Wirestock
Wirestockは、クリエイティブフリーランサーとAI企業を繋ぐマーケットプレイスであり、AIトレーニングデータセットに高品質な画像、動画、イラストを提供して報酬を得ることを可能にします。
Wirestockは、クリエイティブフリーランサーとAI企業を繋ぐマーケットプレイスであり、AIトレーニングデータセットに高品質な画像、動画、イラストを提供して報酬を得ることを可能にします。
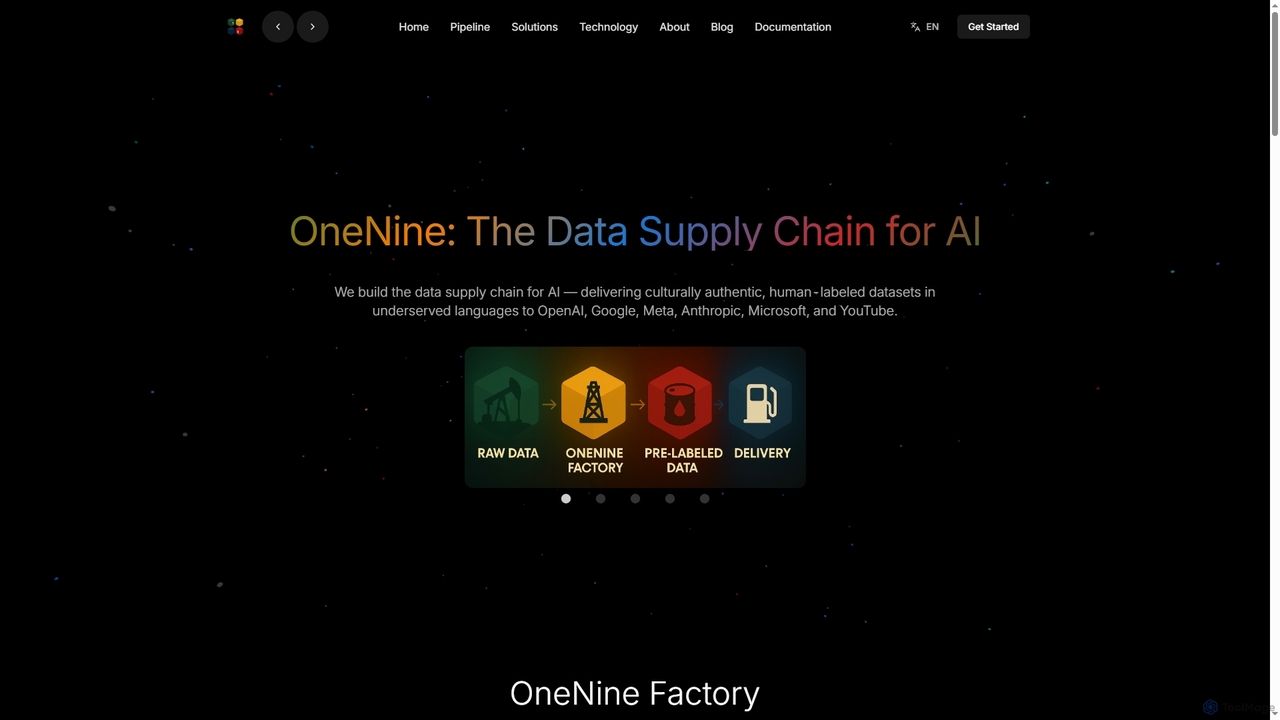

訓練データについて
訓練データツールは、機械学習モデル向けの高品質なデータセットを作成、管理、提供するために設計されたプラットフォームおよびサービスです。これらのツールは、データ準備という重要なプロセスを合理化し、データ注釈、合成データ生成、品質保証などの機能を提供します。あらゆるモデルの性能はその訓練データの品質に根本的に依存するため、これらのツールの主な価値は、正確で堅牢なAIシステムの開発を加速させることにあります。AI開発ライフサイクルの主要な構成要素として、効果的なモデルを構築するための基盤を形成します。
主な機能
- データ注釈とラベリング:画像、テキスト、音声などの様々なデータタイプに正確にタグ付けし、モデルのグラウンドトゥルースを作成するためのインターフェースと自動化ツールを提供します。
- 合成データ生成:限られたデータセットを補強したり、エッジケースをカバーしたり、機密情報を保護したりするために、人工的でありながら現実的なデータを作成します。
- データ管理とバージョン管理:データセットの異なるバージョンを保存、追跡、管理するための一元化されたプラットフォームを提供し、実験の再現性を確保します。
- 品質保証ワークフロー:レビュー、コンセンサス、エラー検出などの機能を含み、データの正確性と一貫性の高い基準を維持します。
- データセット調達:事前にラベル付けされた既製のデータセットへのアクセスや、カスタムデータを収集・準備するサービスを提供します。
利用シーン
これらのツールは、自動運転車の物体検出、ヘルスケアの医療画像分析、小売業の商品分類など、データ集約型の産業で不可欠です。機械学習エンジニア、データサイエンティスト、AI研究者は、自然言語処理からコンピュータビジョンに至るまでのタスクのためにデータセットを構築・改良するために日常的に使用しています。
選択のポイント
訓練データツールを選択する際は、特定のデータタイプ(例:ビデオ、3D点群)をサポートしているかを考慮してください。レビュアーの役割やコンセンサススコアリングなどの品質管理メカニズムを評価します。大規模プロジェクトに対するスケーラビリティや、既存のMLOpsパイプラインやクラウドストレージとの統合能力を査定します。最後に、セキュリティプロトコルとGDPRやHIPAAなどのデータプライバシー規制への準拠を確認してください。
訓練データ利用シーン
自動運転車の知覚モデルの訓練
自動運転車を開発する自動車技術企業は、歩行者、車両、交通標識、車線を正確に識別するために、コンピュータビジョンモデルを訓練する必要があります。データ注釈プラットフォームを使用して、ラベラーのチームが路上テストからキャプチャした何百万もの画像とビデオフレームにセマンティックセグメンテーションとバウンディングボックス注釈を実行します。プラットフォームの品質管理機能(コンセンサススコアリングやレビュアーワークフローなど)により、高い精度が保証されます。この細心の注意を払ってラベル付けされたデータセットは、複雑な都市環境を安全にナビゲートできる知覚モデルを訓練するために不可欠です。
医療画像診断AIの開発
ある医療研究機関は、MRIスキャンで初期段階の腫瘍を検出するAIモデルの構築を目指しています。専門の放射線科医が不足しており、手動注釈のコストが高いため、彼らは専門の医療画像注釈ツールを使用します。このツールは、DICOMサポートや半自動セグメンテーションなどの機能を提供し、プロセスを高速化します。患者のプライバシーを保護するため、プラットフォーム内のすべてのデータは匿名化されます。結果として得られる高品質のラベル付きデータセットにより、データサイエンスチームは、懸念される可能性のある領域を強調表示することで放射線科医を支援できるモデルを訓練し、より早期で正確な診断につながります。
不正検知のための合成データの生成
ある金融サービス会社は、不正検知モデルを改善したいと考えていますが、実際の不正事例が少なく、厳格なデータプライバシー規制によって制限されています。彼らは合成データ生成ツールを使用して、金融取引の大規模でバランスの取れたデータセットを作成します。このツールは、実際のデータの統計的特性をモデル化して、現実的でありながら完全に人工的な取引記録を生成します。これには、現実世界ではまれな複雑な不正シナリオも含まれます。これにより、機密性の高い顧客データを使用せずに、より堅牢なモデルを訓練でき、完全なコンプライアンスを維持しながら検出率を向上させることができます。
Eコマースの商品分類の改善
あるオンライン小売大手は数百万の商品を管理しており、新商品をを手動で分類するのは時間がかかり、間違いも起こりやすいです。彼らはデータラベリングサービスを利用して、大量の商品画像と説明のデータセットを分類します。このサービスは、人間のアノテーターとAIによる事前ラベリングを組み合わせて、商品を詳細な分類体系に効率的に分類します。このラベル付けされたデータは、サイトにアップロードされた新商品に自動的にカテゴリを割り当てる機械学習モデルの訓練に使用され、手作業を大幅に削減し、検索の関連性を向上させ、顧客のショッピング体験を向上させます。
NLPモデルの再現性のためのデータセット管理
あるAI研究所は新しい言語モデルを開発しており、テキストコーパスの異なるバージョンで何百もの実験を実行する必要があります。結果の再現性を確保するために、彼らはデータ管理およびバージョン管理プラットフォームを使用します。このツールにより、データセットへのすべての変更を追跡し、特定のデータセットバージョンをモデルのトレーニング実行にリンクし、以前の状態に簡単に戻すことができます。これは「データのためのGit」のように機能し、明確な監査証跡を提供し、混乱を防ぎます。この体系的なアプローチは、共同研究や検証可能な科学的知見を発表するために不可欠です。
採用アルゴリズムにおけるデータセットのバイアス監査
ある人事テクノロジー企業は、履歴書のスクリーニングを支援するAIツールを構築しています。歴史的なバイアスを永続させないために、彼らはデータ品質保証ツールを使用してトレーニングデータセットを監査します。このツールは、人口統計データ(性別、民族など)の分布を分析し、不公平な結果につながる可能性のある潜在的な不均衡や相関関係を特定します。これにより、データサイエンスチームはモデルのトレーニング前にバイアスを特定し、軽減するための視覚化と統計レポートを得ることができます。この積極的なステップは、公正な採用慣行を促進する、責任ある倫理的なAIシステムを開発するために不可欠です。