
The Foundry AI
The Foundry AIは、AIウェブエージェントを構築する開発者向けの専門プラットフォームです。決定論的なウェブシミュレータと高度なアノテーションフレームワークを提供し、ライブウェブの予測不可能性から解放された、再現可能な環境でエージェントのテスト、ベンチマーク、デバッグを可能にします。
The Foundry AIは、AIウェブエージェントを構築する開発者向けの専門プラットフォームです。決定論的なウェブシミュレータと高度なアノテーションフレームワークを提供し、ライブウェブの予測不可能性から解放された、再現可能な環境でエージェントのテスト、ベンチマーク、デバッグを可能にします。
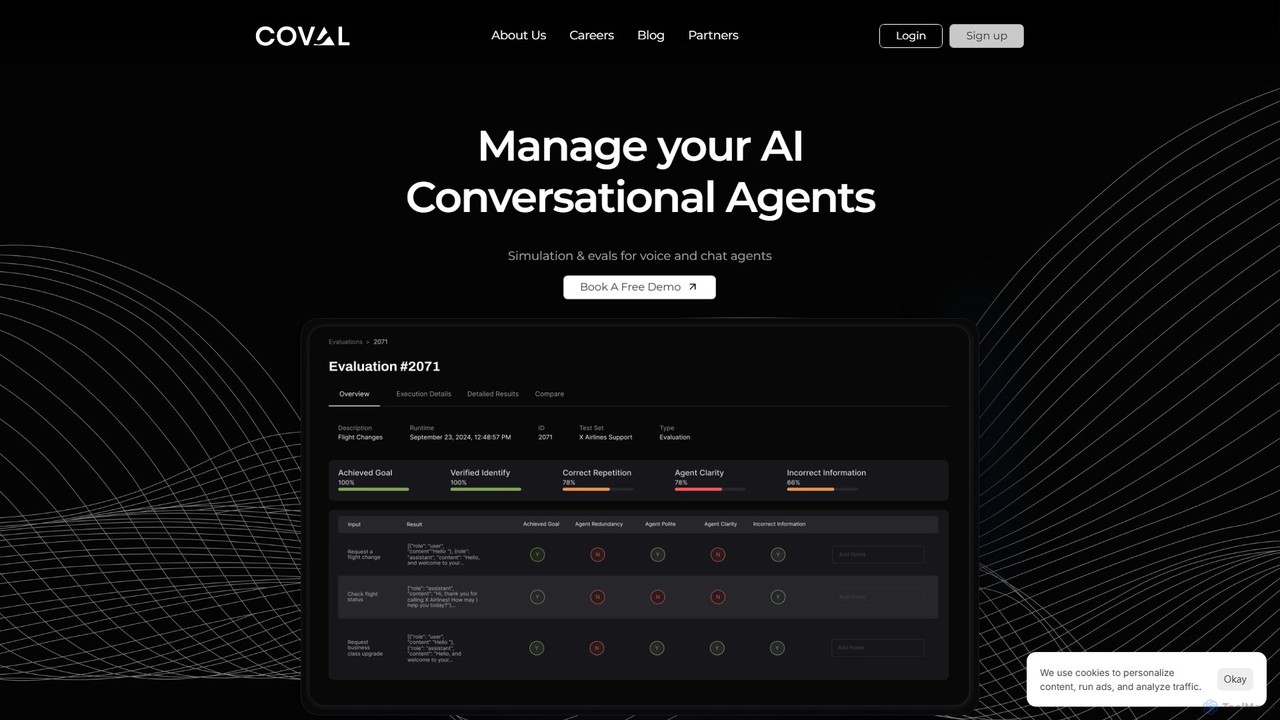
Coval
Covalは、会話型AIエージェントをシミュレーションおよび評価するための高度なプラットフォームです。Waymoの専門家によって構築され、開発者が音声およびチャットエージェントを大規模にテストし、信頼性とパフォーマンスを確保するのに役立ちます。何千ものシナリオをシミュレーションしてテストを自動化し、詳細なパフォーマンスメトリクスを提供し、本番環境のモニタリングでリグレッションを検出し、エージェントの動作を最適化します。
Covalは、会話型AIエージェントをシミュレーションおよび評価するための高度なプラットフォームです。Waymoの専門家によって構築され、開発者が音声およびチャットエージェントを大規模にテストし、信頼性とパフォーマンスを確保するのに役立ちます。何千ものシナリオをシミュレーションしてテストを自動化し、詳細なパフォーマンスメトリクスを提供し、本番環境のモニタリングでリグレッションを検出し、エージェントの動作を最適化します。
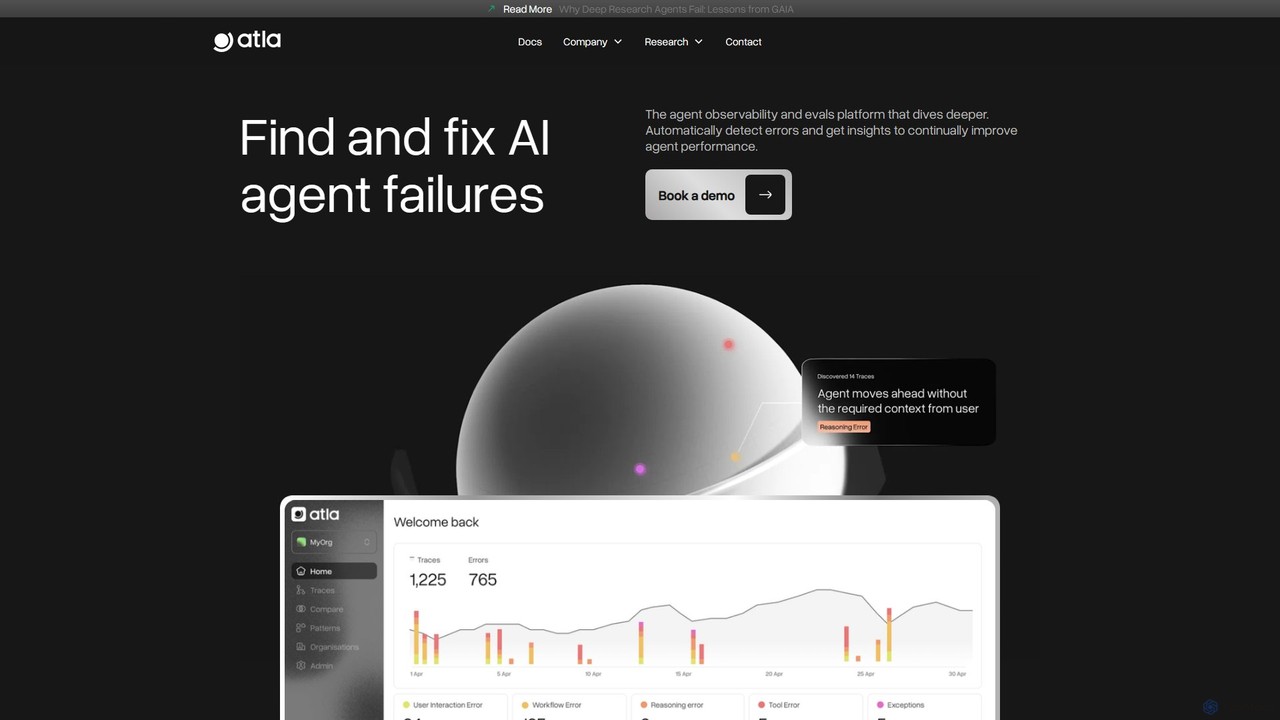
Atla AI
Atla AIは、AIエージェント向けに設計されたオブザーバビリティ(可観測性)および評価プラットフォームです。エージェントの振る舞いに関する深い洞察を提供し、開発者がエージェントの障害を発見、理解、修正するのを支援します。このプラットフォームは、エラーを自動検出し、繰り返し発生するパターンを特定し、エージェントのパフォーマンスと完了率を継続的に向上させるための実用的な提案を行います。
Atla AIは、AIエージェント向けに設計されたオブザーバビリティ(可観測性)および評価プラットフォームです。エージェントの振る舞いに関する深い洞察を提供し、開発者がエージェントの障害を発見、理解、修正するのを支援します。このプラットフォームは、エラーを自動検出し、繰り返し発生するパターンを特定し、エージェントのパフォーマンスと完了率を継続的に向上させるための実用的な提案を行います。
モデル評価について
モデル評価ツールは、機械学習モデルのパフォーマンス、公平性、信頼性を体系的に評価するために設計された、AIインフラストラクチャの専門的なカテゴリです。これらのプラットフォームは、精度、適合率、再現率などの主要なメトリクスの計算を自動化し、バイアス検出、説明可能性分析、堅牢性テストなどの高度な機能も提供します。その主な価値は、開発者が最高のパフォーマンスを発揮するモデルを選択し、倫理的なAIプラクティスを確保し、本番環境へのモデルの準備が整っていることを検証するのに役立つ、客観的でデータ駆動型の洞察を提供することにあります。この厳格な評価はMLOpsライフサイクルの重要なステップであり、展開されたモデルが効果的で信頼性が高く、ビジネス目標に沿っていることを保証します。
主な機能
- パフォーマンスメトリクスの追跡:分類(精度、F1スコア、AUC)および回帰(MSE、MAE、R²)の標準メトリクスを自動的に計算し、視覚化します。
- バイアスと公平性の監査:異なる人口統計サブグループ間のパフォーマンスの格差を特定し、モデルの予測における潜在的なバイアスを検出および緩和します。
- 説明可能性(XAI)分析:SHAPやLIMEなどの技術を使用してモデルの決定に関する洞察を生成し、ブラックボックスモデルの透明性を高めます。
- 堅牢性とストレステスト:敵対的攻撃、データドリフト、エッジケースに対するモデルの安定性を評価し、実世界での信頼性の高いパフォーマンスを保証します。
- モデルの比較とバージョン管理:標準化されたデータセット上で複数のモデルまたは同じモデルの異なるバージョンを並べて比較するためのフレームワークを提供します。
利用シーン
モデル評価ツールは、データサイエンティスト、機械学習エンジニア、MLOpsチームにとって不可欠であり、特に金融、ヘルスケア、保険などの規制の厳しい業界で重要です。開発サイクル中に候補モデルのベンチマークと比較選択に使用され、展開前のチェックでコンプライアンスと公平性を検証し、稼働中のモデルの定期的な監査で継続的なパフォーマンスと信頼性を確保するために使用されます。
選択のポイント
モデル評価ツールを選択する際は、お使いの機械学習フレームワーク(例:TensorFlow、PyTorch、Scikit-learn)との互換性を考慮してください。パフォーマンス、公平性、説明可能性をカバーしているかなど、機能の幅を評価します。実験トラッカーやモデルレジストリなど、既存のMLOpsスタックとの統合能力を評価します。最後に、技術者と非技術者の両方のステークホルダーに結果を伝えるための視覚化およびレポート機能の品質を検討してください。
モデル評価利用シーン
金融モデルの公平性監査
金融機関のデータサイエンティストは、新しい信用スコアリングモデルが保護された人口統計グループを差別しないようにする任務を負っています。モデル評価ツールを使用して、テストデータセットに対するモデルの予測をアップロードします。ツールは自動的に公平性レポートを生成し、異なる性別や民族における偽陽性率などのパフォーマンスメトリクスを強調表示します。これらの結果を分析することで、科学者はモデルが展開される前にバイアスを特定して緩和し、公正な貸付規制の遵守を確保し、評判リスクを低減することができます。
コンピュータビジョンモデルのアーキテクチャ比較
機械学習エンジニアがモバイルアプリ向けの画像分類機能を開発しており、3つの異なるモデルアーキテクチャ(例:ResNet、MobileNet、Vision Transformer)から選択する必要があります。彼はモデル評価プラットフォームを使用して、同じ検証データセットで3つのモデルすべてを実行します。プラットフォームは、各モデルの精度、F1スコア、推論レイテンシ、モデルサイズを示すサイドバイサイドの比較ダッシュボードを提供します。この包括的なビューにより、エンジニアはトレードオフの決定を下し、精度とオンデバイスパフォーマンスの最適なバランスを提供するモデルを選択できます。
医療診断のための説明生成
医療現場では、放射線科医が医療スキャン内の異常を検出するAIモデルを使用しています。信頼を築き、診断を支援するために、モデル評価ツール内の説明可能性(XAI)機能が使用されます。モデルが潜在的な問題をフラグ付けすると、ツールは元のスキャンに重ねてヒートマップ(SHAPやLIMEの視覚化など)を生成します。このヒートマップは、モデルの決定に最も影響を与えた特定のピクセルと領域を強調表示します。これにより、放射線科医はAIの推論を自身の専門知識と照らし合わせて迅速に検証でき、より自信を持った透明性の高い臨床判断につながります。
自動運転車両の知覚モデルのストレステスト
自動車エンジニアリングチームは、自動運転車両の知覚モデルが非常に信頼性が高いことを確認する必要があります。彼らはモデル評価ツールの堅牢性テストモジュールを使用して、悪条件下をシミュレートします。これには、テスト画像にプログラムでデジタルノイズ、霧、雨を追加し、モデルの死角を見つけるために敵対的攻撃を実行することが含まれます。ツールは、各条件下でモデルの精度がどれだけ低下するかを報告します。この厳格なストレステストは、チームが弱点を特定し、現実世界の課題に対してモデルを強化するのに役立ち、安全を確保するための重要なステップです。
カスタマーサポートチャットボット向けNLPモデルのベンチマーク
AIチャットボットのプロダクトマネージャーは、その基盤となる自然言語処理(NLP)モデルをアップグレードしたいと考えています。チームは2つの新しいモデルを最終候補に挙げました。モデル評価スイートを使用して、彼らは過去の顧客との会話の「ゴールデンデータセット」で、現在のモデルに対して両方の新しいモデルをベンチマークします。評価ツールは、意図認識の精度、エンティティ抽出のF1スコア、および応答の関連性を測定します。結果はリーダーボード形式で表示され、プロダクトマネージャーはどのモデルが特定のデータで最も優れたパフォーマンスを発揮するかを明確に確認し、アップグレードのための証拠に基づいた決定を下すことができます。
規制遵守のためのモデル挙動の検証
保険会社のコンプライアンスオフィサーは、自社の請求処理AIが公正かつ透明であることを規制当局に証明する必要があります。彼らはモデル評価プラットフォームを使用して包括的な監査を実施します。プラットフォームは、以下を含む詳細なレポートを生成します:
- 全体的なパフォーマンスメトリクス(例:不正検出の精度)。
- 年齢、性別、地域のサブグループにわたる公平性分析。
- 特定の請求拒否決定に対する事例ベースの説明(XAI)。