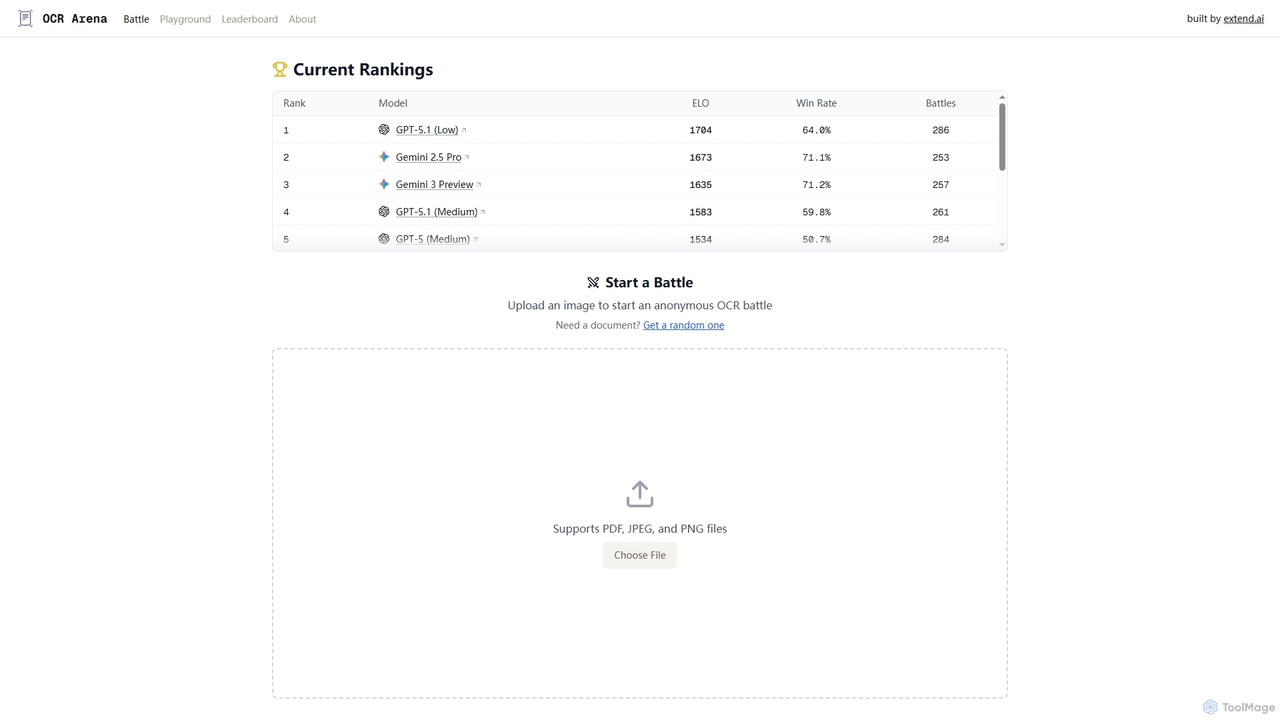
OCR Arena
OCR Arenaは、主要な基盤視覚言語モデル(VLM)およびオープンソースの光学文字認識(OCR)モデルをテストおよび評価するために設計された無料のオンラインプラットフォームです。ユーザーはドキュメントをアップロードし、精度を測定し、公開リーダーボードでモデルのパフォーマンスを比較できます。
OCR Arenaは、主要な基盤視覚言語モデル(VLM)およびオープンソースの光学文字認識(OCR)モデルをテストおよび評価するために設計された無料のオンラインプラットフォームです。ユーザーはドキュメントをアップロードし、精度を測定し、公開リーダーボードでモデルのパフォーマンスを比較できます。
モデル評価について
モデル評価ツールは、機械学習モデルの性能、品質、信頼性を厳密に評価するために設計されたAI駆動型プラットフォームです。これらのツールは、統計分析、性能指標、診断技術を活用し、モデルが未知のデータに対してどれだけ効果的に汎化するかを定量化します。その主な価値は、AIシステムが正確、公平、堅牢であり、実際の展開に備えていることを保証し、それによってリスクを最小限に抑え、運用効率を最大化することにあります。
コア機能
- 性能指標計算:精度、適合率、再現率、F1スコア、MSE、AUC-ROCなど、さまざまなモデルタイプの主要指標を自動的に計算します。
- バイアス検出と公平性分析:モデル内の潜在的なバイアスを特定し定量化し、異なる人口統計グループ間で公平な結果を保証します。
- エラー分析とデバッグ:モデルのパフォーマンスが低い特定のデータポイントやシナリオを特定し、的を絞ったモデル改善を支援します。
- モデル比較と選択:複数のモデルバージョンやアルゴリズムを並べて比較し、最適なパフォーマンスを発揮するものを特定します。
- データドリフトと異常検出:展開されたモデルのデータ分布の変化や時間の経過に伴うパフォーマンスの低下を監視します。
ユースケース
データサイエンティストや機械学習エンジニアは、これらのツールを使用して、本番環境に展開する前に新しいモデルのイテレーションを検証し、事前定義された性能ベンチマークを満たしていることを確認します。AIプロダクトマネージャーは、新機能のモデル候補を比較するためにこれらを活用し、モデル選択に関するデータ駆動型の意思決定を行います。研究者もまた、新しいAIアルゴリズムの堅牢性と汎化能力を厳密に評価するためにモデル評価プラットフォームを利用します。
選択のポイント
モデル評価ツールを選択する際は、既存の機械学習フレームワークやサポートされているモデルタイプ(例:TensorFlow、PyTorch)との互換性を考慮してください。提供される評価指標の範囲、特にNLPやコンピュータビジョンなどの特定のタスク向けの指標を評価します。強力な解釈可能性と説明可能性機能を備えたツールを優先し、シームレスなワークフローのためにMLOpsパイプラインとの統合機能を評価します。大規模なデータセットを処理するためのスケーラビリティも重要な要素です。
モデル評価利用シーン
新しい機械学習モデルの検証
データサイエンティストは、デプロイ前に新しく開発された機械学習モデルを厳密にテストするためにモデル評価ツールを利用します。これには、未見のデータに対する精度、適合率、再現率などの性能指標の計算、潜在的な過学習または未学習の特定、およびモデルが事前定義された性能ベンチマークを満たしていることの確認が含まれます。このプロセスにより、信頼性の低いモデルのデプロイに関連するリスクが最小限に抑えられ、本番環境での堅牢な性能が保証されます。
新しい機械学習モデルの検証
データサイエンティストは、新しく開発された機械学習モデルを本番環境に展開する前に、厳密にテストし検証します。モデル評価ツールを使用することで、包括的なテストを実行し、未知のデータに対する精度やF1スコアなどの性能指標を計算し、モデルがすべての性能ベンチマークと品質基準を満たしていることを確認し、ライブシステムでの高価なエラーを防ぎます。
デプロイされたAIシステムのドリフト監視
MLOpsエンジニアは、本番環境にデプロイされたAIモデルのパフォーマンスを継続的に監視するためにモデル評価ツールを使用します。これらのツールは、時間の経過とともにモデルの精度を低下させる可能性のあるデータドリフト(入力データ分布の変化)とコンセプトドリフト(入力変数とターゲット変数の関係の変化)を検出します。重大なドリフトに対するアラートを設定することで、チームは積極的にモデルを再トレーニングまたは更新し、最適なパフォーマンスを維持し、実際のアプリケーションでのコストのかかるエラーを防ぐことができます。
AIシステムにおけるモデルバイアスの検出
AI倫理学者やデータサイエンティストは、これらのツールを使用して、特に信用スコアリングや採用などの機密性の高いアプリケーションで使用されるAIモデル内の潜在的なバイアスを特定し定量化します。これらのツールは、異なる人口統計グループ間でのモデルの動作を分析し、公平性を確保し、差別的な結果を防ぐのに役立ち、倫理的なAI展開と規制遵守にとって不可欠です。
AIの公平性の確保とバイアスの軽減
組織は、採用、融資、医療などの機密性の高いアプリケーションにおいて、AIモデルのバイアスを特定し、軽減するためにモデル評価ツールを使用します。これらのツールは、異なる人口統計グループ(例:年齢、性別、民族)におけるモデル予測を分析し、不公平な結果を検出します。公平性指標を定量化し、格差を視覚化することで、データ倫理学者や開発者はモデルを改善し、公平な意思決定を促進し、倫理的なAIガイドラインを遵守し、国民の信頼を築くことができます。
深層学習のハイパーパラメータの最適化
機械学習エンジニアは、モデル評価プラットフォームを利用して、深層学習モデルのパフォーマンスに対するさまざまなハイパーパラメータ構成の影響を体系的に評価します。検証損失や精度などの指標を比較しながら実験を実行することで、最高のパフォーマンスを発揮し、最も堅牢なモデルにつながる最適なハイパーパラメータのセットを特定し、開発効率を大幅に向上させます。
モデル性能のデバッグと改善
AI開発者は、モデル評価ツールを活用してモデルをデバッグし、反復的に改善します。解釈可能性機能(XAI)は、どの特徴がモデルの予測に最も貢献しているか、またはモデルがなぜ特定の誤りを犯したかを理解するのに役立ちます。弱点や改善点を特定することで、開発者はモデルアーキテクチャを洗練させ、ハイパーパラメータを調整したり、トレーニングデータを増強したりして、より正確で効率的なAIソリューションを実現できます。
展開されたモデルのパフォーマンスドリフトの監視
MLOpsチームは、モデル評価ツールを本番パイプラインに統合し、展開されたAIモデルのパフォーマンスを継続的に監視します。これらのツールは、時間の経過とともに主要な指標を追跡し、データドリフトやコンセプトドリフトを検出し、モデルの精度や信頼性の低下をチームに警告します。このプロアクティブな監視により、モデルは動的な実世界の環境で効果的かつ関連性を保ちます。
AIアルゴリズムのベンチマークと比較
研究者やデータサイエンスチームは、異なるAIアルゴリズムやモデルバージョンを相互にベンチマークするためにモデル評価ツールを使用します。一貫した評価指標とデータセットを適用することで、さまざまなアプローチの長所と短所を客観的に比較できます。これは、特定のタスクに最適なモデルを選択し、リソース配分を最適化し、AIの研究開発における最先端技術を進歩させるために不可欠です。
複数のAIアルゴリズム候補の比較
研究者や開発チームは、モデル評価ツールを使用して、特定の課題に対する異なるAIアルゴリズムやモデルアーキテクチャの長所と短所を客観的に比較します。評価指標とデータセットを標準化することで、どの手法が優れた結果をもたらすかについて情報に基づいた意思決定を行うことができ、研究開発サイクルを加速させます。
AIモデルの規制遵守の確保
金融やヘルスケアなど、厳格な規制がある業界では、AIモデルが法的および倫理的基準に準拠していることを確認するためにモデル評価ツールに依存しています。これらのツールは、モデルの性能、公平性、透明性に関する監査可能なレポートを提供し、これは規制機関によってしばしば要求されます。評価結果を体系的に文書化することで、組織はデューデリジェンスを実証し、罰則を回避し、利害関係者や顧客との信頼を築くことができます。
AIモデルの規制遵守の確保
コンプライアンス担当者や法務チームは、モデル評価ツールを活用して、AIモデルが業界固有の規制、公平性ガイドライン、透明性要件に準拠していることを確認します。これらのツールは、モデルのパフォーマンス、バイアス分析、説明可能性に関する監査可能なレポートを提供し、組織がコンプライアンスを実証し、利害関係者や規制当局との信頼を築くのに役立ちます。