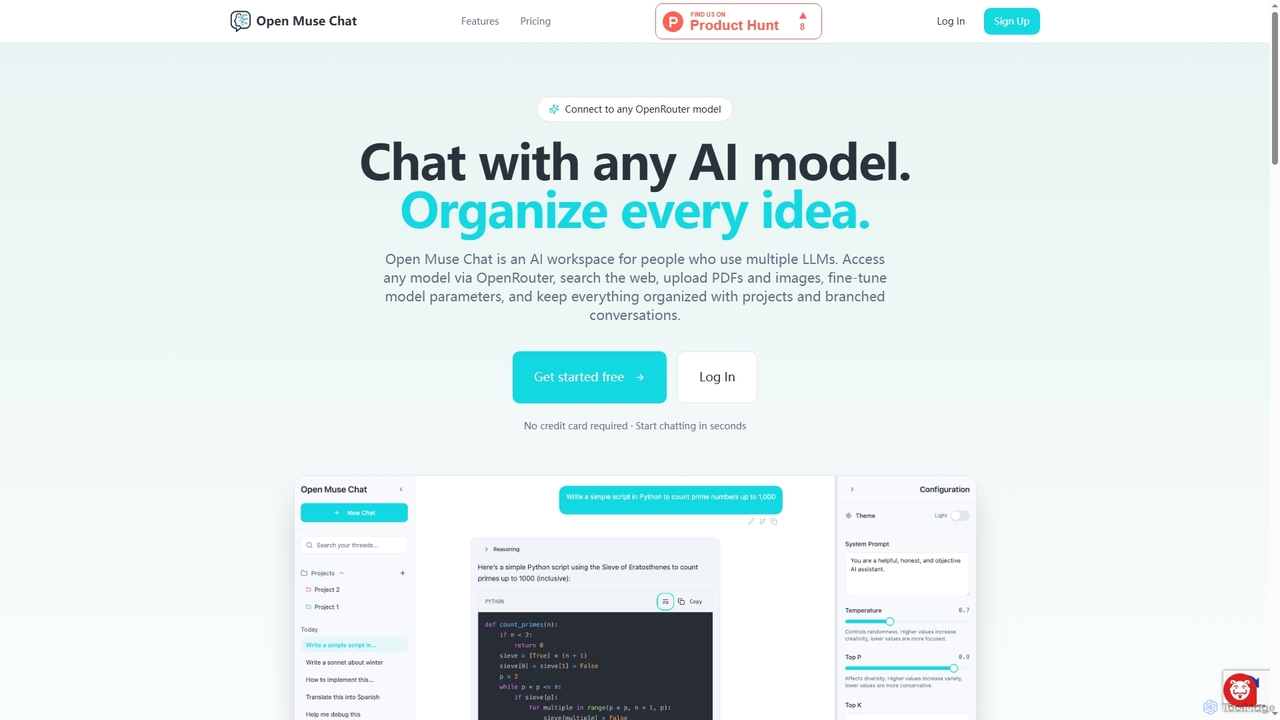
Open Muse Chat
Open Muse Chatは、様々な大規模言語モデル(LLM)を活用するユーザー向けに設計された、高度なマルチモデルAIチャットインターフェースです。OpenRouterのあらゆるモデルに接続し、ウェブ検索、コンテキストとしてのファイルアップロード(PDF、画像)を提供し、モデルパラメータを細かく制御できます。これらすべてが、プロジェクトと分岐した会話で整理されたワークスペース内で完結します。
Open Muse Chatは、様々な大規模言語モデル(LLM)を活用するユーザー向けに設計された、高度なマルチモデルAIチャットインターフェースです。OpenRouterのあらゆるモデルに接続し、ウェブ検索、コンテキストとしてのファイルアップロード(PDF、画像)を提供し、モデルパラメータを細かく制御できます。これらすべてが、プロジェクトと分岐した会話で整理されたワークスペース内で完結します。
マルチモデルについて
マルチモデルAIツールは、テキスト、画像、音声、動画など、複数のモダリティにわたる情報を処理および生成できる高度なAIチャットボットです。これらのツールは、洗練されたAIモデルを活用して、異なるデータタイプを組み合わせた複雑なクエリを理解し、より豊かで文脈を意識したインタラクションを提供します。これらは会話型AIの重要な進化を表し、テキストのみのコミュニケーションを超えて、より自然で包括的なデジタル体験を可能にします。
主要機能
- マルチモーダル入力処理:テキスト、音声、画像、動画からの情報を同時に理解し、統合します。
- マルチモーダル出力生成:テキスト、合成音声、画像、さらには短い動画クリップなど、さまざまな形式で応答を生成します。
- クロスモーダル推論:異なるモダリティ間の概念と情報を結び付け、一貫性のある関連性の高い回答を提供します。
- 文脈理解:多様な入力タイプを分析することで、ユーザーの意図をより深く理解し続けます。
適用シナリオ
マルチモデルAIツールは、テキストプロンプトと視覚的参照からコンテンツのアイデアを生成するクリエイティブ産業で非常に貴重です。顧客サービスでは、口頭での問い合わせと問題のアップロードされた画像を分析することで支援します。教育では、テキストの質問に基づいて図や口頭での説明を使用して複雑なトピックを説明できます。
選択のポイント
マルチモデルAIツールを選択する際は、サポートされているモダリティとクロスモーダル理解の品質を評価してください。アプリケーションに必要な特定の出力形式と、既存のワークフローとの統合能力を考慮してください。異なるデータタイプ間で生成されるコンテンツの正確性と一貫性、およびそのスケーラビリティと価格構造を評価してください。
マルチモデル利用シーン
視覚支援型カスタマーサポート
カスタマーサービス担当者は、マルチモデルチャットボットを使用してユーザーの問題を理解します。ユーザーは破損した製品部品の写真をテキスト説明とともにアップロードします。チャットボットは即座に画像を分析し、部品を特定し、関連するトラブルシューティング手順や交換部品へのリンクを提供することで、解決時間を大幅に短縮し、顧客満足度を向上させます。
インタラクティブな製品設計とプロトタイピング
製品デザイナーは、マルチモデルAIを使用してコンセプトを迅速に反復できます。テキスト記述、ラフスケッチ、音声コマンドを提供することで、AIは詳細な3Dモデルや視覚的なモックアップを生成し、リアルタイムでの調整やデザインバリエーションの探索を可能にします。これにより、初期設計段階が加速され、コンセプトから具体的なプロトタイプまでの時間が短縮されます。
マルチモーダルマーケティングコンテンツの生成
マーケティングスペシャリストは、魅力的なソーシャルメディア投稿を作成する必要があります。彼らはマルチモデルAIに新製品を説明するテキストプロンプトといくつかの参照画像を提供します。AIは魅力的な広告コピーだけでなく、いくつかのユニークな製品画像、さらには短いプロモーションビデオクリップも生成し、コンテンツ作成プロセスを効率化し、出力形式を多様化します。
視覚情報による顧客サポートの強化
技術サポートや製品のトラブルシューティングにおいて、顧客はテキストや音声で問題を説明しながら、同時に問題の写真や動画をアップロードできます。マルチモデルAIはすべての入力を分析して問題をより正確に診断し、段階的なテキスト指示、関連する図、さらには短い動画チュートリアルを解決策として提供します。
パーソナライズされた学習と個別指導
学生が複雑な科学概念で苦労している場合、マルチモデルAIに音声で質問し、図を示し、追加の文脈を入力できます。AIはすべての入力を処理し、テキストで概念を説明し、明確なイラストを生成し、さらには音声要約も提供することで、高度にパーソナライズされた包括的な学習体験を提供します。
マーケティング向け動的コンテンツ作成
マーケティングチームは、マルチモデルAIを活用して、単一のブリーフから多様なコンテンツを作成します。キャンペーンテーマとターゲットオーディエンスを入力すると、AIはソーシャルメディア投稿(テキスト+画像)、短いプロモーションビデオ、広告用のオーディオスクリプトを生成します。これにより、複数のプラットフォームでのコンテンツ制作が効率化され、ブランドの一貫性が保たれ、手作業が削減されます。
AIを活用したコンセプトデザインとプロトタイピング
プロダクトデザイナーは新しい家具を視覚化したいと考えています。彼らはそのスタイル、素材、寸法をテキストで記述し、スケッチをアップロードします。マルチモデルAIはこれらの入力を解釈して、高忠実度の3Dレンダリングや複数の2Dデザインバリエーションを生成し、広範な手作業なしでデザインコンセプトの迅速な反復と探索を可能にします。
パーソナライズされた教育チュータリング
学生は、テキストや音声で質問したり、宿題の画像をアップロードしたり、動画で概念を実演したりすることで、マルチモデルAIチューターと対話できます。AIは、学生の学習スタイルに合わせて、テキスト、図、口頭での説明、またはインタラクティブなシミュレーションを使用して、複雑な主題を明確にする説明を提供します。
コミュニケーションギャップの解消
コミュニケーションに課題を抱える個人は、マルチモデルツールを使用して、意図をモダリティ間で翻訳できます。例えば、ユーザーが物体を指し示し(画像入力)、部分的な文を話す(音声入力)と、AIが文を完成させ、完全なテキストまたは音声応答を提供することで、より自然で効果的なコミュニケーションを促進します。
アクセシビリティと包括的なコミュニケーション
マルチモデルAIツールは、モダリティ間で情報を変換することでアクセシビリティを向上させます。視覚障害のあるユーザーは、テキストまたは音声クエリを入力し、画像や動画コンテンツの音声説明を受け取ることができます。逆に、聴覚障害のあるユーザーは、音声コンテンツのテキストトランスクリプトや視覚的な要約を受け取ることができ、より包括的なデジタルインタラクションを促進します。
リアルタイムマルチモーダル異常検出
セキュリティの文脈では、マルチモデルAIはライブビデオフィードと音声入力を監視します。異常な視覚パターン(例:不正侵入)と特定の音声キュー(例:ガラスの破損音)が組み合わされて検出された場合、関連するビデオクリップとテキスト記述を含む詳細なレポートとともに、セキュリティ担当者に即座に警告を発し、プロアクティブな脅威検出を強化します。
リアルタイムイベント分析とレポート作成
ライブイベントや監視中、マルチモデルAIは動画、音声、テキスト(例:ソーシャルメディアフィード)の同時ストリームを処理できます。主要な活動を特定し、会話を文字起こしし、テキストによる議論を要約して、包括的なリアルタイムレポートやアラートを生成します。これは、セキュリティ監視、メディア分析、迅速なインシデント対応に不可欠です。