People For AI
People For AIは、機械学習プロジェクト向けに専門家主導のデータラベリングサービスを提供します。複雑な画像やテキストデータセットに対する高品質で安全なアノテーションを専門としています。クラウドソーシングの代わりに社内の長期契約ラベラーを使用することで、優れた精度、柔軟性、データセキュリティを保証します。自動運転車、顕微鏡、小売、インフラなど、さまざまな業界に対応し、信頼性の高いトレーニングデータを提供して企業のAI開発を加速させます。
People For AIは、機械学習プロジェクト向けに専門家主導のデータラベリングサービスを提供します。複雑な画像やテキストデータセットに対する高品質で安全なアノテーションを専門としています。クラウドソーシングの代わりに社内の長期契約ラベラーを使用することで、優れた精度、柔軟性、データセキュリティを保証します。自動運転車、顕微鏡、小売、インフラなど、さまざまな業界に対応し、信頼性の高いトレーニングデータを提供して企業のAI開発を加速させます。
訓練データについて
訓練データツールは、人工知能モデルのトレーニング用に高品質なデータセットを作成、管理、調達するために設計されたプラットフォームです。AIインフラストラクチャの基本的な構成要素として、これらのツールは機械学習アルゴリズムがパターンを学習し、正確な予測を行うために必要な構造化情報を提供します。モデルのパフォーマンス向上、バイアスの削減、AIアプリケーションの開発ライフサイクルの加速に不可欠です。主な機能は、データのアノテーションやラベリングから、合成データ生成、品質保証まで多岐にわたります。
主な機能
- データアノテーションとラベリング:バウンディングボックス、セマンティックセグメンテーション、エンティティタギングなどの技術を用いて、画像、テキスト、音声、ビデオなど様々なデータタイプに正確なラベルを付けるための直感的なインターフェースを提供します。
- 合成データ生成:人工的でありながら現実的なデータを作成し、実世界のデータセットを補完または代替することで、データの希少性、プライバシー、エッジケースの問題を克服します。
- データセット管理:データセットのバージョン管理、検索、追跡を行うための一元化されたプラットフォームを提供し、機械学習チーム間でのトレーサビリティとコラボレーションを確保します。
- 品質保証ワークフロー:レビュー、コンセンサススコアリング、エラー検出などの機能を含み、ラベルの精度とデータの一貫性の高い基準を維持します。
適用シナリオ
これらのツールは、カスタムAIモデルに依存する業界で非常に重要です。例えば、自動車セクターでは注釈付きの道路シーンで自動運転車をトレーニングするために、医療分野ではラベル付けされた医療画像から診断モデルを開発するために、小売業界ではユーザー行動データに基づいて製品推薦エンジンを構築するために使用されます。
選択のポイント
訓練データツールを選択する際は、扱う特定のデータタイプ(例:ビデオ、3D点群)を考慮してください。アノテーションインターフェースの品質と効率、大規模データセットに対応するプラットフォームのスケーラビリティ、既存のMLOpsパイプラインとの統合能力を評価します。また、コラボレーション機能や品質管理メカニズムも評価することが重要です。
訓練データ利用シーン
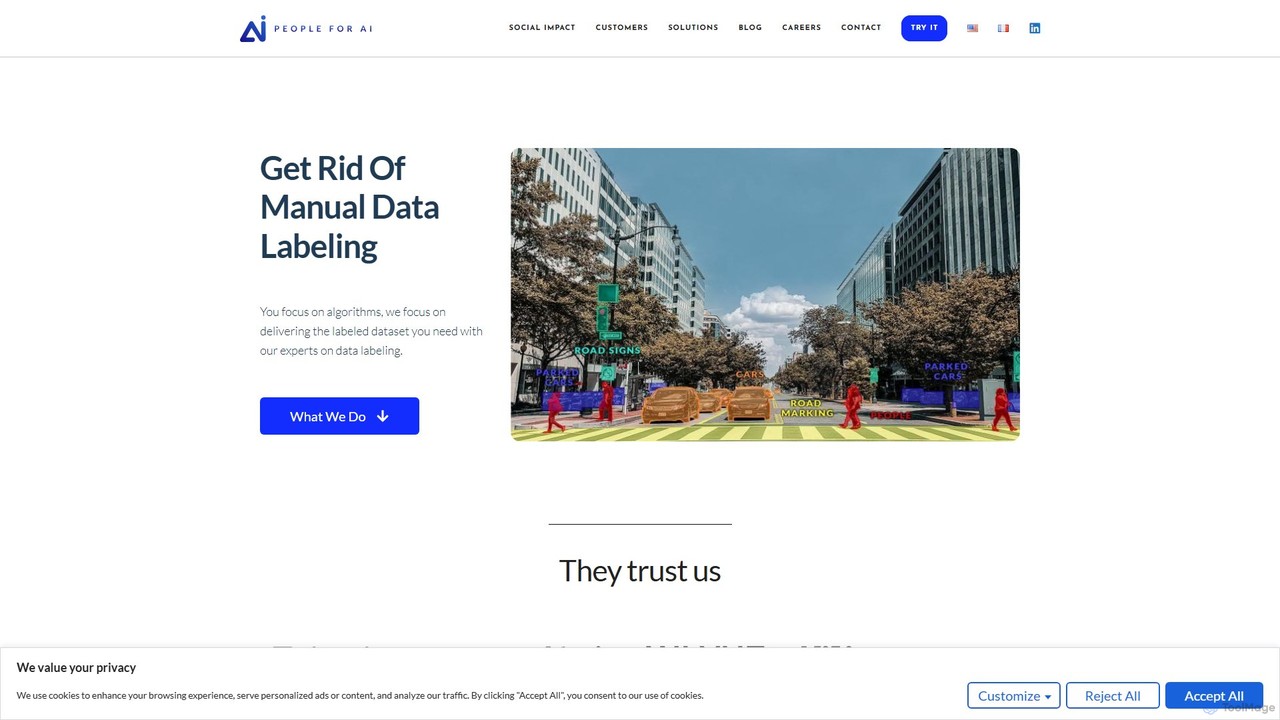
自動運転のための道路シーンのアノテーション
自動車技術企業のMLエンジニアは、自動運転車の知覚モデルを改善する任務を負っています。訓練データプラットフォームを使用して、彼らのチームはテスト車両からの何千時間ものビデオ映像にアノテーションを付けます。セマンティックセグメンテーションツールを使用して道路、車線、歩道のすべてのピクセルをラベル付けし、物体検出のためにバウンディングボックスを使用して歩行者、車両、交通標識を識別します。この細心の注意を払ってラベル付けされたデータセットは、AIの訓練と検証に使用され、複雑な都市環境を安全に航行する能力を大幅に向上させます。
疾患検出のための医療画像のラベリング
ある医学研究チームは、CTスキャンからがんの初期兆候を検出するAIモデルを開発しています。タスクの重要性から、データの正確性が最優先されます。彼らはDICOM画像形式をサポートし、高精度の注釈ツールを提供する専門の訓練データプラットフォームを使用します。放射線科医がプラットフォーム上で協力して、潜在的な腫瘍の輪郭を描き、異常をラベル付けします。ピアレビューやコンセンサススコアリングなどのプラットフォームの品質保証機能により、最終的なデータセットの信頼性が非常に高くなり、より正確で信頼性の高い診断AIにつながります。
金融詐欺検出のための合成データの生成
あるフィンテック企業は、より堅牢な詐欺検出モデルを構築したいと考えていますが、実際の顧客取引データの使用を制限するプライバシー規制(GDPRなど)に制約されています。これを克服するため、彼らのデータサイエンスチームは合成データ生成ツールを使用します。このツールは、匿名化された実データの統計的特性を分析し、個人を特定できる情報を含まずに実世界のパターンを模倣した、新しいはるかに大規模な人工取引データセットを生成します。これにより、プライバシー法を完全に遵守しながら、多様で複雑な詐欺シナリオでモデルを訓練し、検出率を向上させることができます。
自然言語処理(NLP)のためのデータセットのキュレーション
ある会話型AIのスタートアップが次世代のチャットボットを構築しています。モデルがユーザーの意図を正確に理解するように訓練するため、彼らは大規模で多様な注釈付きテキストデータセットを必要としています。データプラットフォームを使用して、何千ものユーザーのクエリを収集し、アップロードします。その後、アノテーターのチームがプラットフォームのテキスト注釈ツールを使用して、各クエリに特定の意図(例:「残高確認」、「支払い」)をラベル付けし、エンティティ(例:日付、金額、名前)を識別してタグ付けします。プラットフォームのバージョン管理により、モデルの進化に合わせて変更を追跡し、複数のデータセットバージョンを管理でき、モデル改善への体系的なアプローチが保証されます。
商品タギングによるEコマース検索の改善
あるオンライン小売大手は、商品検索と推薦エンジンを強化することを目指しています。彼らのデータチームは、訓練データサービスを使用して、何百万もの商品画像に詳細な属性をラベル付けします。アノテーターは、カテゴリ(例:「婦人服」)、サブカテゴリ(「ドレス」)、スタイル(「ボヘミアン」)、特定の特徴(「花柄」、「Vネック」)などのタグを付けます。この構造化された高品質データは、新商品を自動的に分類し、より直感的な「画像検索」機能を強化するコンピュータビジョンモデルの訓練に使用され、より良い商品発見と売上増加につながります。
音声アシスタントの音声文字起こしによるトレーニング
あるテクノロジー企業が新しいスマートホーム音声アシスタントを開発しています。さまざまなアクセントやコマンドを理解できるようにするため、彼らは人々が話す何千もの音声クリップを収集します。データ注釈プラットフォームを使用して、言語学者の分散チームが音声をテキストに書き起こし、「ドアベル」や「犬の鳴き声」などの背景雑音にラベルを付けます。また、話者の感情や意図もタグ付けします。この豊富な音声データセットにより、エンジニアは現実世界の騒がしい家庭環境でうまく機能する堅牢な音声認識モデルを訓練でき、優れたユーザーエクスペリエンスを提供できます。