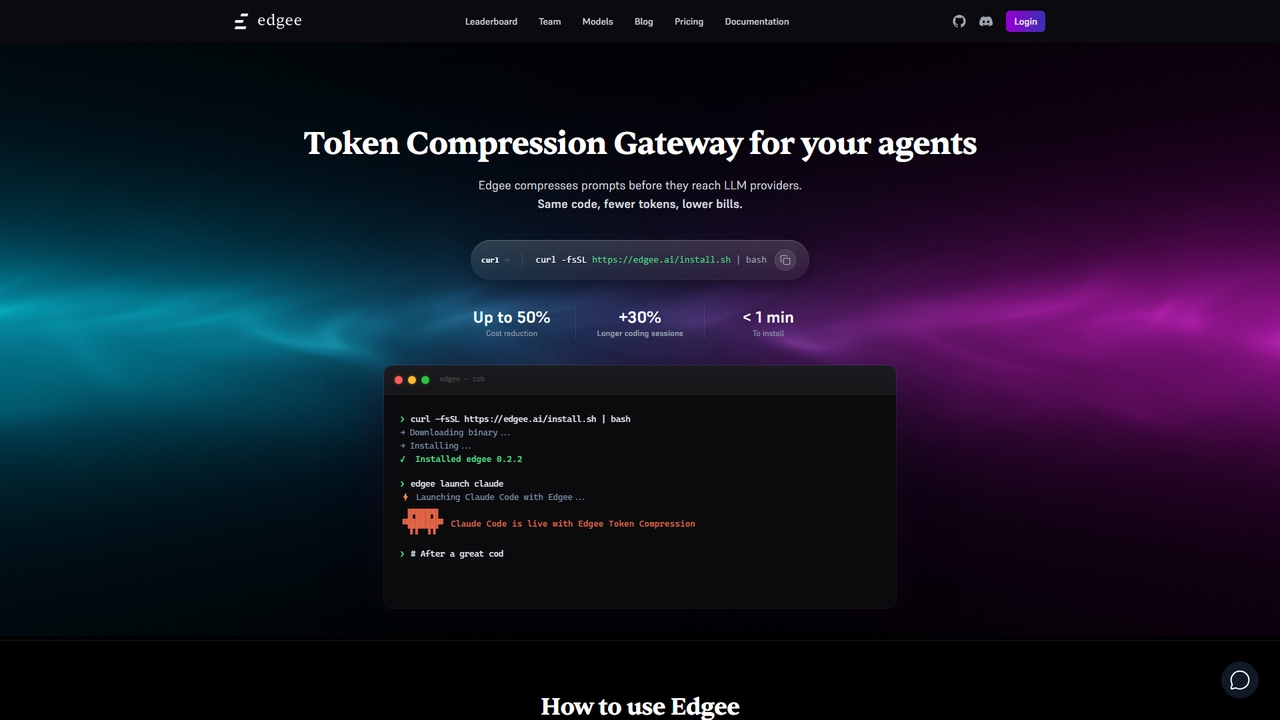
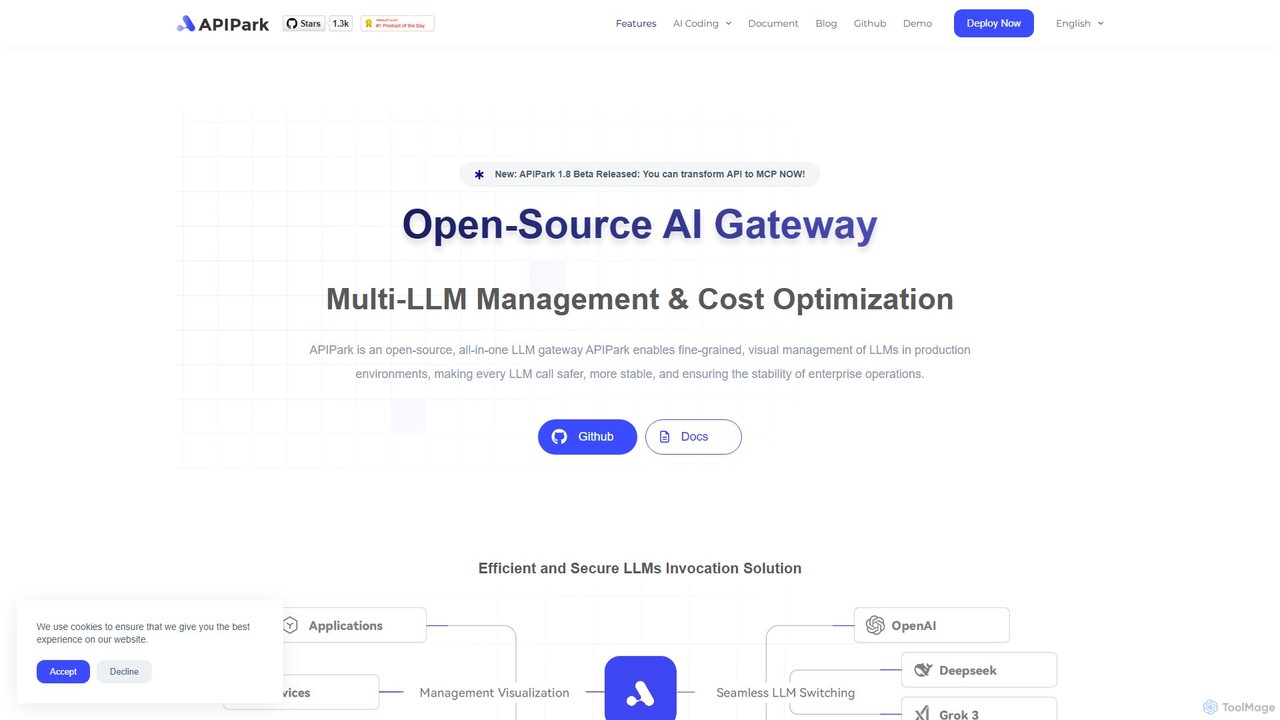
LLMゲートウェイについて
LLMゲートウェイは、複数の大規模言語モデル(LLM)へのアクセスを管理し、合理化するための専門的なミドルウェアツールです。アプリケーションとOpenAI、Anthropic、Googleなどの様々なLLMプロバイダーの間に位置する統一APIレイヤーとして機能します。この一元管理により、開発者は単一のモデルエコシステムに縛られることなく、リクエストのルーティング、APIキーの管理、使用状況の監視が可能になります。AIインフラストラクチャの重要な部分として、LLMゲートウェイはスケーラブルでコスト効率が高く、回復力のあるAI搭載アプリケーションを構築するために不可欠です。
主な機能
- 統一APIエンドポイント:単一の一貫したインターフェースを通じて、複数のプロバイダーからの多様なLLMにアクセスします。
- インテリジェントなルーティングとフェイルオーバー:コスト、レイテンシー、可用性に基づいて最適なモデルにリクエストを自動的に振り分け、シームレスなフェイルオーバーを実現します。
- コスト管理と制御:トークンの使用状況をリアルタイムで追跡し、予算を設定し、レート制限を適用して予期せぬ費用を防ぎます。
- パフォーマンスキャッシング:頻繁なクエリへの応答を保存・再利用し、レイテンシーを削減し、冗長なAPIコールを最小限に抑えます。
- 一元的な可観測性:すべてのLLMインタラクションからのログ、メトリクス、トレースを統合し、監視とデバッグを簡素化します。
適用シーン
LLMゲートウェイは、AIネイティブ製品を構築するテクノロジー企業、既存のワークフローに生成AIを統合する企業、モデルの柔軟性を必要とする開発チームによって広く使用されています。特に、マルチクラウドまたはマルチモデル戦略の管理、運用コストの最適化、アプリケーションの信頼性確保のために、本番環境で価値を発揮します。
選択のポイント
LLMゲートウェイを選択する際は、サポートされているLLMプロバイダーの範囲、デプロイメントオプション(クラウド対セルフホスト)、ルーティングおよびキャッシング規則の高度さ、既存の可観測性スタック(ロギングや監視ツールなど)との統合能力を考慮してください。また、セキュリティ機能とゲートウェイが導入するレイテンシーのオーバーヘッドも評価する必要があります。
LLMゲートウェイ利用シーン
エンタープライズ向けマルチモデルAI統合
企業の開発チームは、CRMやナレッジベースなど、複数の社内アプリケーションに生成AI機能を統合する必要があります。各LLMプロバイダーに対して個別の統合を構築する代わりに、LLMゲートウェイを導入します。これにより、すべてのアプリケーションに対して単一の安全なエンドポイントが提供されます。ゲートウェイは、機密データクエリを自己ホスト型のプライベートモデルにルーティングし、一般的なコンテンツ作成タスクは最も費用対効果の高い商用モデルに送信するように構成されています。このアプローチにより、メンテナンスが簡素化され、セキュリティポリシーが一元的に適用され、ベンダーロックインが回避されます。
SaaSアプリケーションのコスト管理
あるSaaS企業は、異なる価格帯の顧客にAIを活用したコンテンツ要約機能を提供しています。運用コストを管理するために、LLMゲートウェイを使用しています。ゲートウェイは、各顧客のサブスクリプションプランに基づいて、厳格な月間トークン制限を適用します。また、使用パターンに関する詳細な分析を提供し、製品チームが機能ごとのコストを理解し、価格を調整するのに役立ちます。さらに、無料プランのユーザーからのリクエストを、より安価で若干性能の低いモデルにルーティングするルールを設定し、有料顧客のためにプレミアムモデルを確保します。
モデルのフェイルオーバーによる高可用性の確保
あるカスタマーサービスプラットフォームは、24時間365日利用可能でなければならないAIチャットボットに依存しています。LLMプロバイダーの障害やパフォーマンス低下によるダウンタイムを防ぐため、DevOpsチームはLLMゲートウェイを導入します。彼らはすべてのリクエストに対してプライマリモデルを設定しますが、バックアップとして別のプロバイダーのセカンダリモデルを設定します。ゲートウェイはプライマリモデルの健全性とレイテンシーを継続的に監視します。問題が検出されると、プライマリサービスが復旧するまで、すべてのトラフィックを自動的かつシームレスにバックアップモデルに再ルーティングし、エンドユーザーへの途切れないサービスを保証します。
最適なパフォーマンスのためのLLMのA/Bテスト
ある製品チームは、新しくファインチューニングされたオープンソースモデルが、現在の商用LLMよりも特定のユースケースで優れた結果を提供するかどうかを判断したいと考えています。LLMゲートウェイを使用して、A/Bテストを設定します。ゲートウェイは、ユーザートラフィックの10%を新しいモデルにルーティングし、残りの90%は既存のモデルを使用し続けるように構成されています。ゲートウェイの一元化されたロギングを通じて、チームは両方のモデルの応答品質(ユーザーフィードバック経由)、レイテンシー、クエリごとのコストなどの主要なメトリクスを簡単に比較できます。このデータ駆動型のアプローチにより、ユーザーエクスペリエンスを妨げることなく、情報に基づいた意思決定を行うことができます。
一元化されたプロンプト管理とバージョニング
開発者とプロンプトエンジニアの大規模なチームが、数十のAI駆動機能を備えたアプリケーションに取り組んでいます。アプリケーションコード内で直接プロンプトを管理および更新するのは時間がかかり、エラーが発生しやすくなります。彼らはプロンプト管理システムを含むLLMゲートウェイを採用します。これにより、中央のダッシュボードからプロンプトテンプレートを保存、バージョン管理、デプロイできます。プロンプトを改善する必要がある場合、プロンプトエンジニアはゲートウェイのUIで更新でき、その変更は新しいコードのデプロイを必要とせずにアプリケーションに即座に反映されます。これにより、プロンプトエンジニアリングがソフトウェア開発ライフサイクルから切り離されます。
パフォーマンス向上のためのセマンティックキャッシングの実装
ある金融ニュース分析プラットフォームは、速報ニュース記事を要約するために、LLMに対して頻繁に類似のAPIコールを行います。レイテンシーを削減し、コストを削減するために、セマンティックキャッシング機能を備えたLLMゲートウェイを使用します。新しい記事を要約するリクエストが来ると、ゲートウェイはまずキャッシュ内で意味的に類似したリクエストをチェックします。十分に類似した要約が既に存在する場合、キャッシュされた応答を即座に返し、LLMへの高価なコールを回避します。これにより、人気のニュース記事を閲覧するユーザーの応答時間が大幅に改善され、全体のAPI支出が40%以上削減されます。