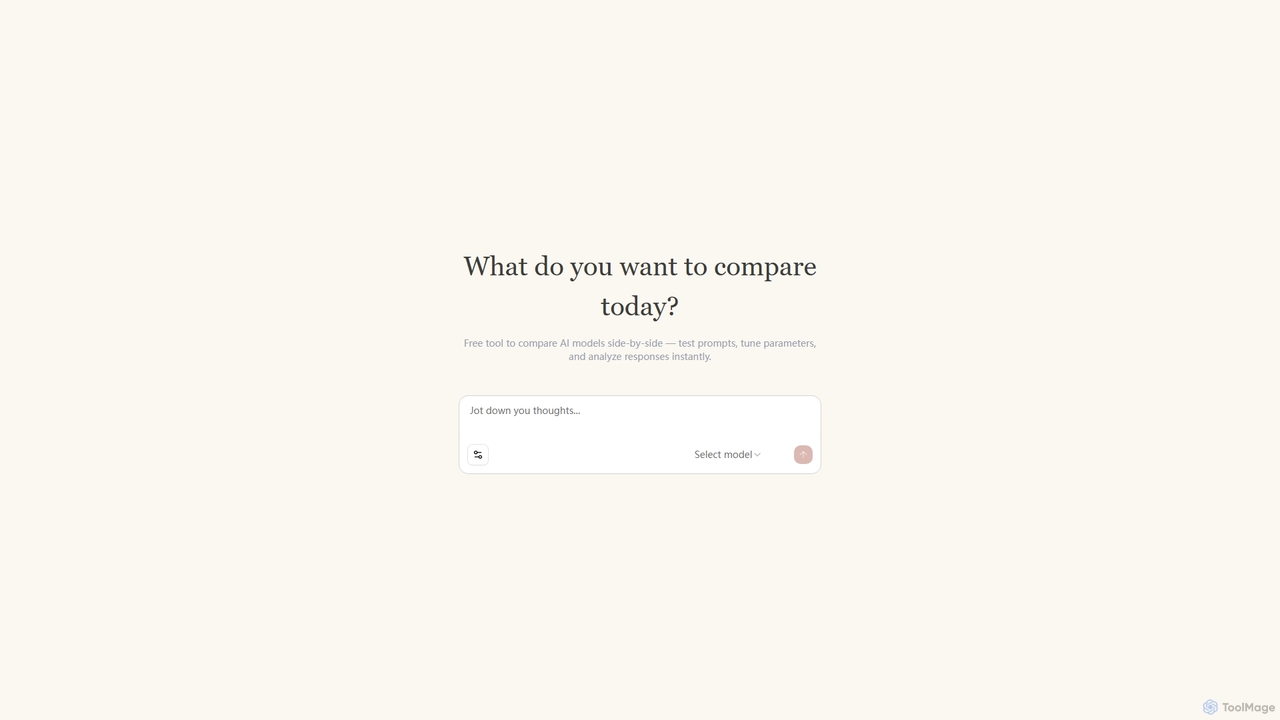
Llm Lab Three
開発者や研究者が大規模言語モデル(LLM)を並べて比較するための無料ツール。プロンプトをテストし、パラメータを調整し、応答を即座に分析して、あらゆるタスクに最適なモデルを見つけます。
開発者や研究者が大規模言語モデル(LLM)を並べて比較するための無料ツール。プロンプトをテストし、パラメータを調整し、応答を即座に分析して、あらゆるタスクに最適なモデルを見つけます。
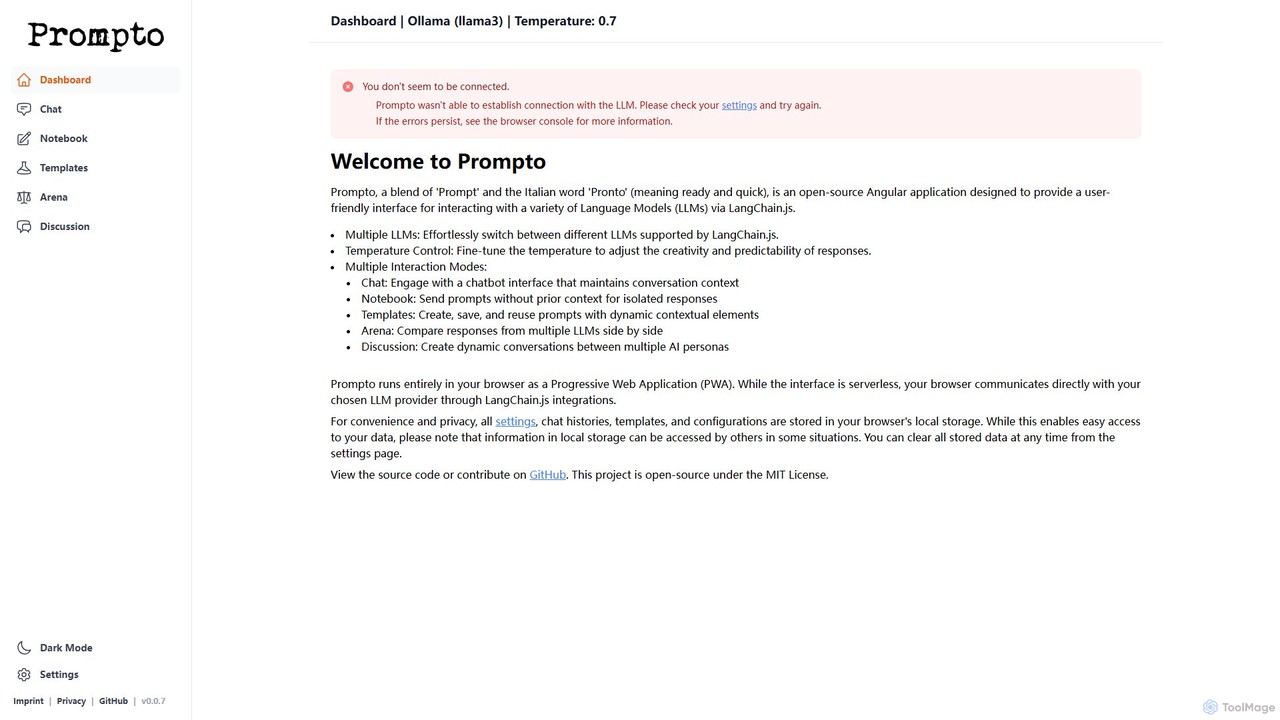
Prompto
Promptoは、さまざまな大規模言語モデル(LLM)と対話するための、無料のオープンソース・ブラウザベースのインターフェースです。LangChain.jsを活用してOpenAIやAnthropicなどのプロバイダー、Ollama経由のローカルモデルに直接接続し、モデル比較アリーナ、プロンプトテンプレート、マルチAIディスカッションなどの高度な機能を提供しつつ、データをローカルに保存することでユーザーのプライバシーを最優先します。
Promptoは、さまざまな大規模言語モデル(LLM)と対話するための、無料のオープンソース・ブラウザベースのインターフェースです。LangChain.jsを活用してOpenAIやAnthropicなどのプロバイダー、Ollama経由のローカルモデルに直接接続し、モデル比較アリーナ、プロンプトテンプレート、マルチAIディスカッションなどの高度な機能を提供しつつ、データをローカルに保存することでユーザーのプライバシーを最優先します。
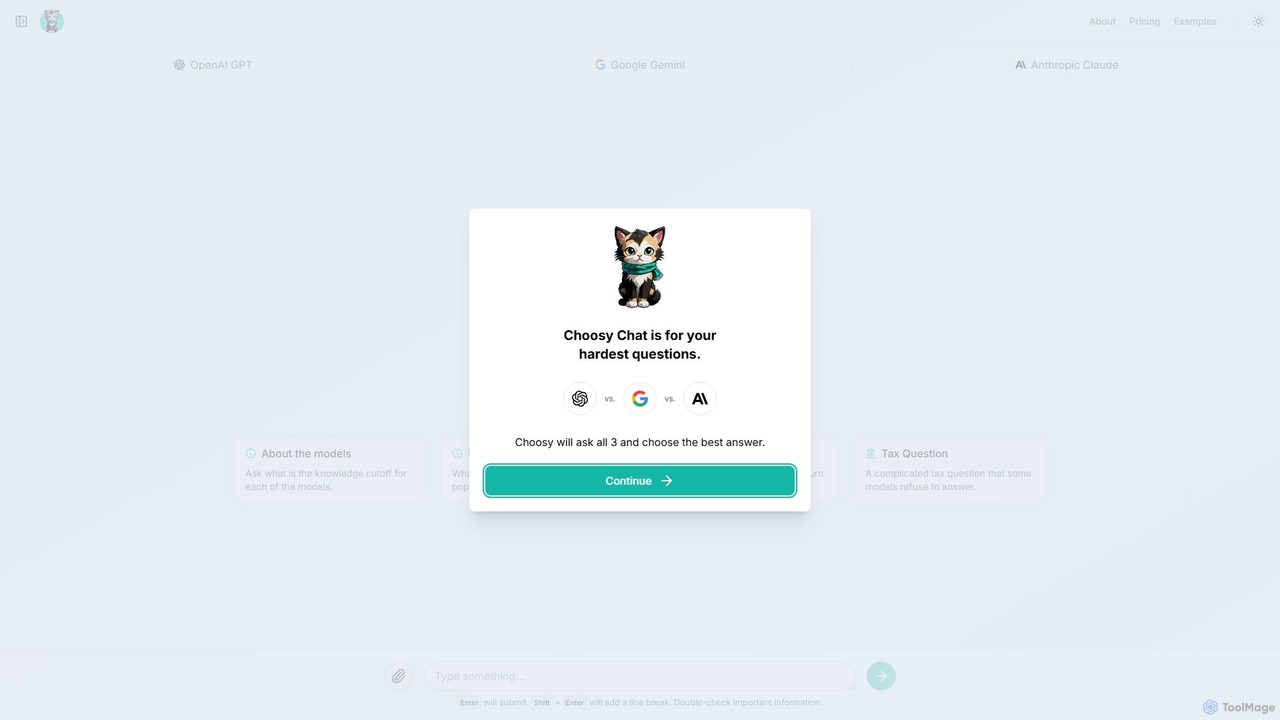
Choosy Chat
Choosy Chatは、あなたのプロンプトをGPT、Gemini、Claudeに同時に送信し、回答を並べて比較できるAIツールです。コーディングからクリエイティブな執筆まで、あらゆる質問に対して最適な回答を見つけるのに役立ちます。
Choosy Chatは、あなたのプロンプトをGPT、Gemini、Claudeに同時に送信し、回答を並べて比較できるAIツールです。コーディングからクリエイティブな執筆まで、あらゆる質問に対して最適な回答を見つけるのに役立ちます。
モデル比較について
モデル比較ツールは、異なるAIモデルのパフォーマンスを並べて評価し、ベンチマークするための専門的なプラットフォームです。これらのツールは、標準化されたデータセット、カスタムプロンプト、および精度、速度、コストなどの主要なパフォーマンス指標を使用してモデルをテストするための構造化された環境を提供します。開発者、研究者、企業が特定のアプリケーションに最適なAIモデルを選択する際に、データに基づいた意思決定を行うために不可欠です。これにより、マーケティングの主張を超えた客観的な分析が可能になり、最適なパフォーマンスとコスト効率が保証されます。
主な機能
- サイドバイサイドインターフェース:同じプロンプトに対するモデルの出力を統一されたビューで直接比較します。
- 自動ベンチマーキング:標準化されたテスト(例:MMLU、HellaSwag)を実行して、客観的なパフォーマンスを測定します。
- コストとレイテンシー分析:APIコストと応答時間を追跡し、異なるモデルの効率を評価します。
- 定性的リーダーボード:人間の好みと品質に基づいたクラウドソーシングまたは専門家主導のランキングにアクセスします。
- カスタムテストスイート:独自のデータセットとプロンプトをアップロードして、ドメイン固有のタスクでモデルを評価します。
適用シーン
これらのツールは、新しいアプリケーションの基盤モデルを選択するAI開発者、モデルの劣化を監視するMLOpsチーム、OpenAI、Anthropic、Googleなどのプロバイダーのコストパフォーマンス比を比較するプロダクトマネージャーに広く使用されています。研究者はまた、確立されたベンチマークに対して新しいモデルのパフォーマンスを検証するために使用します。
選択のポイント
ツールを選択する際は、サポートされているモデルの範囲(オープンソース対プロプライエタリ)、利用可能な評価指標とベンチマーク、テストにカスタムデータを使用できるかどうか、そして使いやすいUI、自動化のためのAPI、またはその両方が必要かどうかを考慮してください。また、テスト量に合った価格設定モデルを評価することも重要です。
モデル比較利用シーン
カスタマーサービスチャットボット用のLLM選定
Eコマース企業のプロダクトマネージャーが、新しいAIチャットボット用の大規模言語モデル(LLM)を選ぶ必要があります。モデル比較ツールを使用して、100件の一般的な顧客からの問い合わせを含むテストスイートを作成します。このスイートをGPT-4、Claude 3、Llama 3などのモデルで実行し、応答の正確性、丁寧さ、レイテンシー、1,000クエリあたりのコストを比較します。プラットフォームのサイドバイサイドビューにより、特定のユースケースにおいてClaude 3が品質とコストの最適なバランスを提供していることが明らかになり、数週間の手動テストの代わりに数時間でデータに基づいた意思決定が可能になります。
ファインチューニングされたオープンソースモデルのベンチマーク
MLエンジニアリングチームが、社内のナレッジベースでLlama 3モデルをファインチューニングしました。その有効性を検証するため、モデル比較プラットフォームを使用して、ベースのLlama 3モデルおよびGPT-4と比較ベンチマークを行います。一般的な知識を測るMMLUのような業界標準テストと、50の社内Q&Aペアからなるカスタムテストセットを実行します。結果、ファインチューニングされたモデルは社内に関する質問でベースモデルを30%上回るパフォーマンスを示し、ファインチューニングに費やしたリソースを正当化しました。
AI搭載コンテンツ機能のコスト最適化
あるスタートアップが、ユーザー向けに記事を要約するAI機能を提供しています。ユーザーの増加が加速するにつれて、現在のハイエンドモデルAPIのコストが懸念事項となります。開発チームはモデル比較ツールを使用して、より安価で小規模なモデルを要約タスクでテストします。彼らは出力の品質、一貫性、長さを比較しながら、コスト分析ダッシュボードを監視します。その結果、わずか40%のコストで95%の品質を提供する、より小規模な蒸留モデルを発見し、利益率を大幅に改善しました。
マーケティング用画像生成モデルのA/Bテスト
マーケティングチームが、新しい広告キャンペーン用のビジュアルを生成する必要があります。彼らは、望む美的感覚を実現するためにMidjourney、Stable Diffusion、DALL-E 3のどれを使用すべきか確信が持てません。モデル比較ツールを使用して、同じ一連のクリエイティブなプロンプトを3つのモデルすべてに入力します。プラットフォームは出力を整理し、チームがブランドとの整合性、視覚的魅力、創造性に基づいて生成された画像を投票し、ランク付けできるようにします。この構造化されたプロセスにより、キャンペーンのスタイルに最も適しているのがStable Diffusionであることを迅速に特定できます。
モデルの能力に関する学術研究
大学の研究者が、最新のAIモデルの推論能力を研究しています。彼らはモデル比較プラットフォームのAPIを活用して、十数種類の異なるモデルで数千の論理パズルや数学の問題をプログラム的に実行します。このツールはテストを自動化し、結果を収集し、集計された正解率スコアを提供します。これにより、研究者は数百時間に及ぶ手動のスクリプト作成と実行の手間を省き、データの分析とモデルのパフォーマンストレンドに関する研究成果の発表に集中できます。
開発者ツール用のコード生成モデルの選択
IDEプラグインを開発している企業が、AIコード補完機能を追加したいと考えています。エンジニアリングリードは、GitHub Copilot(GPTベース)、Code Llama、その他の専門的なコーディングモデルの中から決定する必要があります。彼らはHumanEvalのようなベンチマークスイートを備えたモデル比較ツールを使用します。これにより、各モデルがさまざまなプログラミング言語で正確かつ効率的なコードスニペットを生成する能力を客観的に測定でき、ユーザーにとって最も信頼性が高くパフォーマンスの良いオプションを統合することが保証されます。