Pylar
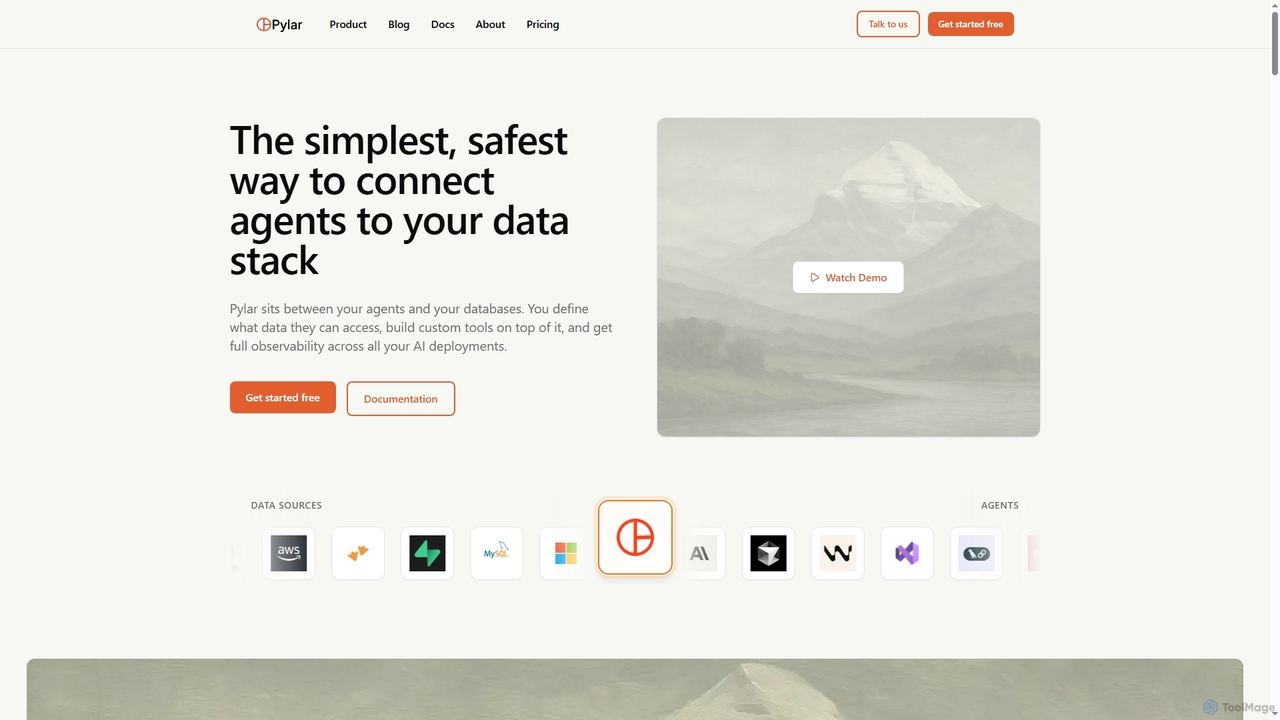
Pylarは、AIエージェントをデータスタックに安全に接続するデータガバナンスプラットフォームです。SQLビューを通じて安全なデータアクセスを定義し、エージェント用のカスタムツールを構築し、すべての対話を監視することで、直接的なデータベースアクセスを防ぎ、セキュリティと制御を確保します。
Pylarは、AIエージェントをデータスタックに安全に接続するデータガバナンスプラットフォームです。SQLビューを通じて安全なデータアクセスを定義し、エージェント用のカスタムツールを構築し、すべての対話を監視することで、直接的なデータベースアクセスを防ぎ、セキュリティと制御を確保します。
データガバナンスについて
データガバナンスツールは、AIシステム内で利用されるデータの品質、コンプライアンス、および利用可能性を管理、保護、保証するために設計されたAIを活用したソリューションです。AIインフラストラクチャの重要なコンポーネントとして、これらのツールは、収集からデプロイメントまで、AI関連データのライフサイクル全体を監督するためのフレームワークとプロセスを確立します。データの整合性を維持し、リスクを軽減し、規制基準を遵守することで、組織が信頼できる倫理的なAIアプリケーションを構築できるようにします。
コア機能
- データ品質管理: AIモデルトレーニングのデータ精度と一貫性を確保するために、データを自動的に識別、クレンジング、検証します。
- AIデータリネージ追跡: 透明性と説明可能性のために、AIパイプライン内のデータの起源、変換、使用状況の包括的な監査証跡を提供します。
- コンプライアンスとプライバシーの強制: GDPR、CCPAなどの規制および内部倫理ガイドラインにAIデータ処理が準拠していることを保証するポリシーを実装します。
- アクセス制御とセキュリティ: 機密性の高いAIトレーニングデータセットに対する詳細なアクセス許可を管理し、不正アクセスやデータ侵害を防ぎます。
- AI向けメタデータ管理: AI固有のデータ資産をカタログ化および分類し、データサイエンティストと開発者の発見可能性と理解を向上させます。
適用シナリオ
データガバナンスツールは、AIを開発およびデプロイする企業にとって不可欠であり、モデルが信頼できる準拠データに基づいて構築されていることを保証します。データサイエンティストはデータの整合性を検証するために、コンプライアンス担当者は規制遵守のためにAIシステムを監査するために、MLOpsチームは本番パイプラインでのデータ品質チェックを自動化するためにこれらを使用します。これらのツールは、倫理的で透明性があり、法的に準拠したAIソリューションを構築しようとするあらゆる組織にとって不可欠です。
選択のポイント
AI向けデータガバナンスツールを選択する際には、既存のAI/MLプラットフォームおよびデータパイプラインとの堅牢な統合を提供するソリューションを優先してください。自動データ品質、包括的なデータリネージ追跡、およびAI固有の規制に合わせた強力なコンプライアンス機能について評価します。増大するデータ量を処理するためのスケーラビリティ、およびポリシーの強制と監査のために提供される自動化のレベルを考慮してください。データスチュワードの使いやすさと明確なレポート機能も、効果的な実装にとって重要です。
データガバナンス利用シーン
バイアスのないAIトレーニングデータの確保
データサイエンティストは、AIデータガバナンスツールを使用して、大規模なトレーニングデータセットに隠されたバイアスや過少表現を綿密に監査します。人口統計学的分布や特徴の相関関係を分析することで、これらのツールはモデル展開前にデータ駆動型のバイアスを特定し軽減するのに役立ち、特に融資や採用などの機密性の高いアプリケーションにおいて、より公平で公正なAI結果を保証します。
AIモデルトレーニングデータのコンプライアンス確保
データサイエンティストとコンプライアンス担当者は、データガバナンスツールを使用して、AIモデルのトレーニングに利用されるすべてのデータ、特に個人識別情報(PII)を扱うデータが、GDPRやCCPAなどの厳格なプライバシー規制に準拠していることを確認します。このツールは、データの同意、匿名化ステータス、使用制限を追跡し、モデルに投入される前に非準拠データセットを自動的にフラグ付けすることで、法的および倫理的リスクを軽減します。
AIモデルのデータコンプライアンスの自動化
法務およびコンプライアンスチームは、データガバナンスプラットフォームを活用して、AIモデル内の個人データおよび機密データの使用状況を追跡および文書化します。これらのツールは、データアクセス、処理、保持を監視することで、データプライバシー規制(GDPR、CCPAなど)の施行を自動化し、法的リスクを低減し、倫理的なAI開発と展開を保証します。
AIパイプラインにおけるデータ品質チェックの自動化
MLOpsエンジニアは、データガバナンスソリューションを導入して、本番AIシステムに流入するデータの品質を継続的に監視します。これらのツールは、異常、欠損値、スキーマドリフトをリアルタイムで自動的に検出し、破損または不整合なデータがモデルのパフォーマンスに影響を与えるのを防ぎます。このプロアクティブなアプローチにより、AIモデルが高品質の入力で動作し、予測の精度と信頼性が維持されます。
AIモデルのデータリネージ管理
MLOpsエンジニアとデータ監査担当者は、データガバナンスソリューションに依存して、本番環境にあるすべてのAIモデルの明確なデータリネージを確立します。これには、すべてのデータ入力の起源、変換、バージョンを追跡することが含まれ、モデルエラーの迅速なデバッグ、規制監査の促進、およびデータがモデル予測にどのように影響するかについての透明性の提供を可能にします。
機密性の高いAIデータセットへのきめ細かなアクセス管理
データスチュワードは、データガバナンスプラットフォームを活用して、機密性の高いAIトレーニングデータセットに対するきめ細かなアクセス制御を定義し、強制します。例えば、不正検出モデルに取り組む特定のデータサイエンティストのみが匿名化されたトランザクションデータにアクセスでき、他のユーザーは制限されます。これにより、データセキュリティが確保され、不正なデータ露出が防止され、重要なAIアプリケーションに必要な機密性が維持されます。
機密AIデータに対するきめ細かなアクセス制御の実装
データスチュワードとセキュリティ担当者は、これらのツールを使用して、AI開発向けの機密データセットに対するきめ細かなアクセスポリシーを定義し、適用します。これにより、承認された担当者とプロセスのみが機密情報にアクセスまたは変更できるようになり、データ侵害を防止し、AIワークフロー内の専有データまたは個人データの機密性を維持します。
AIの解釈可能性と監査のためのデータリネージ確立
AI監査担当者と研究者は、データガバナンスツールを使用して、AIモデルで使用されるデータの完全なリネージを、そのソースシステムからすべての変換ステップを経てモデルトレーニングでの最終的な使用まで追跡します。この機能は、特定のデータポイントがモデルの決定にどのように影響するかを理解し、説明可能なAI(XAI)要件を満たし、規制機関や内部レビューのための透明な監査証跡を提供するために不可欠です。
リアルタイムAI推論のためのデータ品質監視
運用チームは、データガバナンスプラットフォームを導入して、リアルタイムAI推論エンジンに供給されるデータストリームの品質と整合性を継続的に監視します。ライブデータ内の異常、ドリフト、または破損を検出することで、これらのツールは、入力品質の低下によるAIモデルの不正確な予測を防ぎ、重要なAIアプリケーションの信頼性とパフォーマンスを保証します。
AI開発における倫理的なデータ利用ポリシーの施行
エンタープライズアーキテクトと倫理委員会は、データガバナンスフレームワークを実装して、AIプロジェクトにおけるデータ収集と利用に関する倫理ガイドラインを法典化し、施行します。例えば、顔認識に使用されるデータが明示的な同意を得て収集され、差別的な目的で使用されないようにします。これらのツールは、倫理原則を実行可能なデータポリシーに変換し、責任あるAI開発を促進します。
説明可能なAI(XAI)データ監査の促進
研究者や監査担当者は、データガバナンスツールを使用して、特定のAIモデルの決定に関連するデータ入力と前処理ステップを綿密に文書化します。この機能は説明可能なAI(XAI)にとって不可欠であり、利害関係者が特定の結果に最も貢献したデータポイントを理解できるようにすることで、複雑なAIシステムの信頼性と説明責任を高めます。
AI資産のデータ保持とアーカイブの効率化
ITマネージャーとデータライフサイクルスペシャリストは、データガバナンスツールを使用して、履歴AIトレーニングデータセットとモデル成果物の保持、アーカイブ、削除ポリシーを自動化します。これにより、データ保持法への準拠が確保され、不要なデータを削除することでストレージコストが最適化され、将来の参照や規制遵守のために、クリーンで整理されたAI資産のリポジトリが維持されます。