を自動的に処理します。これにより、開発者はチャットを超えて実世界のタスクを実行するアシスタントを構築できます。
Arcadeは開発者向けのAIツール呼び出しプラットフォームで、AIエージェントがユーザーに代わって安全にアクションを実行できるようにします。事前構築済みコネクタとカスタムSDKを介してAIをGmail、Slack、APIなどのサービスに接続し、複雑な認証(OAuth)を自動的に処理します。これにより、開発者はチャットを超えて実世界のタスクを実行するアシスタントを構築できます。
フレームワークについて
AIエージェントフレームワークは、自律型AIエージェントを構築、管理、展開するために使用される基盤となるツールキットおよびライブラリです。計画、メモリ管理、ツール統合といったエージェントのコア機能に対して、構造化され再利用可能なコンポーネントを提供します。このアプローチは複雑なロジックを抽象化することで開発を加速させ、開発者が高度でタスク指向のエージェント作成に集中できるようにします。これらのフレームワークは多くの場合、複数の大規模言語モデル(LLM)や外部APIをサポートし、非常に多機能で強力なアプリケーションの作成を可能にします。
主な機能
- モジュラーアーキテクチャ:再利用可能なコンポーネントとチェーンを組み合わせることで、複雑なエージェントの構築を簡素化します。
- LLM統合:GPT、Claude、Llamaなどの様々なLLM用の標準化されたコネクタを提供します。
- ツール&API接続:エージェントが外部データソース、計算機、その他のソフトウェアAPIと対話できるようにします。
- 状態&メモリ管理:エージェントがコンテキストを保持し、過去の対話を記憶するためのメカニズムを提供します。
- デバッグ&可観測性:エージェントの実行ステップを追跡し、パフォーマンスを理解・最適化するためのツールが含まれています。
利用シーン
これらのフレームワークは、主に開発者、AIエンジニア、研究者によって使用されます。一般的な応用例には、内部データベースに接続するカスタム企業チャットボットの構築、ウェブを閲覧して情報を統合する自動リサーチアシスタントの作成、ワークフロー自動化のための複雑なマルチエージェントシステムの開発などがあります。
選択のポイント
AIエージェントフレームワークを選択する際は、主要なプログラミング言語(例:Python、TypeScript)、抽象化のレベルと制御のバランス、コミュニティとドキュメントの充実度を考慮してください。また、検索拡張生成(RAG)、マルチエージェントオーケストレーション、または既存の技術スタックとの統合の容易さなど、その特定の強みを評価することも重要です。
フレームワーク利用シーン
カスタム顧客サポートエージェントの構築
Eコマース企業の開発者がAIエージェントフレームワークを使用して、高度なサポートボットを作成します。このフレームワークは、大規模言語モデルをAPI経由で社内の注文データベースに接続し、製品FAQを含むベクトルデータベースにも接続します。これにより、エージェントは「最新の注文はどこにありますか?」や「電子機器の返品ポリシーは何ですか?」といった複雑な問い合わせに対して、リアルタイムで正確な情報を取得して対応できます。その結果、24時間365日、パーソナライズされたコンテキスト対応のサポートを提供するインテリジェントなエージェントが実現し、人間のエージェントの作業負荷を大幅に削減します。
リサーチ&データ分析アシスタントの開発
データサイエンティストがフレームワークを使用して、自動リサーチアシスタントを構築します。このエージェントは複数のツールで設計されています。記事を収集するためのウェブ検索ツール、学術論文からテキストを抽出するためのPDFリーダー、統計分析を実行するためのコードインタープリター(Python REPLなど)です。フレームワークはこれらのツールを調整し、エージェントが研究課題を受け取り、関連する情報源を見つけ、主要な発見を要約し、初期のデータ視覚化を生成できるようにします。これにより、研究プロセスで最も時間のかかる部分が自動化され、科学者はより高レベルの解釈と洞察の生成に集中できます。
マルチエージェントによるワークフロー自動化の作成
エンタープライズアーキテクトが、マルチエージェントフレームワークを使用して複雑なワークフロー自動化システムを設計します。このシステムは、新入社員のオンボーディングプロセスを専門とするエージェントチームをシミュレートします。あるエージェント(「人事コーディネーター」)は新入社員と通信して情報を収集します。別のエージェント(「ITプロビジョナー」)はこの情報を使用して、内部API経由でアカウントを作成し、ハードウェアを注文します。最後のエージェント(「マネージャー通知者」)は進捗を追跡し、採用マネージャーに更新情報を送信します。フレームワークはこれらのエージェント間の通信とタスクの引き継ぎを管理し、以前は手動でエラーが発生しやすかったプロセスを合理化する、堅牢で自律的なシステムを構築します。
LLM搭載アプリケーションのプロトタイピングとテスト
スタートアップのAIエンジニアが、新しい製品アイデアを迅速に構築し、検証する必要があります。彼らはエージェントフレームワークを使用して、概念実証(PoC)を迅速に組み立てます。フレームワークのプロンプトテンプレート、LLM統合、出力解析用の事前構築済みコンポーネントにより、数週間ではなく数日で機能的なプロトタイプを作成できます。さらに、フレームワークに組み込まれたデバッグおよびトレースツールは、エージェントが特定の決定を下す理由を理解するのに非常に貴重であり、本格的な構築の前にプロンプトとロジックを反復してパフォーマンスと信頼性を向上させるのに役立ちます。
検索拡張生成(RAG)システムの構築
ナレッジマネジメントの専門家が、企業の大量のプライベート文書リポジトリに基づいて質問に答えるチャットボットを作成する必要があります。彼らはLlamaIndexやLangChainのような、RAG専用に設計されたフレームワークを使用します。このフレームワークは、さまざまなドキュメント形式(PDF、DOCX)を取り込み、管理しやすいチャンクに分割し、ベクトル埋め込みを作成し、ベクトルデータベースに保存するツールを提供します。ユーザーが質問をすると、フレームワークの検索コンポーネントが最も関連性の高いドキュメントチャンクを見つけ、それをコンテキストとしてLLMに渡し、回答が正確で企業の独自データに基づいていることを保証し、幻覚を効果的に防ぎます。
ソフトウェア開発とコード生成の自動化
ソフトウェア開発者がエージェントフレームワークを使用して、「コーディング副操縦士」エージェントを構築します。このエージェントには、ファイルシステムから既存のコードベースを読み取り、ファイルに新しいコードを書き込み、テストを実行するためのターミナルコマンドを実行するツールが装備されています。開発者は、「ユーザープロファイル用の新しいAPIエンドポイントを追加し、そのための単体テストを作成する」といった高レベルのタスクを与えることができます。フレームワークは、エージェントがファイルを作成し、関数を書き、テストファイルを書き、テストスイートを実行するというステップを計画するのを助けます。これにより、反復的なコーディングタスクが自動化され、開発者はより複雑なアーキテクチャの決定や問題解決に集中でき、全体的な生産性が向上します。