LLM Hub
LLM Hubは、5つの主要ベンダーから提供される20以上の大規模言語モデルの力を活用するために設計された、高度なマルチモデルAIオーケストレーションプラットフォームです。順次、並列、スペシャリスト、スマート(自動ルーティング)モードを通じて、ユーザーは様々なAIモデルを組み合わせ、連携させることで、複雑なタスクにおいてより深い分析と優れた結果を得ることができます。
LLM Hubは、5つの主要ベンダーから提供される20以上の大規模言語モデルの力を活用するために設計された、高度なマルチモデルAIオーケストレーションプラットフォームです。順次、並列、スペシャリスト、スマート(自動ルーティング)モードを通じて、ユーザーは様々なAIモデルを組み合わせ、連携させることで、複雑なタスクにおいてより深い分析と優れた結果を得ることができます。
マルチモデルについて
マルチモデルAIツールは、テキスト、画像、音声などの複数のデータタイプにわたる情報を同時に処理、理解、生成できるシステムの一種です。これらのツールは、統一されたアーキテクチャを活用して、異なるモダリティ間のコンテキストと関係を解釈し、単一機能のAIを超えます。これにより、画像を詳細に説明したり、テキストスクリプトからビデオを作成したりするなどの複雑なタスクを実行できます。AIオーケストレーションの主要コンポーネントとして、人間のような理解を模倣した洗練された複合メディアワークフローを処理するための強力なノードとして機能します。
主な機能
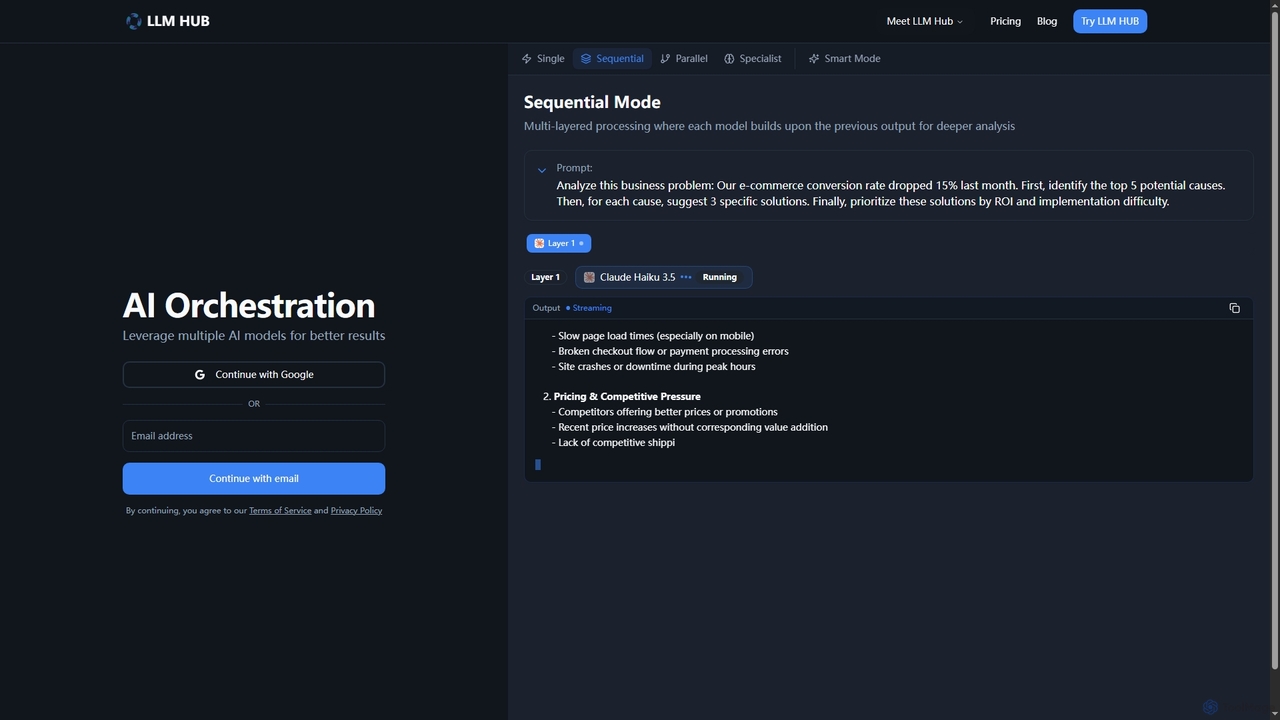
- クロスモーダル理解:テキスト記述を画像やビデオ内の特定コンテンツに一致させるなど、異なるソースからの情報を分析し、関連付けます。
- マルチ入力処理:テキスト、画像、音声、またはビデオの組み合わせを単一の一貫したプロンプトとして受け入れ、分析や生成をガイドします。
- 複合メディア生成:要約テキストと説明画像を両方含むレポートの生成など、異なるフォーマットを組み合わせた出力を作成します。
- 統一データ表現:内部的に様々なデータタイプを共通のセマンティックスペースに変換し、すべての入力にわたる包括的な推論と分析を可能にします。
利用シーン
マルチモデルツールは、メディア業界での自動ビデオ分析やコンテンツ要約、Eコマースでの画像からの商品説明生成、視覚障害者向けの視覚世界のリアルタイム記述を作成するアクセシビリティ開発などで広く使用されています。また、複雑なマルチフォーマットデータセットを分析する研究者にとっても不可欠です。
選択のポイント
マルチモデルツールを選択する際は、サポートする特定のモダリティ(テキスト、画像、音声、ビデオなど)を考慮してください。視覚的な質問応答やテキストから画像への生成など、ニーズに関連する主要なクロスモーダルタスクでのパフォーマンスを評価します。また、APIの統合の容易さ、大容量ファイルの処理速度、さまざまな入力タイプに関連するコスト構造も評価してください。
マルチモデル利用シーン
インテリジェントなビデオコンテンツ分析
メディアアナリストが2時間のドキュメンタリーの内容を迅速に理解する必要があります。彼らはビデオファイルをマルチモデルAIツールにアップロードします。AIは同時に、話されている対話(音声)を文字起こしし、主要なシーンとオブジェクト(ビデオ)を識別し、画面上のテキスト(画像)を認識します。その後、タイムスタンプ付きのトランスクリプト、視覚的なシーンの要約、および映画全体の簡潔なテキスト要約を生成します。このプロセスにより、手作業での記録時間が90%以上削減され、コンテンツが即座に検索可能になります。
Eコマースの商品リストの強化
Eコマースマネージャーが、新しい家具ラインのために充実した商品リストを作成したいと考えています。彼らは椅子の写真をさまざまな角度から数枚アップロードします。マルチモデルAIが画像を分析し、そのスタイル(「ミッドセンチュリーモダン」)、素材(「オーク材、リネン張り」)、特徴(「テーパー脚、ボタンタフトの背もたれ」)を特定します。この視覚的分析に基づいて、魅力的でSEOに配慮した商品説明と関連タグのリストを生成し、コンテンツ作成プロセスを合理化し、商品の発見可能性を向上させます。
インタラクティブな教材の作成
教育者が太陽系に関するデジタルレッスンを設計しています。彼らはマルチモデルツールにテキストプロンプトを提供します:「5年生向けの火星に関する5スライドのプレゼンテーションを作成し、主要な事実とクイズを含めてください。」 AIはテキストを処理し、各スライドの簡潔な説明を生成し、火星の表面や探査機の関連画像を見つけたり作成したりし、導入部分の短い音声ナレーションまで作成します。その結果、数時間ではなく数分で、豊かで多感覚的な学習モジュールが作成されます。
アクセシビリティ記述(代替テキスト)の自動化
ウェブコンテンツマネージャーは、大規模なニュースウェブサイトが視覚障害のあるユーザーにアクセス可能であることを保証する責任があります。彼らは新しい記事をスキャンするマルチモデルツールを使用します。各画像について、AIは視覚的なコンテンツだけでなく、周囲のテキスト(記事のタイトルやキャプション)も分析して文脈を理解します。そして、「白衣を着た科学者が地球温暖化を示すグラフを指している」といった、非常に説明的で文脈に関連した代替テキストを自動生成します。これは、一般的な「人物とグラフ」というタグよりもはるかに有用です。
高度な医療レポート支援
放射線科医が患者のX線写真(画像)をアップロードし、マイクに向かって初期所見(音声)を口述します。マルチモデルAIシステムが両方の入力を処理します。X線写真を分析して潜在的な異常を探し、同時に医師の口述メモと照合します。その後、システムは構造化された医療レポート(テキスト)を作成し、放射線科医が言及した懸念領域を強調表示し、標準的な専門用語を提案します。これにより、高度なアシスタントとして機能し、転記エラーを減らし、レポート作成のワークフローを高速化します。
エンジニアリングにおける複雑な問題解決
エンジニアが機械部品の技術図(画像)と、繰り返し発生する性能問題を詳述したテキストファイルをアップロードします。マルチモデルAIは、図面の視覚的構造を分析し、テキストで言及されているコンポーネントを特定し、記述された問題を図面上の特定の応力点や設計上の特徴と関連付けます。その後、「類似の設計における破壊パターンが示すように、ジョイントCでの振動応力」といった、故障の潜在的な原因を提案するレポートを生成し、トラブルシューティングのための貴重なセカンドオピニオンを提供します。